pip install jupyter_contrib_nbextensions
jupyter contrib nbextensions install --user
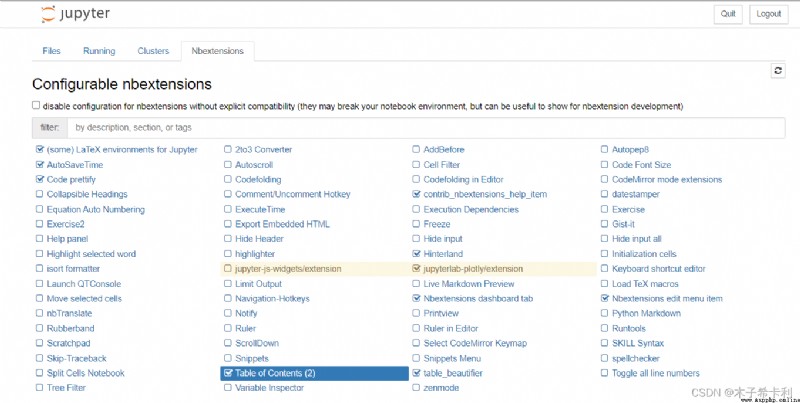
安裝插件管理模塊

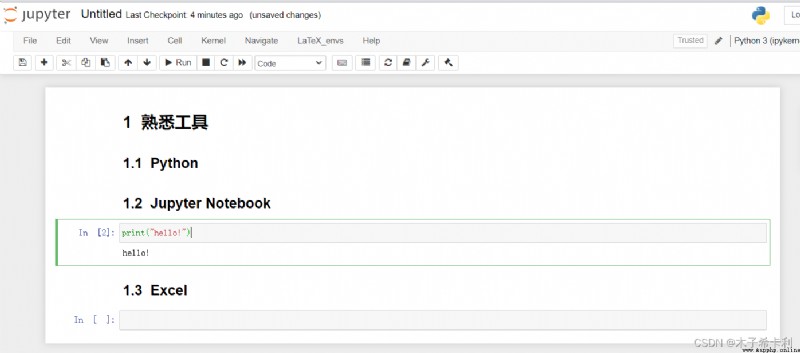
打開Anaconda Prompt,輸入
jupyter notebook --generate-config #獲取系統配置文件目錄
進入對應文件夾找到配置文件目錄,進入並修改
"anoconda\Lib\site-packages\notebook\static\components\codemirror\lib\codemirror.css"
import pandas as pd
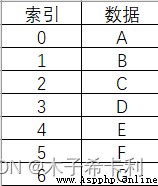
Series是Pabdas中一種類似一維列表的對象。
它由一個索引和一個數據組成。
在Excel中類似以下效果:
pd.Series(
data=None,
index=None,
dtype: 'Dtype | None' = None,
name=None,
copy: 'bool' = False,
)
data需要傳入一個序列類型的對象(列表、元組、字典等)index可以傳入一個由索引名組成的列表dtype可以設置數據類型name可以給Series對象設置一個別名copy設置是否復制data常見的如:
names=pd.Series(["趙","錢","孫","李","孫","王","鄭","王"]) #傳入列表
print(names) #索引默認從0開始
""" 0 趙 1 錢 2 孫 3 李 4 孫 5 王 6 鄭 7 王 dtype: object """
names=pd.Series(["趙","錢","孫","李","孫","王","鄭","王"],[1,2,3,4,5,6,7,8]) #指定索引
print(names)
""" 1 趙 2 錢 3 孫 4 李 5 孫 6 王 7 鄭 8 王 dtype: object """
grades=pd.Series({
"第一名":"張三","第二名":"李四","第三名":"王二麻子"}) #傳入字典
print(grades) #key為索引,value為數據
""" 第一名 張三 第二名 李四 第三名 王二麻子 dtype: object """
series_obj.index
Series對象series_obj的全部索引。Index類型的對象如:
names_index = names.index
print(names_index)
# Int64Index([1, 2, 3, 4, 5, 6, 7, 8], dtype='int64')
grades_index = grades.index
print(grades_index)
# Index(['第一名', '第二名', '第三名'], dtype='object')
series_obj.values
對象series_obj`的全部數據。numpy.ndarray類型的對象如:
names_values = names.values
print(names_values)
# ['趙' '錢' '孫' '李' '孫' '王' '鄭' '王']
grades_values = grades.values
print(grades_values)
# ['張三' '李四' '王二麻子']
DataFrame是Pabdas中一種類似表格的對象。
它由一對索引(行索引和列索引)和一組數據組成。
在Excel中類似以下效果: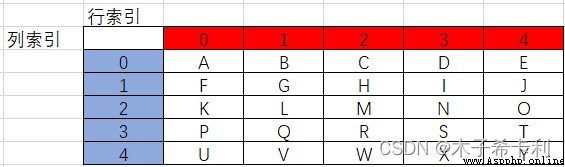
pd.DataFrame(
data=None,
index: 'Axes | None' = None,
columns: 'Axes | None' = None,
dtype: 'Dtype | None' = None,
copy: 'bool | None' = None,
)
data需要傳入一個序列類型的對象(列表、元組、字典等),多為二維index設置行索引columns設置列索引dtype設置數據類型copy設置是否復制data如:
df1=pd.DataFrame(["a","b","c","d"])
print(df1) #一維也會自動設置行列索引,從0開始
""" 0 0 a 1 b 2 c 3 d """
df2=pd.DataFrame([["a","A"],["b","B"],["c","C"],["d","D"]])
print(df2) # 二維列表,內層列表是每行
""" 0 1 0 a A 1 b B 2 c C 3 d D """
df3=pd.DataFrame([["a","A"],["b","B"],["c","C"],["d","D"]],index=[1,2,3,4],columns=["lower","upper"])
print(df3) # index設置行索引,columns設置列索引
""" lower upper 1 a A 2 b B 3 c C 4 d D """
df4=pd.DataFrame({
"lower":["a","b","c","d"],"upper":["A","B","C","D"]},index=[1,2,3,4])
print(df4) # 字典的key是列索引,value是每列,行索引可以通過index另外設置
""" lower upper 1 a A 2 b B 3 c C 4 d D """
df_obj.index # 獲取所有行索引
df_obj.columns # 獲取所有列索引
Index類型的對象如:
df4_index=df4.index
print(df4_index)
# Int64Index([1, 2, 3, 4], dtype='int64')
df4_columns=df4.columns
print(df4.columns)
# Index(['lower', 'upper'], dtype='object')
第六章討論
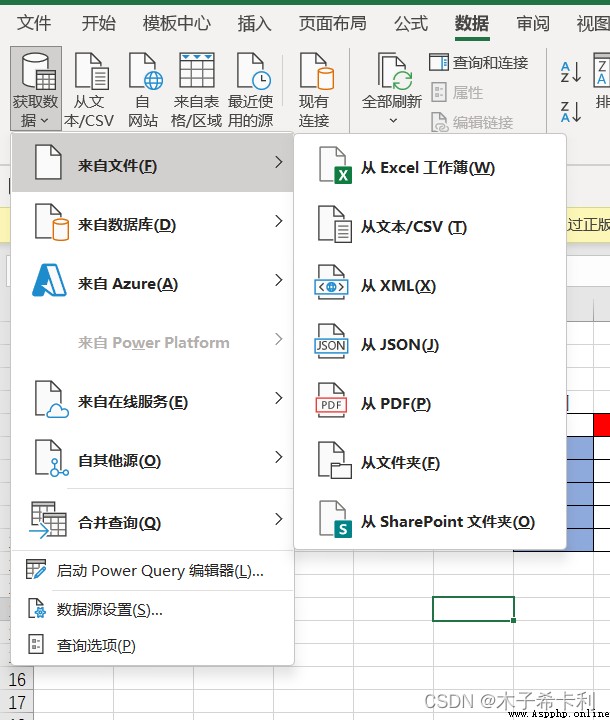
xlsl文件是Excel表格文件。對應Excel"來自文件"的"從Excel工作簿"
pd.read_excel(
io,
sheet_name: 'str | int | list[IntStrT] | None' = 0,
header: 'int | Sequence[int] | None' = 0,
names=None,
index_col: 'int | Sequence[int] | None' = None,
usecols=None,
dtype: 'DtypeArg | None' = None,
nrows: 'int | None' = None
)
io設置導入的xlsl文件的路徑sheet_name設置需要導入的sheet,可以用sheet名字符串,也可以傳入數字(從0開始),默認第一張。header設置使用哪一行作為列索引。默認以第一行作為列索引。可以傳入數字(從0開始)。names設置列索引。先要設置header=None禁用表中的行作為列索引。可以傳入列表來指定列索引。index_col設置使用哪一列來作為行索引。可以傳入數字(從0開始)。usecols 設置導入哪幾列數據。可以傳入數字組成的列表類數據(從0開始)。dtype 設置每一列的數據類型。可以傳入字典。key是列索引,value是數據類型。nrows設置顯示前幾行數據。DataFrame對象如:
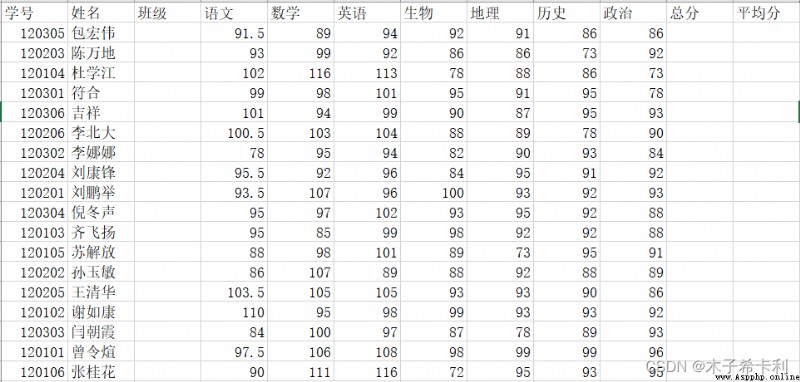
grades_df=pd.read_excel("./files/學生成績單.xlsx",
sheet_name="第一學期期末成績",
index_col=1,
usecols=[0,1,3,4,5,6,7,8,9],
nrows=5)
print(grades_df)
""" 學號 語文 數學 英語 生物 地理 歷史 政治 姓名 包宏偉 120305 91.5 89 94 92 91 86 86 陳萬地 120203 93.0 99 92 86 86 73 92 杜學江 120104 102.0 116 113 78 88 86 73 符合 120301 99.0 98 101 95 91 95 78 吉祥 120306 101.0 94 99 90 87 95 93 """
逗號分隔值(Comma-Separated Values,CSV,有時也稱為字符分隔值,因為分隔字符也可以不是逗號),其文件以純文本形式存儲表格數據。
pd.read_csv(
filepath_or_buffer: 'FilePath | ReadCsvBuffer[bytes] | ReadCsvBuffer[str]',
delimiter=None,
header='infer',
names=<no_default>,
index_col=None,
usecols=None,
dtype: 'DtypeArg | None' = None,
engine: 'CSVEngine | None' = None,
nrows=None,
encoding=None,
)
filepath_or_buffer設置csv文件路徑delimiter設置數據間的分隔符(默認為逗號)header、names、index_col、usecols、dtype、nrows同read_excel()方法engine指定解析引擎,路徑中有中文時,可嘗試傳入engine=pythonencoding指定csv編碼格式,常見的有gbk或utf-8DataFrame對象如:
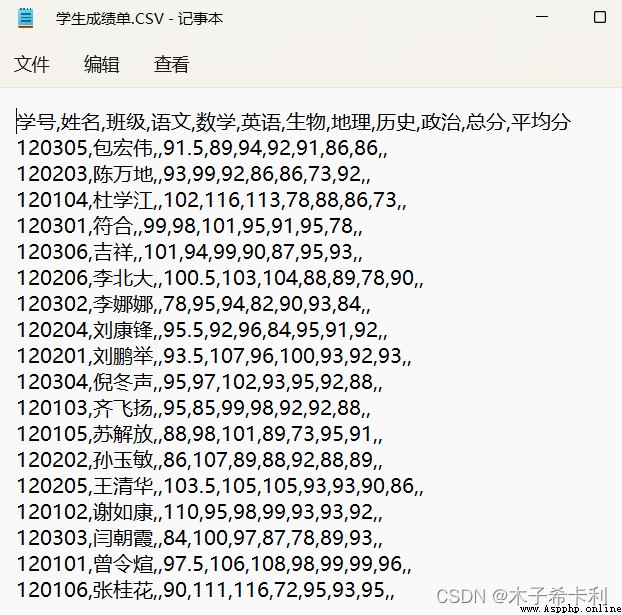
grades_df=pd.read_csv("./files/學生成績單.CSV",
index_col=1,
engine="python",
usecols=[0,1,3,4,5,6,7,8,9],
nrows=5,
encoding="gbk"
)
print(grades_df)
""" 學號 語文 數學 英語 生物 地理 歷史 政治 姓名 包宏偉 120305 91.5 89 94 92 91 86 86 陳萬地 120203 93.0 99 92 86 86 73 92 杜學江 120104 102.0 116 113 78 88 86 73 符合 120301 99.0 98 101 95 91 95 78 吉祥 120306 101.0 94 99 90 87 95 93 """
txt文件就是普通的文本文件
pd.read_table(
filepath_or_buffer: 'FilePath | ReadCsvBuffer[bytes] | ReadCsvBuffer[str]',
delimiter=None,
header='infer',
names=<no_default>,
index_col=None,
usecols=None,
dtype: 'DtypeArg | None' = None,
engine: 'CSVEngine | None' = None,
nrows=None,
encoding=None,
)
同read_csv,只不過delimiter沒有默認值,需要用戶指定。
返回一個DataFrame對象
也可以讀取csv文件。
rades_df=pd.read_csv("./files/學生成績單.txt",
delimiter=",",
index_col=1,
engine="python",
usecols=[0,1,3,4,5,6,7,8,9],
nrows=5,
encoding="gbk")
print(grades_df)
""" 學號 語文 數學 英語 生物 地理 歷史 政治 姓名 包宏偉 120305 91.5 89 94 92 91 86 86 陳萬地 120203 93.0 99 92 86 86 73 92 杜學江 120104 102.0 116 113 78 88 86 73 符合 120301 99.0 98 101 95 91 95 78 吉祥 120306 101.0 94 99 90 87 95 93 """
使用pymysql模塊連接數據庫並導入數據表
import pymysql
con=pymysql.connect(host="localhost",
port=3306,
user="root",
password="123",
database="pdd",
charset="utf8")
pd.read_sql(sql,
con,
index_col: 'str | Sequence[str] | None' = None,
columns=None)
sql為SQL語句,con是與數據庫建立的連接對象
index_col指定作為行索引的列。
返回一個DataFrame對象
如:
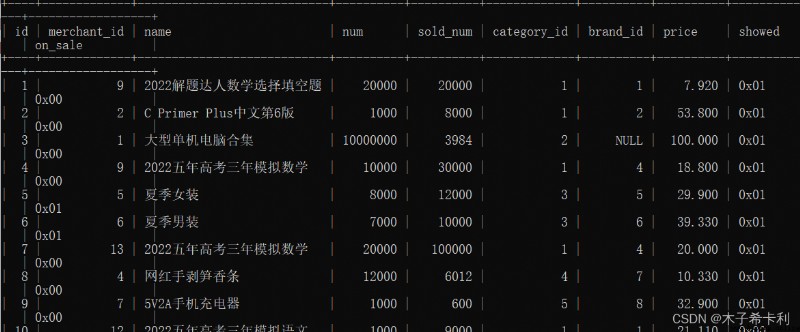
import pymysql
con=pymysql.connect(host="localhost",
port=3306,
user="root",
password="123",
database="pdd",
charset="utf8")
goods=pd.read_sql("select id,name,price from goods;",con,index_col="id")
print(goods)
""" name price id 1 2022解題達人數學選擇填空題 7.92 2 C Primer Plus中文第6版 53.80 3 大型單機電腦合集 100.00 4 2022五年高考三年模擬數學 18.80 5 夏季女裝 29.90 """
主要通過pd.DataFrame創建。
Excel會直接把所有數據顯示。
df_obj.head(n)
n代表顯示前n行如:
print(goods.head(5))
""" name price id 1 2022解題達人數學選擇填空題 7.92 2 C Primer Plus中文第6版 53.80 3 大型單機電腦合集 100.00 4 2022五年高考三年模擬數學 18.80 5 夏季女裝 29.90 """
print(goods.head(3))
""" name price id 1 2022解題達人數學選擇填空題 7.92 2 C Primer Plus中文第6版 53.80 3 大型單機電腦合集 100.00 """
選中某行看列數,選中某列看列數,選中某區域看個數。


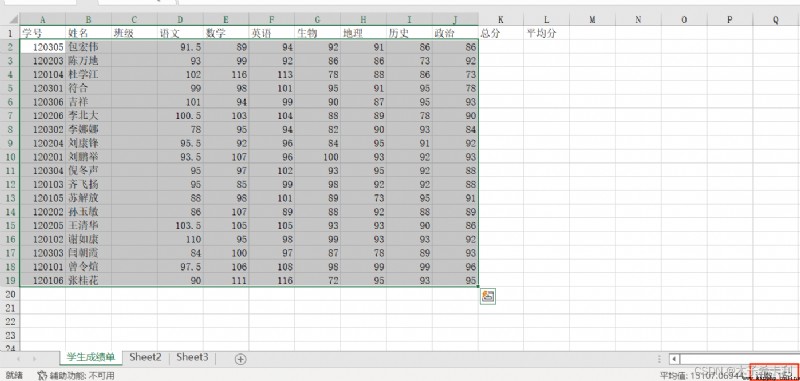
df_obj.shape
如:
grades_df = pd.read_excel("./files/學生成績單.xlsx",
sheet_name="第一學期期末成績",
index_col=1)
print(grades_df)
""" 學號 班級 語文 數學 英語 生物 地理 歷史 政治 總分 平均分 姓名 包宏偉 120305 NaN 91.5 89 94 92 91 86 86 NaN NaN 陳萬地 120203 NaN 93.0 99 92 86 86 73 92 NaN NaN 杜學江 120104 NaN 102.0 116 113 78 88 86 73 NaN NaN 符合 120301 NaN 99.0 98 101 95 91 95 78 NaN NaN 吉祥 120306 NaN 101.0 94 99 90 87 95 93 NaN NaN 李北大 120206 NaN 100.5 103 104 88 89 78 90 NaN NaN 李娜娜 120302 NaN 78.0 95 94 82 90 93 84 NaN NaN 劉康鋒 120204 NaN 95.5 92 96 84 95 91 92 NaN NaN 劉鵬舉 120201 NaN 93.5 107 96 100 93 92 93 NaN NaN 倪冬聲 120304 NaN 95.0 97 102 93 95 92 88 NaN NaN 齊飛揚 120103 NaN 95.0 85 99 98 92 92 88 NaN NaN 蘇解放 120105 NaN 88.0 98 101 89 73 95 91 NaN NaN 孫玉敏 120202 NaN 86.0 107 89 88 92 88 89 NaN NaN 王清華 120205 NaN 103.5 105 105 93 93 90 86 NaN NaN 謝如康 120102 NaN 110.0 95 98 99 93 93 92 NaN NaN 闫朝霞 120303 NaN 84.0 100 97 87 78 89 93 NaN NaN 曾令煊 120101 NaN 97.5 106 108 98 99 99 96 NaN NaN 張桂花 120106 NaN 90.0 111 116 72 95 93 95 NaN NaN """
print(grades_df.shape)
# (18, 11)
選中想要查看的數據列,在"數字"欄查看。
df_obj.info()
df_obj的基本信息,如行索引Index,列索引Data volumns ,每列的非空值個數和數據類型如:
grades_df.info()
""" <class 'pandas.core.frame.DataFrame'> Index: 18 entries, 包宏偉 to 張桂花 Data columns (total 11 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 學號 18 non-null int64 1 班級 0 non-null float64 2 語文 18 non-null float64 3 數學 18 non-null int64 4 英語 18 non-null int64 5 生物 18 non-null int64 6 地理 18 non-null int64 7 歷史 18 non-null int64 8 政治 18 non-null int64 9 總分 0 non-null float64 10 平均分 0 non-null float64 dtypes: float64(4), int64(7) memory usage: 1.7+ KB """
選中某一列,可以看到數據的平均值、總個數、和
df_obj.describe()
df_obj的各列的信息。如總個數(count),平均值(count),標准差(std),最小值(min),下四分位數(25%),中位數(50%),上四分位數(75%),最大值(max)如:
grades_df.describe()
""" 學號 班級 語文 數學 英語 生物 \ count 18.000000 0.0 18.000000 18.000000 18.000000 18.000000 mean 120203.500000 NaN 94.611111 99.833333 100.222222 89.555556 std 84.035182 NaN 7.729918 7.890799 7.025630 7.492916 min 120101.000000 NaN 78.000000 85.000000 89.000000 72.000000 25% 120105.250000 NaN 90.375000 95.000000 96.000000 86.250000 50% 120203.500000 NaN 95.000000 98.500000 99.000000 89.500000 75% 120301.750000 NaN 100.125000 105.750000 103.500000 94.500000 max 120306.000000 NaN 110.000000 116.000000 116.000000 100.000000 地理 歷史 政治 總分 平均分 count 18.000000 18.000000 18.000000 0.0 0.0 mean 90.000000 90.000000 88.833333 NaN NaN std 6.211943 6.259111 5.873670 NaN NaN min 73.000000 73.000000 73.000000 NaN NaN 25% 88.250000 88.250000 86.500000 NaN NaN 50% 91.500000 92.000000 90.500000 NaN NaN 75% 93.000000 93.000000 92.750000 NaN NaN max 99.000000 99.000000 96.000000 NaN NaN """