To do a q&a system,根據輸入的內容,提出的問題,得到一個答案.See below detailed data set is introduced.
Early use of data set is in English,Because less data set in Chinese,And training data quantity is too small.使用的是Facebook 的公共數據The (20) QA bAbI tasks,官方下載鏈接如下:https://research.fb.com/downloads/babi/
此數據集包含20個任務,Each task similar but slightly different.每種任務包含10,000How to question and answer to,Each question can be divided into three parts:內容、問題和答案.Content can be a sentence、A few sentences or a paragraph in an article.Question is a sentence.The answer is a word or a phrase,And the answer must be in in the content of.The following is a sample data set a form:
The input is three sentences,Question is a sentence,The answer is a word.The answer in most cases is not based on directly produce a sentence,But need to each other through multiple sentences priori.Above is the most simple question and answer to,內容只有2句,The content of the some tasks may be up to80句,Higher request to the model of reasoning.The vast differences in the degree of difficulty of logical reasoning and,Some need reasoning only once,Mutual inference sentence spacing is very small,Some questions and answers on the answer need reasoning according to the multiple sentence,Interval between sentence and sentence is very big,So how to capture the relationship between sentences,And keep effective information is a difficulty.(數字1Called support sentence number,That is, the answer is based on what the numbered sentences in order of reasoning out,The model will not use to this part of information.)The following is a difficult case:
The visible input obviously increase the number of sentences,Need reasoning between sentences,And reasoning of sentence between multiple invalid sentence.
Model design ideas from many papers,鏈接和介紹如下:
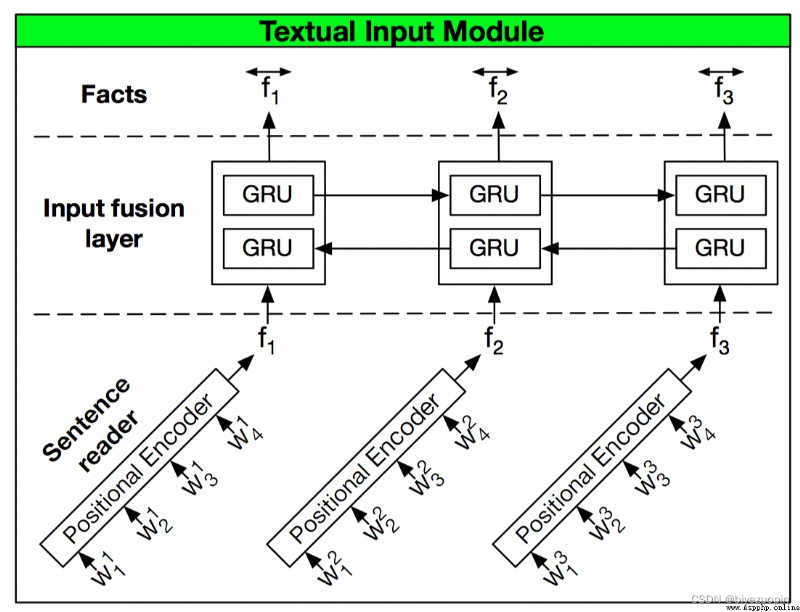
DMNAs the basic model for this model,Since the changes are based on the.以下詳細介紹Dynamic Memory Network (DMN) 模型:
DMN由4部分組成,Named input module(Input Module),問題模塊(Question Module),Episodic memory module(Episodic Memory Module),回答模塊(Answer Module)
Before the introduction model,先對RNNs做基本的介紹,熟悉可跳過:
RNNEach layer of network nodes have seen as a connection neural network.On the previous information memory and applied to the current output calculation,That on a layer of the output of the hidden layer as part of the current input of hidden layers on the,You could suggest that the current state of the hidden layer and output contains all previous term vector information.
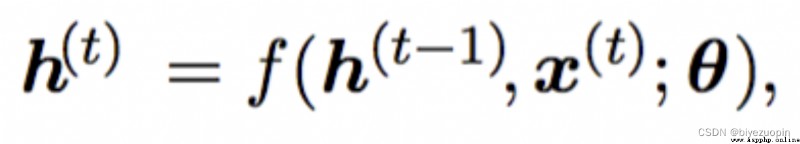
According to the current output of hidden layers on the,h(t-1)The output of hidden layers on the said in a moment,x(t)Said word input vector of the current time(On behalf of the current word word vector),For the function parameters needed to(為矩陣).可以理解為h(t)Contains all the words in front of the information.The specific calculation process is shown in the following type:
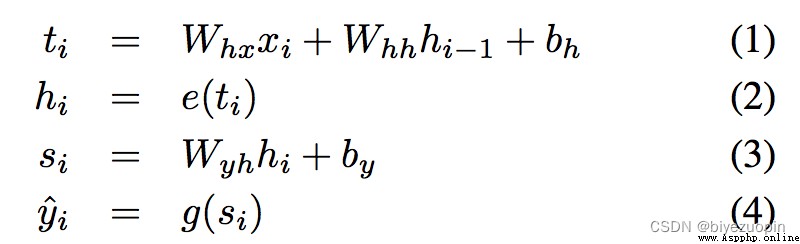
Whx , Whh , Wyh , bh , by就是之前的,Represent the three weights and bias parameters.e和gOn behalf of the predefined nonlinear function.
GRU為RNN的改進版,能夠解決梯度消失的問題,So can better preserve input information.
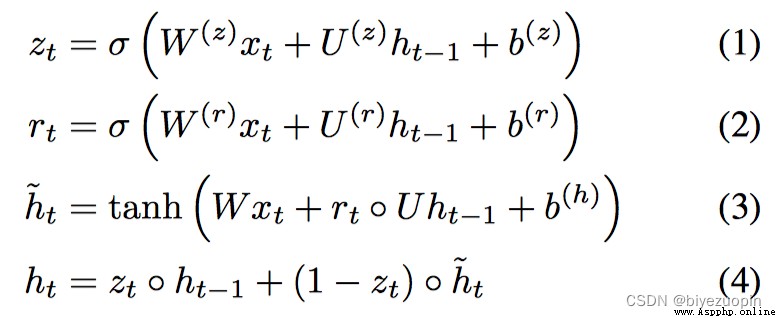
上式為GRU的計算公式,相比於傳統的RNN,The output of hidden layers added two parameters to calculate thezt , rt ,Represent the update door(Update Gate)和重置門(Reset Gate)以及
tHow big is the importance of.除此之外,GRU不存在memory的概念,But the moment on the simple state of hidden all used as input of the current time.
由此可見,GRUStructure by updating the door and reset the door to the next layer of network weights to control,The structure than traditionalRNN更復雜,Thus can better solve the problem of long sentences information disappear.而LSTM相比於GRUAnother layer of control:Set a parameter controls the hidden layers on the condition of a point in time on impact on the current state of the hidden layer weights.
除此之外,Also introduced the two-wayRNN的結構.The situation of the said above,The current state of hidden layer before only hide,Understandable for backward propagation before.The spread of two-way structure introduced by forward after,Make the current state of hidden layer is not only affected by before,Also under the influence of future time,Make the spread of information more fully.此外,RNNCan also be set to multilayer structure,According to the need to take the last layer of status, or to the state of each layer of the weighted the last hidden layer state.
Work is the input text(In this data set is a collection of multiple sentence)Converted to vector expression.
Now, every sentence is composed of several words,The first to use word embedded layer(Word Embedding)Put the words into a two-dimensional tensor(Tensor,GPUA data structure calculations support,可以理解為list.)Assumes that the word number for8,Word embedded layer dimensions specified term vectors as80,The sentences in word embedded as the output layer after 8 * 80的二維Tensor.(Temporary not consider at this timeBatch Size的使用,This step is to speed up the training process.若使用,輸出為Batch size * 8 * 80的三維Tensor)Then put the 2 dTensor輸入Recurrent Neural Network (RNN),目前有多種RNN結構的變體,比如常見的LSTM,GRU等.LSTMThe structure of theGRU復雜,DMNThe author proves that usingGRU能夠得到和LSTM相近的效果,So using one-wayGRU即可.
因此,The output of the input module isGRU的輸出,在不考慮batch size的情況下,When the input is a word,The output is a 2 dTensor,Which retained a summary of all the words in the sentences information.When the input sentence is more than one sentence,First to multiple sentences for Mosaic,At the end of each sentence end increase other identifier,The final output identifier of the hidden layer state joining together.The following analysis usingbatch size時Tensor的維度:
In the process of training to introducebatch sizeIs to speed up the calculation,Multiple answers to each training for,Therefore usually introducebatch size.因為GRU的輸入為Tensor格式,So to the number of sentences and sentences of different length of differentbatch需要進行padding,Typically fill behind the effective information0.
假設batch size為2,詞向量維度為80,padding後每個contextsThe most number of sentences as6.那麼GRU的輸入是:On behalf of the content of the input2 * 6 * 80的tensorAnd on behalf of the initial hidden layers2 * 2 * 80 Tensor,The second dimension2Because of the bidirectionalGRU.GRUThe output is also two parts,分別代表cell和hidden.Cell Store every timeGRUIteration of the hidden layer state,維度為2 * 6 * 160,The third dimension because of considering the two-wayGRU.hiddenOn behalf of the last hidden layer state,維度為 2 * 2 * 80,The second dimension because of considering the two-wayGRU.我們把cell分成兩個2 * 6 * 80的tensorAdd the last input module output.
Module is the feature of input can only be a sentence,The structure and the input module is the same,Is input module number for a sentence.Problem of the output of the module is also used asEpisodic Memory Module中memory的初始狀態.對應的Tensor維度為 1 * 2 * 80 (句子個數batch size詞向量維度)

把Episodic Memory Module的輸出和Question ModuleThe output of the spliced into 2*160的Tensor.Using cross entropy loss function asloss進行反向傳播訓練.To predict the probability of each word in the dictionary,The maximum probability of the word as a result.
The above is the base model of the question answering system,General process available below said.
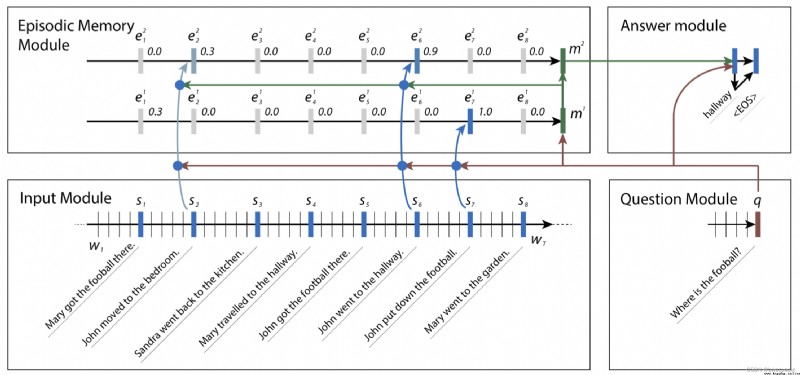
可見Input ModuleEach sentence intoS1至S8The vector and intoEpisodic Memory Module,結合Question ModuleThe vector form of input,Continuous self iterative update the weight of each sentence,Ignore the weight value is close to0的句子,The last focusS2和S6.The last generation ofmemory作為Answer ModuleThe input to generate the answer.
DMNModel in a variety of problems in the actual performance.首先,其Input ModuleUSES a one-wayGRU,Every moment state of hidden layer contains sentences before(單詞)的總結,But there was no consideration behind sentences information.此外,When a long number many sentences or sentence,Let the last time the hidden state contains all the sentences in front of the(單詞)The information is very difficult,Easy to cause the problem of missing information.因此需要對Input Module改進.其次,在Attention Mechanism中計算GRU的update gate zt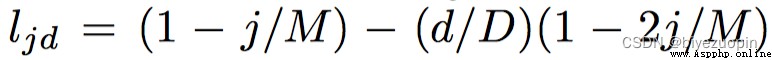
Effect on the current state of hidden layer)時,Consider only the moment from the last hidden layer and the impact of the current input,Before did not consider problems andmemory可能帶來的影響.最後,在Memory Update Mechanism中,Before is according to the output of the input modulect,A moment of hidden layer stateht-1作為GRUMoment of input to update the current state of hidden layers on the.This means that each iteration the state of the hidden layer weights is the same,這樣的模型被稱為tied model,Performance limitations.
對於Input Module的改進:
First introduced a called location coding(positional encoding)的結構,From the word level before the code into sentence level of code.Because the problem is always associated with the sentence,At the sentence level modeling appears more reasonable.相當於用positional encoding代替之前的GRU結構,On the one hand, reduces the amount of calculation,On the other hand to capture the relationship between word position again.Specific approach is vector of each word in the sentence word according to its location multiplied by a weight,Finally all the word vector addition formTensorRepresentative of the whole sentence information summarized.positional encoding的計算規則(The word weight vector)如下:
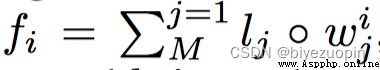
ljd為M*D的二維列表,MSay the sentences in a quiz on the number of,DSaid one of the longest word in the sentence number.此外jThe index for sentence,dFor the word in the sentence the index of the.Then the 2 d vector dot product list and word,For each word in the sentence and vector sum aspositional encoding結構的輸出.
得到的Tensor維度應為 句子個數*詞向量維度.
在此之後,引入Input Fusion LayerCan make sentences between information interaction,Is essentially a two-wayGRU.
Input Fusion LayerActually do is take onecontextThe multiple sentences in turn into the two-wayGRU,Each time the state joining together as the output of hidden layers on the.Ensure that the dimension of the input and output not change.
對Attention Mechanism的改進:
首先我們改變z函數,之前的zFunction consists of the following six parts,
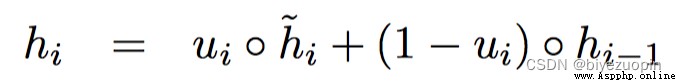
但是實驗發現,Just keep the following four parts,
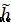
On the basis of reduce amount of calculation to obtain the approximate accuracy.
其次,改變Attention Mechanism中GRU的結構,得到名為Attention Based GRU結構.GRUThe calculation formula for the current state of the hidden layer as follows:
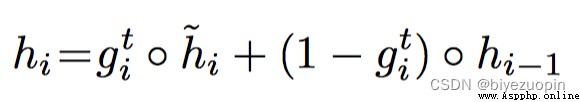
可見ht-1是update gate ui , A moment of hidden layer state hi-1 And representatives of the current state of the input and hidden at a moment in summarizing the function of.
Attention Based GRUThe calculation formula for the current state of the hidden layer as follows:

唯一的區別是用attention gate gti替換update gate ui,gti為Attention Mechanism的輸出,On behalf of the weight of each sentence(即重要程度),其中還包含了question的信息.
對Memory Update Mechanism的改進:
用RELU函數代替GRU對Memory進行更新:
其中的Memory mt在GRUStructure ist時刻的隱藏層狀態.c和qFor the input and output module the problem.通過這樣的改變,Can lead to accurate0.5%的提升.
The update in is rightInput Module的Positional Encoding.我們使用TreeLSTM代替Positional Encoding.原因是Positional EncodingAlthough location information contains the word,但是TreeLSTMTo preserve the dependent relationships between words.理論上,The information contained in the last hidden layer more.
首先介紹TreeLSTM結構,TreeLSTMIs based on tree structure usingLSTM,Starting from the leaf node iterated,Finally, the root node of the hidden states as a whole sentence summary.如果我們把TreeLSTM定義為一個類,So its input is representative of executive function tree object of a sentence and represent the term vectors of each word formTensor. We need to get visible on behalf of the tree structure of the sentence.在這裡使用的是 The Stanford Parser, Introduction and the download path is as follows:
https://nlp.stanford.edu/software/lex-parser.shtml
It is able to put a sentence parsing asDependency Tree(依存樹) 或者 constituency Tree (組成樹).To rely on the tree,Each tree node is a word,According to the article mentioned at the beginning of the paperDependency Parser ,It depends on the neural network dependencies before finding words and words,Each child node must be and the most strongly linked to the node word a few words,The last contact with strong word as a phrase to form a child tree.舉個很簡單的例子 I eat food. The final dependent the root node foreat,I 和 food 分別為eat 的兩個孩子.Finally using the tree represents a whole sentence,需要注意的是,Each node is not a fixed number of children.For component tree,Its each leaf node is the word in this sentence,So leaf node number is the number of words in a sentence.Each of the leaf nodes represent more words phrases,The end result is a binary tree class.還是用上面的例子,The final tree structure is:I eat food .This phrase represents the root node(稱為結點0),其左孩子是I eat food (稱為結點1)右孩子是 . (稱為結點2).對於結點1而言,其左孩子為 I (稱為結點3),右孩子為 eat food (稱為結點4).而結點4The two children are eat 和 food.在這裡,We use the dependency tree as aTreeLSTM的樹結構.
此時TreeLSTMSelf iteration where no longer rely on words in the sentence,Iteration of the current time is the child nodes of the output as input.那麼最後rootNot only contains the information of each word in the sentence,The structural relationships will also be able to capture the words before information.
By the final experiment proved that,In most tasks,On the test set of the model accuracy is better than a model test set accuracy.But on the individual tasks(task3, task16),The model of training training accuracy is better than a model.
Another problem is that at this time the slow training speed,For each sentence usingTreeLSTMIterative structure,Every time can only to a sentence iteration,沒有實現batch size.The next model update implement.
This part is mainly completed by Chen Qiao are.
在TreeLSTM-DMN+On the basis of the introduction of batch processing technology,使得訓練速度加快,But in theory will not change the model on the test set accuracy.我們根據其contextsThe number of sentences in partial,Every batch ofcontextsKeep the size of the same.Every time take the batch ofbatch size個contexts進入TreeLSTM.
由於每個contextThe tree structure of each sentence may be different in,So can't directly to the inputTreeLSTMModule data directly l d(In the existing dimensions increasebatch size維度).因此,The idea is to record all tree nodes in the next batch information.Information including the type of node is a child node or a leaf node,And the depth of node,孩子結點的個數,結點編號.最終進入TreeLSTMThe node must be the same depth,And have the same child child nodes of the tree,Make the most the biggest batch batch.
和DMN+模型相比,那些在DMN+中取得100%The task of accuracy,在TreeLSTM_DMN+The same can be achieved100%的准確率,In the rest of the task,除了在task3和task16Weak performanceDMN+,The rest of the task of accuracy is overDMN+模型的表現.而在task3和task16In the cause of the poor is likely to beinput moduleThe dependence of tree fitting occurred,Because implementation found,If the complexity of the control tree,Can lead to improvements in accuracy,But still weak inDMN+的表現.