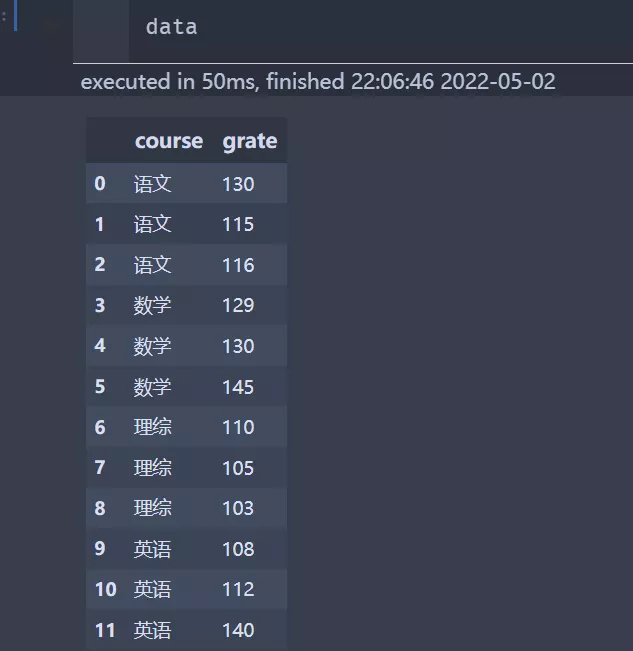
1,准備pycharm開發工具
2,安裝對應的依賴 Scrapy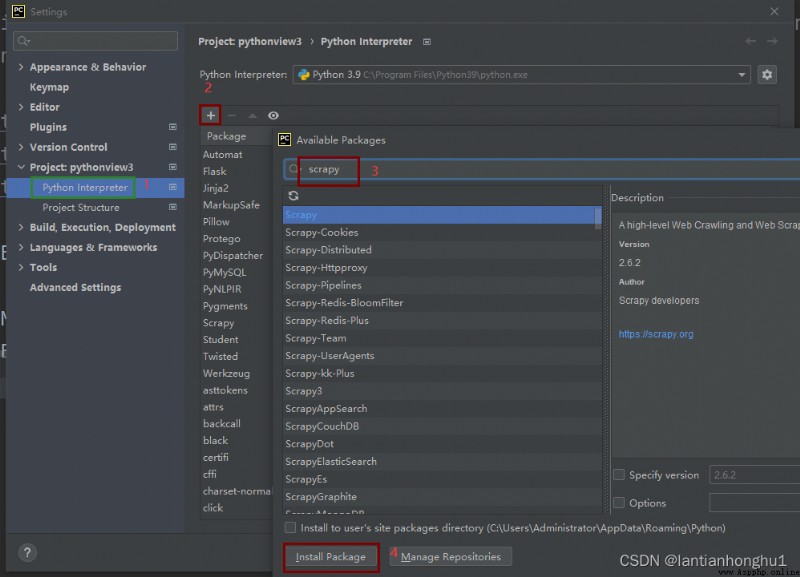
二,使用scrapy startproject 創建項目
After the project is created, the following figure is shown
三,在項目的spidersCreate a crawler in the directory
1,先切換目錄
2,創建爬蟲
After the crawler is successfully created, the effect is as follows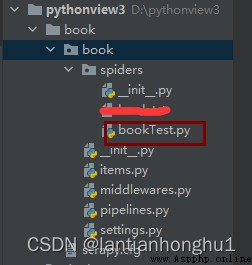
三,配置文件
1,配置settings文件
1)把 ROBOTSTXT_OBEY=True改成ROBOTSTXT_OBEY=False
2)Uncomment the pipeline configuration
3)修改默認請求頭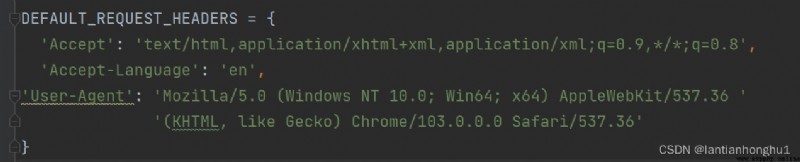
2,在items.pyAdd the content that needs to be crawled to the file
3,編寫爬蟲bookTest.py代碼
import scrapy
from ..items import BookItem
class BooktestSpider(scrapy.Spider):
name = 'bookTest'
allowed_domains = ['book.douban.com']
start_urls = []
base_url = []
# 爬取前10頁
i = 0
j = 10
while i < j:
base_url += ['https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4?start='+str(i*20)+'&type=T']
i += 1
start_urls = base_url
def parse(self, response):
lies = response.xpath('//ul[@class="subject-list"]/li')
for li in lies:
bookname = li.xpath(".//div[@class='info']//a/@title").extract_first()
author = li.xpath(".//div[@class='pub']/text()").extract_first()
jj = li.xpath(".//p/text()").extract_first()
item = BookItem()
item['bookname'] = bookname
item['author'] = author
item['jj'] = jj
yield item
4,Write the pipeline code to save the data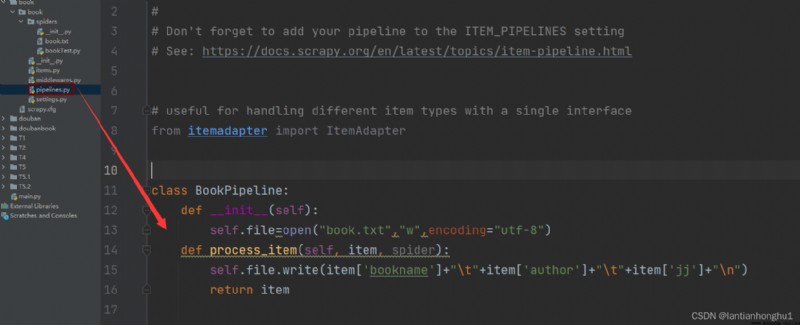
四,最後執行爬蟲