精心整理的 Python 相關的基礎知識,用於面試,或者平時復習,都是很好的!廢話不多說,直接開搞
由於文章過長,蘿卜哥也貼心的把文章整理成了PDF文檔,在文末查看獲取方式
Python 語言簡單易懂,上手容易,隨著 AI 風潮,越來越火
編譯型語言:把做好的源程序全部編譯成二進制的可運行程序。然後,可直接運行這個程序。如:C,C++ 解釋型語言:把做好的源程序翻譯一句,然後執行一句,直至結束!如:Python, (Java 有些特殊,java程序也需要編譯,但是沒有直接編譯稱為機器語言,而是編譯稱為字節碼,然後用解釋方式執行字節碼。)
字符串(str):字符串是用引號括起來的任意文本,是編程語言中最常用的數據類型
列表(list):列表是有序的集合,可以向其中添加或刪除元素
元組(tuple):元組也是有序集合,但是是無法修改的。即元組是不可變的
字典(dict):字典是無序的集合,是由 key-value 組成的
集合(set):是一組 key 的集合,每個元素都是唯一,不重復且無序的
字符串:
mystr='luobodazahui'
mystr[1:3]
output
'uo'
mystr2 = "welcome to luobodazahui, dear {name}"
mystr2.format(name="baby")
output
'welcome to luobodazahui, dear baby'
可以用來連接字符串,將字符串、元組、列表中的元素以指定的字符(分隔符)連接生成一個新的字符串
mylist = ['luo', 'bo', 'da', 'za', 'hui']
mystr3 = '-'.join(mylist)
print(mystr3)
outout
'luo-bo-da-za-hui'
String.replace(old,new,count) 將字符串中的 old 字符替換為 New 字符,count 為替換的個數
mystr4 = 'luobodazahui-haha'
print(mystr4.replace('haha', 'good'))
output
luobodazahui-good
切割字符串,得到一個列表
mystr5 = 'luobo,dazahui good'
# 以空格分割
print(mystr5.split())
# 以h分割
print(mystr5.split('h'))
# 以逗號分割
print(mystr5.split(','))
output
['luobo,dazahui', 'good']
['luobo,daza', 'ui good']
['luobo', 'dazahui good']
列表:
mylist1 = [1, 2]
mylist2 = [3, 4]
mylist3 = [1, 2]
mylist1.append(mylist2)
print(mylist1)
mylist3.extend(mylist2)
print(mylist3)
outout
[1, 2, [3, 4]]
[1, 2, 3, 4]
mylist4 = ['a', 'b', 'c', 'd']
del mylist4[0]
print(mylist4)
mylist4.pop()
print(mylist4)
mylist4.remove('c')
print(mylist4)
output
['b', 'c', 'd']
['b', 'c']
['b']
mylist5 = [1, 5, 2, 3, 4]
mylist5.sort()
print(mylist5)
mylist5.reverse()
print(mylist5)
output
[1, 2, 3, 4, 5]
[5, 4, 3, 2, 1]
字典:
dict1 = {'key1':1, 'key2':2}
dict1.clear()
print(dict1)
output
{}
dict1 = {'key1':1, 'key2':2}
d1 = dict1.pop('key1')
print(d1)
print(dict1)
output
1
{'key2': 2}
dict2 = {'key1':1, 'key2':2}
mykey = [key for key in dict2]
print(mykey)
myvalue = [value for value in dict2.values()]
print(myvalue)
key_value = [(k, v) for k, v in dict2.items() ]
print(key_value)
output
['key1', 'key2']
[1, 2]
[('key1', 1), ('key2', 2)]
keys = ['zhangfei', 'guanyu', 'liubei', 'zhaoyun']
dict.fromkeys(keys, 0)
output
{'zhangfei': 0, 'guanyu': 0, 'liubei': 0, 'zhaoyun': 0}
計算機在最初的設計中,采用了8個比特(bit)作為一個字節(byte)的方式。一個字節能表示的最大的整數就是255(二進制11111111=十進制255),如果要表示更大的整數,就必須用更多的字節
最早,計算機只有 ASCII 編碼,即只包含大小寫英文字母、數字和一些符號,這些對於其他語言,如中文,日文顯然是不夠用的。後來又發明了Unicode,Unicode把所有語言都統一到一套編碼裡,這樣就不會再有亂碼問題了。當需要保存到硬盤或者需要傳輸的時候,就轉換為UTF-8編碼。UTF-8 是隸屬於 Unicode 的可變長的編碼方式
在 Python 中,以 Unicode 方式編碼的字符串,可以使用 encode() 方法來編碼成指定的 bytes,也可以通過 decode() 方法來把 bytes 編碼成字符串 encode
"中文".encode('utf-8')
output
b'\xe4\xb8\xad\xe6\x96\x87'
decode
b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
output
'中文'
1a = 1
2b = 2
3a, b = b, a
4print(a, b)
output
12 1
先來看個例子
c = d = [1,2]
e = [1,2]
print(c is d)
print(c == d)
print(c is e)
print(c == e)
output
True
True
False
True
== 是比較操作符,只是判斷對象的值(value)是否一致,而 is 則判斷的是對象之間的身份(內存地址)是否一致。對象的身份,可以通過 id() 方法來查看
id(c)
id(d)
id(e)
output
88748080
88748080
88558288
可以看出,只有 id 一致時,is 比較才會返回 True,而當 value 一致時,== 比較就會返回 True
位置參數,默認參數,可變參數,關鍵字參數
*arg 和 **kwarg 作用允許我們在調用函數的時候傳入多個實參
def test(*arg, **kwarg):
if arg:
print("arg:", arg)
if kwarg:
print("kearg:", kwarg)
test('ni', 'hao', key='world')
output
arg: ('ni', 'hao')
kearg: {'key': 'world'}
可以看出, *arg 會把位置參數轉化為 tuple **kwarg 會把關鍵字參數轉化為 dict
sum(range(1, 101))
import time
import datetime
print(datetime.datetime.now())
print(time.strftime('%Y-%m-%d %H:%M:%S'))
output
2019-06-07 18:12:11.165330
2019-06-07 18:12:11
簡單列舉10條:
盡量以免單獨使用小寫字母'l',大寫字母'O',以及大寫字母'I'等容易混淆的字母
函數命名使用全部小寫的方式,可以使用下劃線
常量命名使用全部大寫的方式,可以使用下劃線
使用 has 或 is 前綴命名布爾元素,如: is_connect = True; has_member = False
不要在行尾加分號, 也不要用分號將兩條命令放在同一行
不要使用反斜槓連接行
頂級定義之間空2行, 方法定義之間空1行,頂級定義之間空兩行
如果一個類不繼承自其它類, 就顯式的從object繼承
內部使用的類、方法或變量前,需加前綴_表明此為內部使用的
要用斷言來實現靜態類型檢測
淺拷貝
import copy
list1 = [1, 2, 3, [1, 2]]
list2 = copy.copy(list1)
list2.append('a')
list2[3].append('a')
print(list1, list2)
output
[1, 2, 3, [1, 2, 'a']] [1, 2, 3, [1, 2, 'a'], 'a']
能夠看出,淺拷貝只成功”獨立“拷貝了列表的外層,而列表的內層列表,還是共享的
深拷貝
import copy
list1 = [1, 2, 3, [1, 2]]
list3 = copy.deepcopy(list1)
list3.append('a')
list3[3].append('a')
print(list1, list3)
output
[1, 2, 3, [1, 2]] [1, 2, 3, [1, 2, 'a'], 'a']
深拷貝使得兩個列表完全獨立開來,每一個列表的操作,都不會影響到另一個
def num():
return [lambda x:i*x for i in range(4)]
print([m(1) for m in num()])
output
[3, 3, 3, 3]
通過運行結果,可以看出 i 的取值為3,很神奇
可變數據類型:list、dict、set
不可變數據類型:int/float、str、tuple
for i in range(1, 10):
for j in range(1, i+1):
print("%s*%s=%s " %(i, j, i*j), end="")
print()
output
1*1=1
2*1=2 2*2=4
3*1=3 3*2=6 3*3=9
4*1=4 4*2=8 4*3=12 4*4=16
5*1=5 5*2=10 5*3=15 5*4=20 5*5=25
6*1=6 6*2=12 6*3=18 6*4=24 6*5=30 6*6=36
7*1=7 7*2=14 7*3=21 7*4=28 7*5=35 7*6=42 7*7=49
8*1=8 8*2=16 8*3=24 8*4=32 8*5=40 8*6=48 8*7=56 8*8=64
9*1=9 9*2=18 9*3=27 9*4=36 9*5=45 9*6=54 9*7=63 9*8=72 9*9=81
print 函數,默認是會換行的,其有一個默認參數 end,如果像例子中,我們把 end 參數顯示的置為"",那麼 print 函數執行完後,就不會換行了,這樣就達到了九九乘法表的效果了
filter 函數用於過濾序列,它接收一個函數和一個序列,把函數作用在序列的每個元素上,然後根據返回值是True還是False決定保留還是丟棄該元素
mylist = [1, 2, 3, 4, 5, 6, 7, 8, 9]
list(filter(lambda x: x%2 == 1, mylist))
output
[1, 3, 5, 7, 9]
保留奇數列表
map 函數傳入一個函數和一個序列,並把函數作用到序列的每個元素上,返回一個可迭代對象
mylist = [1, 2, 3, 4, 5, 6, 7, 8, 9]
list(map(lambda x: x*2, mylist))
output
[2, 4, 6, 8, 10, 12, 14, 16, 18]
reduce 函數用於遞歸計算,同樣需要傳入一個函數和一個序列,並把函數和序列元素的計算結果與下一個元素進行計算
from functools import reduce
reduce(lambda x, y: x+y, range(101))
output
5050
可以看出,上面的三個函數與匿名函數相結合使用,可以寫出強大簡潔的代碼
match()函數只檢測要匹配的字符是不是在 string 的開始位置匹配,search()會掃描整個 string 查找匹配
__new__ 和 __init__ 區別__new__是在實例創建之前被調用的,因為它的任務就是創建實例然後返回該實例對象,是個靜態方法
__init__是當實例對象創建完成後被調用的,然後設置對象屬性的一些初始值,通常用在初始化一個類實例的時候,是一個實例方法
1、__new__至少要有一個參數 cls,代表當前類,此參數在實例化時由 Python 解釋器自動識別
2、__new__必須要有返回值,返回實例化出來的實例,這點在自己實現__new__時要特別注意,可以 return 父類(通過 super(當前類名, cls))__new__出來的實例,或者直接是 object 的__new__出來的實例
3、__init__有一個參數 self,就是這個__new__返回的實例,__init__在__new__的基礎上可以完成一些其它初始化的動作,__init__不需要返回值
4、如果__new__創建的是當前類的實例,會自動調用__init__函數,通過 return 語句裡面調用的__new__函數的第一個參數是 cls 來保證是當前類實例,如果是其他類的類名,那麼實際創建返回的就是其他類的實例,其實就不會調用當前類的__init__函數,也不會調用其他類的__init__函數
a, b = 1, 2
# 若果 a>b 成立 就輸出 a-b 否則 a+b
h = a-b if a>b else a+b
output
3
print(random.random())
print(random.randint(1, 100))
print(random.uniform(1,5))
output
0.03765019937131564
18
1.8458555362279228
zip() 函數將可迭代的對象作為參數,將對象中對應的元素打包成一個個元組,然後返回由這些元組組成的列表
list1 = ['zhangfei', 'guanyu', 'liubei', 'zhaoyun']
list2 = [0, 3, 2, 4]
list(zip(list1, list2))
output
[('zhangfei', 0), ('guanyu', 3), ('liubei', 2), ('zhaoyun', 4)]
range([start,] stop[, step]),根據start與stop指定的范圍以及step設定的步長,生成一個序列
而 xrange 生成一個生成器,可以很大的節約內存
開文件在進行讀寫的時候可能會出現一些異常狀況,如果按照常規的 f.open 寫法,我們需要 try,except,finally,做異常判斷,並且文件最終不管遇到什麼情況,都要執行 finally f.close() 關閉文件,with 方法幫我們實現了 finally 中 f.close
Python 中默認是貪婪匹配模式
貪婪模式:正則表達式一般趨向於最大長度匹配
非貪婪模式:在整個表達式匹配成功的前提下,盡可能少的匹配
例如:
def test(L=[]):
L.append('test')
print(L)
output
test() # ['test']
test() # ['test', 'test']
默認參數是一個列表,是可變對象[],Python 在函數定義的時候,默認參數 L 的值就被計算出來了,是[],每次調用函數,如果 L 的值變了,那麼下次調用時,默認參數的值就已經不再是[]了
mystr = '1,2,3'
mystr.split(',')
output
['1', '2', '3']
mylist = ['1', '2', '3']
list(map(lambda x: int(x), mylist))
output
[1, 2, 3]
mylist = [1, 2, 3, 4, 5, 5]
list(set(mylist))
from collections import Counter
mystr = 'sdfsfsfsdfsd,were,hrhrgege.sdfwe!sfsdfs'
Counter(mystr)
output
Counter({'s': 9,
'd': 5,
'f': 7,
',': 2,
'w': 2,
'e': 5,
'r': 3,
'h': 2,
'g': 2,
'.': 1,
'!': 1})
[x for x in range(10) if x%2 == 1]
output
[1, 3, 5, 7, 9]
list1 = [[1,2],[3,4],[5,6]]
[j for i in list1 for j in i]
output
[1, 2, 3, 4, 5, 6]
二分查找算法也稱折半查找,基本思想就是折半,對比大小後再折半查找,必須是有序序列才可以使用二分查找
遞歸算法
def binary_search(data, item):
# 遞歸
n = len(data)
if n > 0:
mid = n // 2
if data[mid] == item:
return True
elif data[mid] > item:
return binary_search(data[:mid], item)
else:
return binary_search(data[mid+1:], item)
return False
list1 = [1,4,5,66,78,99,100,101,233,250,444,890]
binary_search(list1, 999)
非遞歸算法
def binary_search(data, item):
# 非遞歸
n = len(data)
first = 0
last = n - 1
while first <= last:
mid = (first + last)//2
if data[mid] == item:
return True
elif data[mid] > item:
last = mid - 1
else:
first = mid + 1
return False
list1 = [1,4,5,66,78,99,100,101,233,250,444,890]
binary_search(list1, 99)
字典轉 json
import json
dict1 = {'zhangfei':1, "liubei":2, "guanyu": 4, "zhaoyun":3}
myjson = json.dumps(dict1)
myjson
output
'{"zhangfei": 1, "liubei": 2, "guanyu": 4, "zhaoyun": 3}'
json 轉字典
mydict = json.loads(myjson)
mydict
output
{'zhangfei': 1, 'liubei': 2, 'guanyu': 4, 'zhaoyun': 3}
import random
td_list=[i for i in range(10)]
print("列表推導式", td_list, type(td_list))
ge_list = (i for i in range(10))
print("生成器", ge_list)
dic = {k:random.randint(4, 9)for k in ["a", "b", "c", "d"]}
print("字典推導式",dic,type(dic))
output
列表推導式 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] <class 'list'>
生成器 <generator object <genexpr> at 0x0139F070>
字典推導式 {'a': 6, 'b': 5, 'c': 8, 'd': 9} <class 'dict'>
read 讀取整個文件
readline 讀取下一行,使用生成器方法
readlines 讀取整個文件到一個迭代器以供我們遍歷
list2 = [1, 2, 3, 4, 5, 6]
random.shuffle(list2)
print(list2)
output
[4, 6, 5, 1, 2, 3]
str1 = 'luobodazahui'
str1[::-1]
output
'iuhazadoboul'
__foo__:一種約定,Python 內部的名字,用來區別其他用戶自定義的命名,以防沖突,就是例如__init__(),__del__(),__call__()些特殊方法
_foo:一種約定,用來指定變量私有。不能用 from module import * 導入,其他方面和公有變量一樣訪問
__foo:這個有真正的意義:解析器用_classname__foo 來代替這個名字,以區別和其他類相同的命名,它無法直接像公有成員一樣隨便訪問,通過對象名._類名__xxx 這樣的方式可以訪問
a. 在 python 裡凡是繼承了 object 的類,都是新式類
b. Python3 裡只有新式類
c. Python2 裡面繼承 object 的是新式類,沒有寫父類的是經典類
d. 經典類目前在 Python 裡基本沒有應用
a. 同時支持單繼承與多繼承,當只有一個父類時為單繼承,當存在多個父類時為多繼承
b. 子類會繼承父類所有的屬性和方法,子類也可以覆蓋父類同名的變量和方法
c. 在繼承中基類的構造(__init__())方法不會被自動調用,它需要在其派生類的構造中專門調用
d. 在調用基類的方法時,需要加上基類的類名前綴,且需要帶上 self 參數變量。區別於在類中調用普通函數時並不需要帶上 self 參數
super() 函數是用於調用父類(超類)的一個方法
class A():
def funcA(self):
print("this is func A")
class B(A):
def funcA_in_B(self):
super(B, self).funcA()
def funcC(self):
print("this is func C")
ins = B()
ins.funcA_in_B()
ins.funcC()
output
this is func A
this is func C
主要分為實例方法、類方法和靜態方法
實例方法
定義:第一個參數必須是實例對象,該參數名一般約定為“self”,通過它來傳遞實例的屬性和方法(也可以傳類的屬性和方法)
調用:只能由實例對象調用
類方法
定義:使用裝飾器@classmethod。第一個參數必須是當前類對象,該參數名一般約定為“cls”,通過它來傳遞類的屬性和方法(不能傳實例的屬性和方法)
調用:實例對象和類對象都可以調用
靜態方法
定義:使用裝飾器@staticmethod。參數隨意,沒有“self”和“cls”參數,但是方法體中不能使用類或實例的任何屬性和方法
調用:實例對象和類對象都可以調用
靜態方法是類中的函數,不需要實例。靜態方法主要是用來存放邏輯性的代碼,主要是一些邏輯屬於類,但是和類本身沒有交互。即在靜態方法中,不會涉及到類中的方法和屬性的操作。可以理解為將靜態方法存在此類的名稱空間中
類方法是將類本身作為對象進行操作的方法。他和靜態方法的區別在於:不管這個方式是從實例調用還是從類調用,它都用第一個參數把類傳遞過來
與類和實例無綁定關系的 function 都屬於函數(function)
與類和實例有綁定關系的 function 都屬於方法(method)
普通函數:
def func1():
pass
print(func1)
output
<function func1 at 0x01379348>
類中的函數:
class People(object):
def func2(self):
pass
@staticmethod
def func3():
pass
@classmethod
def func4(cls):
pass
people = People()
print(people.func2)
print(people.func3)
print(people.func4)
output
<bound method People.func2 of <__main__.People object at 0x013B8C90>>
<function People.func3 at 0x01379390>
<bound method People.func4 of <class '__main__.People'>>
isinstance() 函數來判斷一個對象是否是一個已知的類型,類似 type()
區別:
type() 不會認為子類是一種父類類型,不考慮繼承關系
isinstance() 會認為子類是一種父類類型,考慮繼承關系
class A(object):
pass
class B(A):
pass
a = A()
b = B()
print(isinstance(a, A))
print(isinstance(b, A))
print(type(a) == A)
print(type(b) == A)
output
True
True
True
False
單例模式:主要目的是確保某一個類只有一個實例存在
工廠模式:包涵一個超類,這個超類提供一個抽象化的接口來創建一個特定類型的對象,而不是決定哪個對象可以被創建
import os
print(os.listdir('.'))
# 1到5組成的互不重復的三位數
k = 0
for i in range(1, 6):
for j in range(1, 6):
for z in range(1, 6):
if (i != j) and (i != z) and (j != z):
k += 1
if k%6:
print("%s%s%s" %(i, j, z), end="|")
else:
print("%s%s%s" %(i, j, z))
output
123|124|125|132|134|135
142|143|145|152|153|154
213|214|215|231|234|235
241|243|245|251|253|254
312|314|315|321|324|325
341|342|345|351|352|354
412|413|415|421|423|425
431|432|435|451|452|453
512|513|514|521|523|524
531|532|534|541|542|543
str1 = " hello nihao "
str1.strip()
output
'hello nihao'
str2 = "hello you are good"
print(str2.replace(" ", ""))
"".join(str2.split(" "))
output
helloyouaregood
'helloyouaregood'
print("This is for %s" % "Python")
print("This is for %s, and %s" %("Python", "You"))
output
This is for Python
This is for Python, and You
在 Python3 中,引入了這個新的字符串格式化方法
print("This is my {}".format("chat"))
print("This is {name}, hope you can {do}".format(name="zhouluob", do="like"))
output
This is my chat
This is zhouluob, hope you can like
在 Python3-6 中,引入了這個新的字符串格式化方法
name = "luobodazahui"
print(f"hello {name}")
output
hello luobodazahui
一個復雜些的例子:
def mytest(name, age):
return f"hello {name}, you are {age} years old!"
people = mytest("luobo", 20)
print(people)
output
hello luobo, you are 20 years old!
str1 = "hello world"
print(str1.title())
" ".join(list(map(lambda x: x.capitalize(), str1.split(" "))))
output
Hello World
'Hello World'
如:[1, 2, 3] -> ["1", "2", "3"]
list1 = [1, 2, 3]
list(map(lambda x: str(x), list1))
output
['1', '2', '3']
如:("zhangfei", "guanyu"),(66, 80) -> {'zhangfei': 66, 'guanyu': 80}
a = ("zhangfei", "guanyu")
b = (66, 80)
dict(zip(a,b))
output
{'zhangfei': 66, 'guanyu': 80}
例子1:
a = (1,2,3,[4,5,6,7],8)
a[3] = 2
output
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-35-59469d550eb0> in <module>
1 a = (1,2,3,[4,5,6,7],8)
----> 2 a[3] = 2
3 #a
TypeError: 'tuple' object does not support item assignment
例子2:
a = (1,2,3,[4,5,6,7],8)
a[3][2] = 2
a
output
(1, 2, 3, [4, 5, 2, 7], 8)
從例子1的報錯中也可以看出,tuple 是不可變類型,不能改變 tuple 裡的元素,例子2中,list 是可變類型,改變其元素是允許的
反射就是通過字符串的形式,導入模塊;通過字符串的形式,去模塊尋找指定函數,並執行。利用字符串的形式去對象(模塊)中操作(查找/獲取/刪除/添加)成員,一種基於字符串的事件驅動!
簡單理解就是用來判斷某個字符串是什麼,是變量還是方法
class NewClass(object):
def __init__(self, name, male):
self.name = name
self.male = male
def myname(self):
print(f'My name is {self.name}')
def mymale(self):
print(f'I am a {self.male}')
people = NewClass('luobo', 'boy')
print(hasattr(people, 'name'))
print(getattr(people, 'name'))
setattr(people, 'male', 'girl')
print(getattr(people, 'male'))
output
True
luobo
girl
getattr,hasattr,setattr,delattr 對模塊的修改都在內存中進行,並不會影響文件中真實內容
使用 flask 構造 web 服務器
from flask import Flask, request
app = Flask(__name__)
@app.route('/', methods=['POST'])
def simple_api():
result = request.get_json()
return result
if __name__ == "__main__":
app.run()
類與實例:
首先定義類以後,就可以根據這個類創建出實例,所以:先定義類,然後創建實例
類與元類:
先定義元類, 根據 metaclass 創建出類,所以:先定義 metaclass,然後創建類
class MyMetaclass(type):
def __new__(cls, class_name, class_parents, class_attr):
class_attr['print'] = "this is my metaclass's subclass %s" %class_name
return type.__new__(cls, class_name, class_parents, class_attr)
class MyNewclass(object, metaclass=MyMetaclass):
pass
myinstance = MyNewclass()
myinstance.print
output
"this is my metaclass's subclass MyNewclass"
sort() 是可變對象列表(list)的方法,無參數,無返回值,sort() 會改變可變對象
dict1 = {'test1':1, 'test2':2}
list1 = [2, 1, 3]
print(list1.sort())
list1
output
None
[1, 2, 3]
sorted() 是產生一個新的對象。sorted(L) 返回一個排序後的L,不改變原始的L,sorted() 適用於任何可迭代容器
dict1 = {'test1':1, 'test2':2}
list1 = [2, 1, 3]
print(sorted(dict1))print(sorted(list1))
output
['test1', 'test2']
[1, 2, 3]
GIL 是 Python 的全局解釋器鎖,同一進程中假如有多個線程運行,一個線程在運行 Python 程序的時候會占用 Python 解釋器(加了一把鎖即 GIL),使該進程內的其他線程無法運行,等該線程運行完後其他線程才能運行。如果線程運行過程中遇到耗時操作,則解釋器鎖解開,使其他線程運行。所以在多線程中,線程的運行仍是有先後順序的,並不是同時進行
import random
"".join(random.choice(string.printable[:-7]) for i in range(8))
output
'd5^NdNJp'
print('hello\nworld')
print(b'hello\nworld')
print(r'hello\nworld')
output
hello
world
b'hello\nworld'
hello\nworld
list1 = [{'name': 'guanyu', 'age':29},
{'name': 'zhangfei', 'age': 28},
{'name': 'liubei', 'age':31}]
sorted(list1, key=lambda x:x['age'])
output
[{'name': 'zhangfei', 'age': 28},
{'name': 'guanyu', 'age': 29},
{'name': 'liubei', 'age': 31}]
all 如果存在 0 Null False 返回 False,否則返回 True;any 如果都是 0,None,False,Null 時,返回 True
print(all([1, 2, 3, 0]))
print(all([1, 2, 3]))
print(any([1, 2, 3, 0]))
print(any([0, None, False]))
output
False
True
True
False
def reverse_int(x):
if not isinstance(x, int):
return False
if -10 < x < 10:
return x
tmp = str(x)
if tmp[0] != '-':
tmp = tmp[::-1]
return int(tmp)
else:
tmp = tmp[1:][::-1]
x = int(tmp)
return -x
reverse_int(-23837)
output
-73832
首先判斷是否是整數,再判斷是否是一位數字,最後再判斷是不是負數
函數式編程是一種抽象程度很高的編程范式,純粹的函數式編程語言編寫的函數沒有變量,因此,任意一個函數,只要輸入是確定的,輸出就是確定的,這種純函數稱之為沒有副作用。而允許使用變量的程序設計語言,由於函數內部的變量狀態不確定,同樣的輸入,可能得到不同的輸出,因此,這種函數是有副作用的。由於 Python 允許使用變量,因此,Python 不是純函數式編程語言
函數式編程的一個特點就是,允許把函數本身作為參數傳入另一個函數,還允許返回一個函數!
函數作為返回值例子:
def sum(*args):
def inner_sum():
tmp = 0
for i in args:
tmp += i
return tmp
return inner_sum
mysum = sum(2, 4, 6)
print(type(mysum))
mysum()
output
<class 'function'>
12
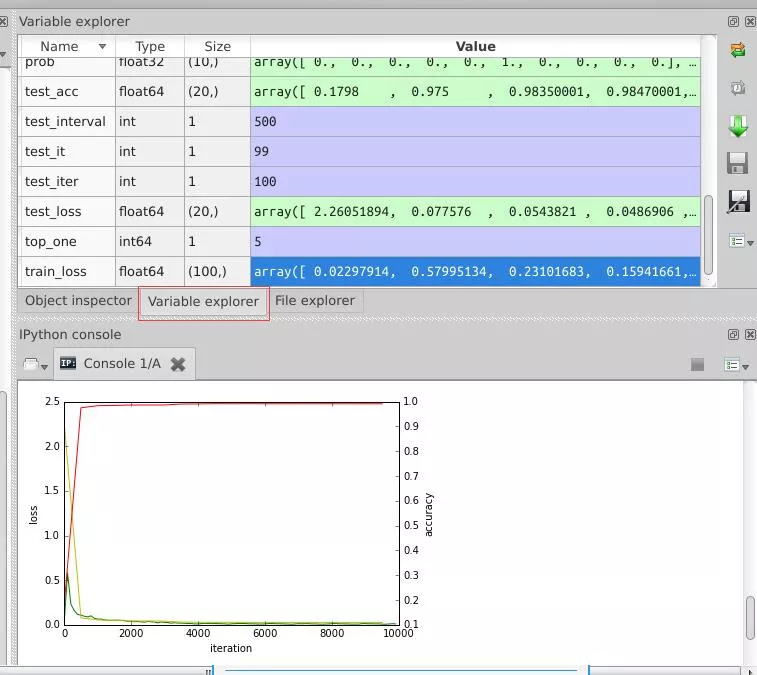
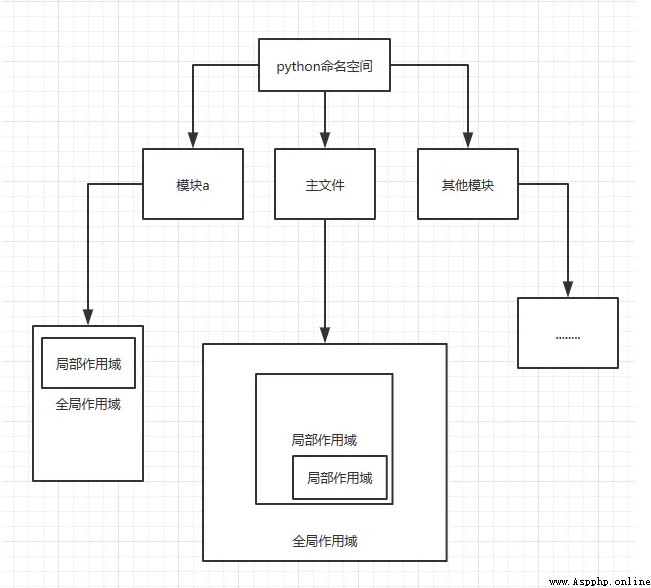
如果在一個內部函數裡,對在外部作用域(但不是在全局作用域)的變量進行引用,那麼內部函數就被認為是閉包(closure) 附上函數作用域圖片
閉包特點
1.必須有一個內嵌函數
2.內嵌函數必須引用外部函數中的變量
3.外部函數的返回值必須是內嵌函數
裝飾器是一種特殊的閉包,就是在閉包的基礎上傳遞了一個函數,然後覆蓋原來函數的執行入口,以後調用這個函數的時候,就可以額外實現一些功能了
一個打印 log 的例子:
import time
def log(func):
def inner_log(*args, **kw):
print("Call: {}".format(func.__name__))
return func(*args, **kw)
return inner_log
@log
def timer():
print(time.time())
timer()
output
Call: timer
1560171403.5128365
本質上,decorator就是一個返回函數的高階函數
子程序切換不是線程切換,而是由程序自身控制
沒有線程切換的開銷,和多線程比,線程數量越多,協程的性能優勢就越明顯
不需要多線程的鎖機制,因為只有一個線程,也不存在同時寫變量沖突,在協程中控制共享資源不加鎖
斐波那契數列:
又稱黃金分割數列,指的是這樣一個數列:1、1、2、3、5、8、13、21、34、……在數學上,斐波納契數列以如下被以遞歸的方法定義:F(1)=1,F(2)=1, F(n)=F(n-1)+F(n-2)(n>=2,n∈N*)
生成器法:
def fib(n):
if n == 0:
return False
if not isinstance(n, int) or (abs(n) != n): # 判斷是正整數
return False
a, b = 0, 1
while n:
a, b = b, a+b
n -= 1
yield a
[i for i in fib(10)]
output
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
遞歸法:
def fib(n):
if n == 0:
return False
if not isinstance(n, int) or (abs(n) != n):
return False
if n <= 1:
return n
return fib(n-1)+ fib(n-2)
[fib(i) for i in range(1, 11)]
output
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
import re
str1 = 'hello world:luobo dazahui'
result = re.split(r":| ", str1)
print(result)
output
['hello', 'world', 'luobo', 'dazahui']
yield 是用來生成迭代器的語法,在函數中,如果包含了 yield,那麼這個函數就是一個迭代器。當代碼執行至 yield 時,就會中斷代碼執行,直到程序調用 next() 函數時,才會在上次 yield 的地方繼續執行
def foryield():
print("start test yield")
while True:
result = yield 5
print("result:", result)
g = foryield()
print(next(g))
print("*"*20)
print(next(g))
output
start test yield
5
********************
result: None
5
可以看到,第一個調用 next() 函數,程序只執行到了 "result = yield 5" 這裡,同時由於 yield 中斷了程序,所以 result 也沒有被賦值,所以第二次執行 next() 時,result 是 None
list1 = [2, 5, 8, 9, 3, 11]
def paixu(data, reverse=False):
if not reverse:
for i in range(len(data) - 1):
for j in range(len(data) - 1 - i):
if data[j] > data[j+1]:
data[j], data[j+1] = data[j+1], data[j]
return data
else:
for i in range(len(data) - 1):
for j in range(len(data) - 1 - i):
if data[j] < data[j+1]:
data[j], data[j+1] = data[j+1], data[j]
return data
print(paixu(list1, reverse=True))
output
[11, 9, 8, 5, 3, 2]
快排的思想:首先任意選取一個數據(通常選用數組的第一個數)作為關鍵數據,然後將所有比它小的數都放到它前面,所有比它大的數都放到它後面,這個過程稱為一趟快速排序,之後再遞歸排序兩邊的數據
挑選基准值:從數列中挑出一個元素,稱為"基准"(pivot)
分割:重新排序數列,所有比基准值小的元素擺放在基准前面,所有比基准值大的元素擺在基准後面(與基准值相等的數可以到任何一邊)
在這個分割結束之後,對基准值的排序就已經完成
遞歸排序子序列:遞歸地將小於基准值元素的子序列和大於基准值元素的子序列排序
list1 = [8, 5, 1, 3, 2, 10, 11, 4, 12, 20]
def partition(arr,low,high):
i = ( low-1 ) # 最小元素索引
pivot = arr[high]
for j in range(low , high):
# 當前元素小於或等於 pivot
if arr[j] <= pivot:
i = i+1
arr[i],arr[j] = arr[j],arr[i]
arr[i+1],arr[high] = arr[high],arr[i+1]
return ( i+1 )
def quicksort(arr,low,high):
if low < high:
pi = partition(arr,low,high)
quicksort(arr, low, pi-1)
quicksort(arr, pi+1, high)
quicksort(list1, 0, len(list1)-1)
print(list1)
output
[1, 2, 3, 4, 5, 8, 10, 11, 12, 20]
該庫是發起 HTTP 請求的強大類庫,調用簡單,功能強大
import requests
url = "http://www.luobodazahui.top"
response = requests.get(url) # 獲得請求
response.encoding = "utf-8" # 改變其編碼
html = response.text # 獲得網頁內容
binary__content = response.content # 獲得二進制數據
raw = requests.get(url, stream=True) # 獲得原始響應內容
headers = {'user-agent': 'my-test/0.1.1'} # 定制請求頭
r = requests.get(url, headers=headers)
cookies = {"cookie": "# your cookie"} # cookie的使用
r = requests.get(url, cookies=cookies)
dict1 = {"zhangfei": 12, "guanyu": 13, "liubei": 18}
dict2 = {"zhangfei": 12, "guanyu": 13, "liubei": 18}
def compare_dict(dict1, dict2):
issame = []
for k in dict1.keys():
if k in dict2:
if dict1[k] == dict2[k]:
issame.append(1)
else:
issame.append(2)
else:
issame.append(3)
print(issame)
sum_except = len(issame)
sum_actually = sum(issame)
if sum_except == sum_actually:
print("this two dict are same!")
return True
else:
print("this two dict are not same!")
return False
test = compare_dict(dict1, dict2)
output
[1, 1, 1]
this two dict are same!
input() 函數
def forinput():
input_text = input()
print("your input text is: ", input_text)
forinput()
output
hello
your input text is: hello
enumerate() 函數用於將一個可遍歷的數據對象(如列表、元組或字符串)組合為一個索引序列,同時列出數據和數據下標,一般用在 for 循環當中
data1 = ['one', 'two', 'three', 'four']
for i, enu in enumerate(data1):
print(i, enu)
output
0 one
1 two
2 three
3 four
pass 是空語句,是為了保持程序結構的完整性。pass 不做任何事情,一般用做占位語句
def forpass(n):
if n == 1:
pass
else:
print('not 1')
forpass(1)
import re
email_list= ["[email protected]","[email protected]", "[email protected]", "[email protected]" ]
for email in email_list:
ret = re.match("[\w]{4,20}@(.*)\.com$",email)
if ret:
print("%s 是符合規定的郵件地址,匹配後結果是:%s" % (email,ret.group()))
else:
print("%s 不符合要求" % email)
output
[email protected] 是符合規定的郵件地址,匹配後結果是:[email protected]
[email protected] 不符合要求
[email protected] 不符合要求
[email protected] 是符合規定的郵件地址,匹配後結果是:[email protected]
str2 = 'werrQWSDdiWuW'
counter = 0
for i in str2:
if i.isupper():
counter += 1
print(counter)
output
6
普通序列化:
import json
dict1 = {'name': '蘿卜', 'age': 18}
dict1_new = json.dumps(dict1)
print(dict1_new)
output
{"name": "\u841d\u535c", "age": 18}
保留中文
import json
dict1 = {'name': '蘿卜', 'age': 18}
dict1_new = json.dumps(dict1, ensure_ascii=False)
print(dict1_new)
output
{"name": "蘿卜", "age": 18}
一個類繼承自另一個類,也可以說是一個孩子類/派生類/子類,繼承自父類/基類/超類,同時獲取所有的類成員(屬性和方法)
繼承使我們可以重用代碼,並且還可以更方便地創建和維護代碼
Python 支持以下類型的繼承:
單繼承- 一個子類類繼承自單個基類
多重繼承- 一個子類繼承自多個基類
多級繼承- 一個子類繼承自一個基類,而基類繼承自另一個基類
分層繼承- 多個子類繼承自同一個基類
混合繼承- 兩種或兩種以上繼承類型的組合
猴子補丁是指在運行時動態修改類和模塊
猴子補丁主要有以下幾個用處:
在運行時替換方法、屬性等
在不修改第三方代碼的情況下增加原來不支持的功能
在運行時為內存中的對象增加 patch 而不是在磁盤的源代碼中增加
help() 函數返回幫助文檔和參數說明:
help(dict)
output
Help on class dict in module builtins:
class dict(object)
| dict() -> new empty dictionary
| dict(mapping) -> new dictionary initialized from a mapping object's
| (key, value) pairs
| dict(iterable) -> new dictionary initialized as if via:
| d = {}
| for k, v in iterable:
| d[k] = v
| dict(**kwargs) -> new dictionary initialized with the name=value pairs
| in the keyword argument list. For example: dict(one=1, two=2)
......
dir() 函數返回對象中的所有成員 (任何類型)
dir(dict)
output
['__class__',
'__contains__',
'__delattr__',
'__delitem__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattribute__',
'__getitem__',
......
//,%和**運算符// 運算符執行地板除法,返回結果的整數部分 (向下取整)
% 是取模符號,返回除法後的余數
** 符號表示取冪. a**b 返回 a 的 b 次方
print(5//3)
print(5/3)
print(5%3)
print(5**3)
output
1
1.6666666666666667
2
125
使用 raise
def test_raise(n):
if not isinstance(n, int):
raise Exception('not a int type')
else:
print('good')
test_raise(8.9)
output
---------------------------------------------------------------------------
Exception Traceback (most recent call last)
<ipython-input-262-b45324f5484e> in <module>
4 else:
5 print('good')
----> 6 test_raise(8.9)
<ipython-input-262-b45324f5484e> in test_raise(n)
1 def test_raise(n):
2 if not isinstance(n, int):
----> 3 raise Exception('not a int type')
4 else:
5 print('good')
Exception: not a int type
tuple1 = (1, 2, 3, 4)
list1 = list(tuple1)
print(list1)
tuple2 = tuple(list1)
print(tuple2)
output
[1, 2, 3, 4](1, 2, 3, 4)
Python 的斷言就是檢測一個條件,如果條件為真,它什麼都不做;反之它觸發一個帶可選錯誤信息的 AssertionError
def testassert(n):
assert n == 2, "n is not 2"
print('n is 2')
testassert(1)
output
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-268-a9dfd6c79e73> in <module>
2 assert n == 2, "n is not 2"
3 print('n is 2')
----> 4 testassert(1)
<ipython-input-268-a9dfd6c79e73> in testassert(n)
1 def testassert(n):
----> 2 assert n == 2, "n is not 2"
3 print('n is 2')
4 testassert(1)
AssertionError: n is not 2
同步異步指的是調用者與被調用者之間的關系
所謂同步,就是在發出一個功能調用時,在沒有得到結果之前,該調用就不會返回,一旦調用返回,就得到了返回值
異步的概念和同步相對,調用在發出之後,這個調用就直接返回了,所以沒有返回結果。當該異步功能完成後,被調用者可以通過狀態、通知或回調來通知調用者
阻塞非阻塞是線程或進程之間的關系
阻塞調用是指調用結果返回之前,當前線程會被掛起(如遇到io操作)。調用線程只有在得到結果之後才會返回。函數只有在得到結果之後才會將阻塞的線程激活
非阻塞和阻塞的概念相對應,非阻塞調用指在不能立刻得到結果之前也會立刻返回,同時該函數不會阻塞當前線程
Python 中的序列是有索引的,它由正數和負數組成。正的數字使用'0'作為第一個索引,'1'作為第二個索引,以此類推
負數的索引從'-1'開始,表示序列中的最後一個索引,' - 2'作為倒數第二個索引,依次類推
不是的,那些具有對象循環引用或者全局命名空間引用的變量,在 Python 退出時往往不會被釋放
另外不會釋放 C 庫保留的部分內容
Flask 是 “microframework”,主要用來編寫小型應用程序,不過隨著 Python 的普及,很多大型程序也在使用 Flask。同時,在 Flask 中,我們必須使用外部庫
Django 適用於大型應用程序。它提供了靈活性,以及完整的程序框架和快速的項目生成方法。可以選擇不同的數據庫,URL結構,模板樣式等
import os
f = open('test.txt', 'w')
f.close()
os.listdir()
os.remove('test.txt')
logging 模塊是 Python 內置的標准模塊,主要用於輸出運行日志,可以設置輸出日志的等級、日志保存路徑、日志文件回滾等;相比 print,具備如下優點:
可以通過設置不同的日志等級,在 release 版本中只輸出重要信息,而不必顯示大量的調試信息
print 將所有信息都輸出到標准輸出中,嚴重影響開發者從標准輸出中查看其它數據;logging 則可以由開發者決定將信息輸出到什麼地方,以及怎麼輸出
簡單配置:
import logging
logging.debug("debug log")
logging.info("info log")
logging.warning("warning log")
logging.error("error log")
logging.critical("critica log")
output
WARNING:root:warning log
ERROR:root:error log
CRITICAL:root:critica log
默認情況下,只顯示了大於等於WARNING級別的日志。logging.basicConfig()函數調整日志級別、輸出格式等
from collections import Counter
str1 = "nihsasehndciswemeotpxc"
print(Counter(str1))
output
Counter({'s': 3, 'e': 3, 'n': 2, 'i': 2, 'h': 2, 'c': 2, 'a': 1, 'd': 1, 'w': 1, 'm': 1, 'o': 1, 't': 1, 'p': 1, 'x': 1})
re.compile 是將正則表達式編譯成一個對象,加快速度,並重復使用
try..except..else 沒有捕獲到異常,執行 else 語句
try..except..finally 不管是否捕獲到異常,都執行 finally 語句
使用切片:
$ python -m timeit -n 1000000 -s 'import numpy as np' 'mylist=list(np.arange(0, 200))' 'mylist[::-1]'
1000000 loops, best of 5: 15.6 usec per loop
使用 reverse():
$ python -m timeit -n 1000000 -s 'import numpy as np' 'mylist=list(np.arange(0, 200))' 'mylist.reverse()'
1000000 loops, best of 5: 10.7 usec per loop
這兩種方法都可以反轉列表,但需要注意的是內置函數 reverse() 會更改原始列表,而切片方法會創建一個新列表。
顯然,內置函數 reverse() 比列表切片方法更快!
使用 re 正則替換
import re
str1 = '我是周蘿卜,今年18歲'
result = re.sub(r"\d+","20",str1)
print(result)
output
我是周蘿卜,今年20歲
是網絡傳輸協議,人為的把網絡傳輸的不同階段劃分成不同的層次
七層劃分為:應用層、表示層、會話層、傳輸層、網絡層、數據鏈路層、物理層
五層劃分為:應用層、傳輸層、網絡層、數據鏈路層、物理層
物理層:網線,電纜等物理設備
數據鏈路層:Mac 地址
網絡層:IP 地址
傳輸層:TCP,UDP 協議
應用層:FTP 協議,Email,WWW 等
都發生在傳輸層
三次握手:
TCP 協議是主機對主機層的傳輸控制協議,提供可靠的連接服務,采用三次握手確認建立一個連接。 TCP 標志位(位碼),有6種標示:SYN(synchronous建立聯機) ACK(acknowledgement 確認) PSH(push傳送) FIN(finish結束) RST(reset重置) URG(urgent緊急) Sequence number(順序號碼) Acknowledge number(確認號碼) 第一次握手:主機 A 發送位碼為 syn=1,隨機產生 seq number=1234567 的數據包到服務器,並進入 SYN_SEND 狀態,主機 B 由 SYN=1 知道,A 要求建立聯機
第二次握手:主機 B 收到請求後要確認聯機信息,向 A 發送 ack number=(主機 A 的 seq+1),syn=1,ack=1,隨機產生 seq=7654321 的包,並進入 SYN_RECV 狀態
第三次握手:主機 A 收到後檢查 ack number 是否正確,即第一次發送的 seq number+1,以及位碼 ack 是否為 1,若正確,主機 A 會再發送 ack number=(主機 B 的 seq+1),ack=1,主機 B 收到後確認 seq 值與 ack=1 則連接建立成功,兩個主機均進入 ESTABLISHED 狀態
以上完成三次握手,主機 A 與主機 B 開始傳送數據
四次揮手:
因為 TCP 連接是全雙工的,因此每個方向都必須單獨進行關閉。這個原則是當一方完成它的數據發送任務後就能發送一個 FIN 來終止這個方向的連接。收到一個 FIN 只意味著這一方向上沒有數據流動,一個 TCP 連接在收到一個 FIN 後仍能發送數據。首先進行關閉的一方將執行主動關閉,而另一方執行被動關閉
服務器 A 發送一個 FIN,用來關閉 A 到服務器 B 的數據傳送。 服務器 B 收到這個 FIN,它發回一個 ACK,確認序號為收到的序號加1。和 SYN 一樣,一個 FIN 將占用一個序號
服務器 B 關閉與服務器 A 的連接,發送一個 FIN 給服務器 A
服務器 A 發回 ACK 報文確認,並將確認序號設置為收到序號加1
B/S 又稱為浏覽器/服務器模式。比如各種網站,jupyter notebook 等。 優點:零安裝,維護簡單,共享性好。 缺點:安全性較差,個性化不足
C/S 又稱為客戶端/服務器模式。比如微信客戶端,Oracle 客戶端等。 優點:安全性好,數據傳輸較快,穩定。 缺點:對 PC 機操作系統等有要求,當客戶端較多時,服務器端負載較大
TCP 和 UDP 都是 OSI 模型中運輸層的協議。TCP 提供可靠的通信傳輸,而 UDP 則常被用於廣播和細節控制交給應用的通信傳輸。 UDP 不提供復雜的控制機制,利用 IP 提供面向無連接的通信服務。 TCP 充分實現了數據傳輸時各種控制功能,可以進行丟包的重發控制,還可以對次序亂掉的分包進行順序控制
TCP 應用:FTP 傳輸,點對點短信等
UDP 應用:媒體流等
廣域網(WAN,Wide Area Network)也稱遠程網(long haul network )。通常跨接很大的物理范圍,所覆蓋的范圍從幾十公裡到幾千公裡,它能連接多個城市或國家,或橫跨幾個洲並能提供遠距離通信,形成國際性的遠程網絡
域網(Local Area Network,LAN)是指在某一區域內由多台計算機互聯成的計算機組。一般是方圓幾千米以內。局域網可以實現文件管理、應用軟件共享、打印機共享、工作組內的日程安排、電子郵件和傳真通信服務等功能。局域網是封閉型的,可以由辦公室內的兩台計算機組成,也可以由一個公司內的上千台計算機組成
ARP(Address Resolution Protocol)即地址解析協議, 用於實現從 IP 地址到 MAC 地址的映射,即詢問目標 IP 對應的 MAC 地址
socket 是對 TCP/IP 協議的封裝,它的出現只是使得程序員更方便地使用 TCP/IP 協議棧而已。socket 本身並不是協議,它是應用層與 TCP/IP 協議族通信的中間軟件抽象層,是一組調用接口(TCP/IP網絡的API函數)
“TCP/IP 只是一個協議棧,就像操作系統的運行機制一樣,必須要具體實現,同時還要提供對外的操作接口。 這個就像操作系統會提供標准的編程接口,比如win32編程接口一樣。TCP/IP 也要提供可供程序員做網絡開發所用的接口,這就是 Socket 編程接口。”
Server:
import socket
import threading
def tcplink(sock, addr):
print('Accept new connection from %s:%s...' % addr)
sock.send(b'Welcome!')
while True:
data = sock.recv(1024)
time.sleep(1)
if not data or data.decode('utf-8') == 'exit':
break
sock.send(('Hello, %s!' % data.decode('utf-8')).encode('utf-8'))
sock.close()
print('Connection from %s:%s closed.' % addr)
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 監聽端口:
s.bind(('127.0.0.1', 9999))
s.listen(5)
print('Waiting for connection...')
while True:
# 接受一個新連接:
sock, addr = s.accept()
# 創建新線程來處理TCP連接:
t = threading.Thread(target=tcplink, args=(sock, addr))
t.start()
Client:
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 建立連接:
s.connect(('127.0.0.1', 9999))
# 接收歡迎消息:
print(s.recv(1024).decode('utf-8'))
for data in [b'Michael', b'Tracy', b'Sarah']:
# 發送數據:
s.send(data)
print(s.recv(1024).decode('utf-8'))
s.send(b'exit')
s.close()
例子來源於廖雪峰的官網
進程是具有一定獨立功能的程序關於某個數據集合上的一次運行活動,進程是系統進行資源分配和調度的一個獨立單位。每個進程都有自己的獨立內存空間,不同進程通過進程間通信來通信
線程是進程的一個實體,是CPU調度和分派的基本單位,它是比進程更小的能獨立運行的基本單位。線程自己基本上不擁有系統資源,只擁有一點在運行中必不可少的資源(如程序計數器,一組寄存器和棧),但是它可與同屬一個進程的其他的線程共享進程所擁有的全部資源
協程是一種用戶態的輕量級線程,協程的調度完全由用戶控制。協程擁有自己的寄存器上下文和棧
多進程:密集 CPU 任務,需要充分使用多核 CPU 資源(服務器,大量的並行計算)的時候,用多進程。 缺陷:多個進程之間通信成本高,切換開銷大
多線程:密集 I/O 任務(網絡 I/O,磁盤 I/O,數據庫 I/O)使用多線程合適。 缺陷:同一個時間切片只能運行一個線程,不能做到高並行,但是可以做到高並發
協程:又稱微線程,在單線程上執行多個任務,用函數切換,開銷極小。不通過操作系統調度,沒有進程、線程的切換開銷。缺陷:單線程執行,處理密集 CPU 和本地磁盤 IO 的時候,性能較低。處理網絡 I/O 性能還是比較高
多線程請求返回是無序的,哪個線程有數據返回就處理哪個線程,而協程返回的數據是有序的
池的功能是限制啟動的進程數或線程數。當並發的任務數遠遠超過了計算機的承受能力時,即無法一次性開啟過多的進程數或線程數時,就應該用池的概念將開啟的進程數或線程數限制在計算機可承受的范圍內
多進程
from multiprocessing import Pool
import os
import time
import random
def long_time_task(name):
print('Run task %s (%s)...' % (name, os.getpid()))
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print('Task %s runs %0.2f seconds.' % (name, (end - start)))
def test_pool():
print('Parent process %s.' % os.getpid())
p = Pool(4)
for i in range(5):
p.apply_async(long_time_task, args=(i,))
print('Waiting for all subprocesses done...')
p.close()
p.join()
print('All subprocesses done.')
if __name__ == '__main__':
test_pool()
output
Parent process 32432.
Waiting for all subprocesses done...
Run task 0 (15588)...
Run task 1 (32372)...
Run task 2 (12440)...
Run task 3 (18956)...
Task 2 runs 0.72 seconds.
Run task 4 (12440)...
Task 3 runs 0.82 seconds.
Task 1 runs 1.21 seconds.
Task 0 runs 3.00 seconds.
Task 4 runs 2.95 seconds.
All subprocesses done.
apply_async(func[, args[, kwds]]) :使用非阻塞方式調用 func(並行執行,堵塞方式必須等待上一個進程退出才能執行下一個進程),args 為傳遞給 func 的參數列表,kwds 為傳遞給 func 的關鍵字參數列表; close():關閉 Pool,使其不再接受新的任務; terminate():不管任務是否完成,立即終止; join():主進程阻塞,等待子進程的退出, 必須在 close 或 terminate 之後使用
也可以使用 concurrent.futures 模塊提供的功能來實現
def test_future_process():
print('Parent process %s.' % os.getpid())
p = ProcessPoolExecutor(4)
for i in range(5):
p.submit(long_time_task, i)
p.shutdown(wait=True)
print('Finish')
if __name__ == '__main__':
# test_pool()
test_future_process()
output
Parent process 29368.
Run task 0 (32148)...
Run task 1 (31552)...
Run task 2 (24012)...
Run task 3 (29408)...
Task 2 runs 0.52 seconds.
Run task 4 (24012)...
Task 3 runs 0.86 seconds.
Task 1 runs 1.81 seconds.
Task 0 runs 1.83 seconds.
Task 4 runs 1.69 seconds.
Finish
多線程
def sayhello(a):
print("hello: " + a)
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print('Task %s runs %0.2f seconds.' % (a, (end - start)))
def test_future_thread():
seed = ["a", "b", "c", "d"]
start = time.time()
with ThreadPoolExecutor(3) as executor:
for i in seed:
executor.submit(sayhello, i)
end = time.time()
print("Thread Run Time: " + str(end - start))
output
hello: a
hello: b
hello: c
Task a runs 0.40 seconds.
hello: d
Task b runs 0.56 seconds.
Task d runs 1.70 seconds.
Task c runs 2.92 seconds.
Thread Run Time: 2.9195945262908936
可以看出,由於是創建了限制為3的線程池,所以只有三個任務在同時執行
def write(q):
print("write(%s), 父進程為(%s)" % (os.getpid(), os.getppid()))
for i in "Python":
print("Put %s to Queue" % i)
q.put(i)
def read(q):
print("read(%s), 父進程為(%s)" % (os.getpid(), os.getppid()))
for i in range(q.qsize()):
print("read 從 Queue 獲取到消息: %s" % q.get(True))
def test_commun():
print("(%s) start" % os.getpid())
q = Manager().Queue()
pw = Process(target=write, args=(q, ))
pr = Process(target=read, args=(q, ))
pw.start()
pr.start()
pw.join()
pr.terminate()
output
(23544) start
write(29856), 父進程為(23544)
Put P to Queue
Put y to Queue
Put t to Queue
Put h to Queue
Put o to Queue
Put n to Queue
read(25016), 父進程為(23544)
read 從 Queue 獲取到消息: P
read 從 Queue 獲取到消息: y
read 從 Queue 獲取到消息: t
read 從 Queue 獲取到消息: h
read 從 Queue 獲取到消息: o
read 從 Queue 獲取到消息: n
Python 的 multiprocessing 模塊包裝了底層的機制,提供了 Queue、Pipes 等多種方式來交換數據
進程鎖:是為了控制同一操作系統中多個進程訪問一個共享資源,只是因為程序的獨立性,各個進程是無法控制其他進程對資源的訪問的,但是可以使用本地系統的信號量控制。 信號量(Semaphore),有時被稱為信號燈,是在多線程環境下使用的一種設施,是可以用來保證兩個或多個關鍵代碼段不被並發調用
線程鎖:當多個線程幾乎同時修改一個共享數據的時候,需要進行同步控制,線程同步能夠保證多個線程安全的訪問競爭資源(全局內容),最簡單的同步機制就是使用互斥鎖。 某個線程要更改共享數據時,先將其鎖定,此時資源的狀態為鎖定狀態,其他線程就能更改,直到該線程將資源狀態改為非鎖定狀態,也就是釋放資源,其他的線程才能再次鎖定資源。互斥鎖保證了每一次只有一個線程進入寫入操作。從而保證了多線程下數據的安全性
並行:多個 CPU 核心,不同的程序就分配給不同的 CPU 來運行。可以讓多個程序同時執行
並發:單個 CPU 核心,在一個時間切片裡一次只能運行一個程序,如果需要運行多個程序,則串行執行
ThreadLocal 叫做線程本地變量,ThreadLocal 在每一個變量中都會創建一個副本,每個線程都可以訪問自己內部的副本變量,對其他線程時不可見的,修改之後也不會影響到其他線程
域名解析是指將域名解析為 IP 地址。也有反向的“逆解析”,將 IP 通過 DNS 服務器查找到對應的域名地址
DNS 是域名系統 (Domain Name System),域名系統為因特網上的主機分配域名地址和 IP 地址。用戶使用域名地址,該系統就會自動把域名地址轉為 IP 地址
LVS 是 Linux Virtual Server 的簡寫,意即 Linux 虛擬服務器,是一個虛擬的服務器集群系統,即負載均衡服務器
LVS 工作模式分為 NAT 模式、TUN 模式、以及 DR 模式
Nginx 主要功能:1、反向代理 2、負載均衡 3、HTTP 服務器(包含動靜分離) 4、正向代理
正向代理:某些情況下,代理用戶去訪問服務器,需要手動設置代理服務器的 IP 和端口號
反向代理:是用來代理服務器的,代理要訪問的目標服務器。代理服務器接受請求,然後將請求轉發給內部網絡的服務器(集群化),並將從服務器上得到的結果返回給客戶端,此時代理服務器對外就表現為一個服務器
負載均衡服務器類似於 LVS HTTP 服務器類似於 Tomcat 等
HAProxy 提供高可用性、負載均衡,以及基於 TCP 和 HTTP 的應用程序代理。 keepalived 是集群管理中保證集群高可用的一個服務軟件,其功能類似於 heartbeat,用來防止單點故障
RPC 是指遠程過程調用,也就是說兩台服務器 A,B,一個應用部署在 A 服務器上,想要調用 B 服務器上應用提供的函數/方法,由於不在一個內存空間,不能直接調用,需要通過網絡來表達調用的語義和傳達調用的數據
浏覽器通過 DNS 服務器查找到域名對應的 IP 地址
浏覽器給 IP 對應的 web 服務器發送 HTTP 請求
web 服務器接收到 HTTP 請求後,返回響應給浏覽器
浏覽器接收到響應後渲染頁面
CDN 的全稱是 Content Delivery Network,即內容分發網絡。CDN 是構建在網絡之上的內容分發網絡,依靠部署在各地的邊緣服務器,通過中心平台的負載均衡、內容分發、調度等功能模塊,使用戶就近獲取所需內容,降低網絡擁塞,提高用戶訪問響應速度和命中率。CDN 的關鍵技術主要有內容存儲和分發技術
關系型數據庫:MySQL,Oracle,SQLServer,SQLite,DB2
非關系型數據庫:MongoDB,Redis,HBase,Neo4j
建立科學的,規范的的數據庫是需要滿足一些規范的,以此來優化數據數據存儲方式,在關系型數據庫中這些規范就可以稱為范式
第一范式:當關系模式 R 的所有屬性都不能在分解為更基本的數據單位時,稱 R 是滿足第一范式的,簡記為 1NF
關系模式R的所有屬性不能再分解
第二范式:如果關系模式 R 滿足第一范式,並且 R 的所有非主屬性都完全依賴於 R 的每一個候選關鍵屬性,稱 R 滿足第二范式,簡記為 2NF
非主屬性都要依賴於每一個關鍵屬性
三范式:設 R 是一個滿足第一范式條件的關系模式,X 是 R 的任意屬性集,如果 X 非傳遞依賴於 R 的任意一個候選關鍵字,稱 R 滿足第三范式,簡記為 3NF
數據不能存在傳遞關系,即每個屬性都跟主鍵有直接關系而不是間接關系
事務(Transaction)是並發控制的基本單位。所謂的事務,它是一個操作序列,這些操作要麼都執行,要麼都不執行,它是一個不可分割的工作單位
在關系數據庫中,一個事務可以是一條 SQL 語句、一組 SQL 語句或整個程序。 四個屬性:原子性,一致性,隔離性和持久性
MySQL 目前主要有以下幾種索引類型:
一對一關系示例: 一個學生對應一個學生檔案材料,或者每個人都有唯一的身份證編號
一對多關系示例: 一個學生只屬於一個班,但是一個班級有多名學生
多對多關系示例: 一個學生可以選擇多門課,一門課也有多名學生
觸發器:觸發器是一個特殊的存儲過程,它是數據庫在 insert、update、delete 的時候自動執行的代碼塊
函數:數據庫中提供了許多內置函數,還可以自定義函數,實現 sql 邏輯
視圖:視圖是由查詢結果形成的一張虛擬表,是表通過某種運算得到的一個投影
存儲過程:把一段代碼封裝起來,當要執行這一段代碼的時候,可以通過調用該存儲過程來實現(經過第一次編譯後再次調用不需要再次編譯,比一個個執行 sql 語句效率高)
DML(數據操作語言)
DDL(數據定義語言)
定義主鍵和外鍵主要是為了維護關系數據庫的完整性 主鍵是能確定一條記錄的唯一標識。不能重復,不允許為空
外鍵用於與另一張表關聯。是能確定另一張表記錄的字段,用於保持數據的一致性
主鍵外鍵索引定義唯一標識一條記錄,不能重復,不允許為空表的外鍵是另一表的主鍵,外鍵可以重復,可以是空值該字段沒有重復值,但可以有空值作用用來保證數據完整性用來和其他表建立聯系提高查詢排序的速度個數只能有一個可有多個可有多個
修改配置文件,然後重啟服務生效
在linux下,vim /etc/my.cnf,在[mysqld]內容項下增加: slow_query_log = ON long_query_time = 2 # 查詢超過2秒的就會記錄
命令行,但是重啟服務後會失效 SET GLOBAL slow_query_log = 'ON'; SET GLOBAL long_query_time = 2;
mysqldump -u 用戶名 -p 數據庫名 > 導出的文件名
char:存儲定長數據很方便,CHAR 字段上的索引效率級高,必須在括號裡定義長度,可以有默認值,比如定義 char(10)
varchar:存儲變長數據,但存儲效率沒有 CHAR 高,必須在括號裡定義長度,可以有默認值
mysql 建立多列索引(聯合索引)有最左前綴的原則,即最左優先,如:
如果有一個2列的索引(col1,col2),則已經對(col1)、(col1,col2)上建立了索引
如果有一個3列索引(col1,col2,col3),則已經對(col1)、(col1,col2)、(col1,col2,col3)上建立了索引
使用or關鍵字會導致無法命中索引
左前導查詢會導致無法命中索引,如 like '%a' 或者 like '%a%' 單列索引的索引列為 null 時全值匹配會使索引失效,組合索引全為 null 時索引失效
組合索引不符合左前綴原則的列無法命中索引,如我們有4個列 a、b、c、d,我們創建一個組合索引 INDEX(a,b,c,d),那麼能命中索引的查詢為 a,ab,abc,abcd,除此之外都無法命中索引
強制類型轉換會導致索引失效
負向查詢條件會導致無法使用索引,比如 NOT IN,NOT LIKE,!= 等 如果 mysql 估計使用全表掃描要比使用索引快,則不使用索引
讀寫分離,就是將數據庫分為了主從庫,一個主庫用於寫數據,多個從庫完成讀數據的操作,主從庫之間通過某種機制進行數據的同步,是一種常見的數據庫架構
數據庫水平切分,是一種常見的數據庫架構,是一種通過算法,將數據庫進行分割的架構。一個水平切分集群中的每個數據庫,通常稱為一個“分片”。每一個分片中的數據沒有重合,所有分片中的數據並集組成全部數據。
水平切分分為庫內分表和分庫分表,是根據表內數據內在的邏輯關系,將同一個表按不同的條件分散到多個數據庫或多個表中,每個表中只包含一部分數據,從而使得單個表的數據量變小,達到分布式的效果
redis 和 memcached 都是將數據存放在內存中,都是內存數據庫。不過 memcached 還可用於緩存其他東西,例如圖片、視頻等等
redis 不僅僅支持簡單的 k/v 類型的數據,同時還提供 list,set,hash 等數據結構的存儲
分布式設定, 都可以做一主多從或一主一從
存儲數據安全,memcached 掛掉後,數據完全丟失;redis 可以定期保存到磁盤(持久化)
災難恢復,memcached 掛掉後,數據不可恢復; redis 數據丟失後可以通過 aof 恢復
redis 默認有16個數據庫,每個數據庫中的數據都是隔離的,這樣,在存儲數據的時候,就可以指定把不同的數據存儲到不同的數據庫中。 且只有單機才有,如果是集群就沒有數據庫的概念
RDB 持久化:是將 Reids 在內存中的數據庫記錄定時 dump 到磁盤上的持久化 AOF(append only file)持久化:將 Reids 的操作日志以追加的方式寫入文件
通用的三種過期策略
定時刪除 在設置 key 的過期時間的同時,為該 key 創建一個定時器,讓定時器在 key 的過期時間來臨時,對 key 進行刪除
惰性刪除 key 過期的時候不刪除,每次從數據庫獲取 key 的時候去檢查是否過期,若過期,則刪除,返回 null
定期刪除 每隔一段時間執行一次刪除過期 key 操作
redis 采用惰性刪除+定期刪除策略
限定 Redis 占用的內存,Redis 會根據自身數據淘汰策略,加載熱數據到內存。 所以,計算一下所有熱點數據大約占用的內存,然後設置一下 Redis 內存限制即可
使用 redis 第三方庫來操作
import redis
# 創建一個 redis 連接池
def redis_conn_pool():
pool = redis.ConnectionPool(host='redis-host', port=redis-port,
decode_responses=True, password='redis-pwd')
r = redis.Redis(connection_pool=pool)
return r
訂閱者
if __name__ == "__main__":
conn = redis.Redis(host='',
port=12143, password='')
ps = conn.pubsub()
ps.subscribe('chat') # 從 chat 訂閱消息
for item in ps.listen(): # 監聽狀態:有消息發布了就拿過來
if item['type'] == 'message':
print(item)
print(item['channel'])
print(item['data'])
發布者
if __name__ == "__main__":
number_list = ['300033', '300032', '300031', '300030']
signal = ['1', '-1', '1', '-1']
pool = redis.ConnectionPool(host='redis-12143.c8.us-east-1-3.ec2.cloud.redislabs.com', port=12143,
decode_responses=True, password='pkAWNdYWfbLLfNOfxTJinm9SO16eSJFx')
r = redis.Redis(connection_pool=pool)
for i in range(len(number_list)):
value_new = str(number_list[i]) + ' ' + str(signal[i])
print(value_new)
r.publish("chat", value_new)
import redis
con = redis.Redis()
con.keys(pattern='key*') # *代表通配符
class Zhan:
def __init__(self,conn):
self.conn = conn
def push(self,val):
self.conn.rpush('aaa',val)
def pop(self):
return self.conn.rpop('aaa')
class Dui:
def __init__(self,conn):
self.conn = conn
def push(self,val):
self.conn.rpush('bbb',val)
def get(self):
return self.conn.lpop('bbb')
class Xu:
def __init__(self,conn):
self.conn = conn
def push(self,val,count):
self.conn.zadd('ccc',val,count)
def get(self):
a = self.conn.zrange('ccc', 0, 0)[0]
self.conn.zrem('ccc', a)
return a
在從服務器中配置 SLAVEOF 127.0.0.1 6380 # 主服務器 IP,端口
def list_iter(name):
"""
自定義redis列表增量迭代
:param name: redis中的name,即:迭代name對應的列表
:return: yield 返回 列表元素
"""
list_count = r.llen(name)
for index in xrange(list_count):
yield r.lindex(name, index)
watch 用於在進行事務操作的最後一步也就是在執行 exec 之前對某個 key 進行監視,如果這個被監視的 key 被改動,那麼事務就被取消,否則事務正常執行
為 redis 集群設計的鎖,防止多個任務同時修改數據庫,其本質就是為集群中的每個主機設置一個會超時的字符串,當集群中有一半多的機器設置成功後就認為加鎖成功,直至鎖過期或解鎖不會有第二個任務加鎖成功
超文本傳輸協議(HTTP,HyperText Transfer Protocol)是互聯網上應用最為廣泛的一種網絡協議。HTTP 是一個客戶端和服務器端請求和應答的標准。客戶端是終端用戶,服務器端是網站。一般由 HTTP 客戶端發起一個請求,建立一個到服務器指定端口(默認是80端口)的 TCP 連接,HTTP 服務器則在那個端口監聽客戶端發送過來的請求,並給與響應
WSGI:全稱是 Web Server Gateway Interface,是一種描述 web server 如何與 web application 通信的規范。django,flask 等都遵循該協議
uwsgi:是服務器和服務端應用程序的一種協議,規定了怎麼把請求轉發給應用程序和返回; uwsgi 是一種線路協議而不是通信協議,在此常用於在 uWSGI 服務器與其他網絡服務器的數據通信
uWSGI:是一個 Web 服務器,它實現了 WSGI 協議、uwsgi、http 等協議。Nginx 中 HttpUwsgiModule 的作用是與 uWSGI 服務器進行交換
1xx: 信息
2xx:成功
3xx:重定向
4xx:客戶端錯誤
5xx:服務器錯誤
GET,POST,PUT,DELETE,PATCH 等
響應式布局是 Ethan Marcotte 在2010年5月份提出的一個概念,簡而言之,就是一個網站能夠兼容多個終端——而不是為每個終端做一個特定的版本
AJAX 是一種在無需重新加載整個網頁的情況下,能夠更新部分網頁的技術。
AJAX = 異步 JavaScript 和 XML
$(function(){
$('#send').click(function(){
$.ajax({
type: "GET",
url: "test.json",
data: {username:$("#username").val(), content:$("#content").val()},
dataType: "json",
success: function(data){
$('#resText').empty(); //清空resText裡面的所有內容
var html = '';
$.each(data, function(commentIndex, comment){
html += '<div class="comment"><h6>' + comment['username']
+ ':</h6><p class="para"' + comment['content']
+ '</p></div>';
});
$('#resText').html(html);
}
});
});
});
同源策略限制了從同一個源加載的文檔或腳本如何與來自另一個源的資源進行交互。這是一個用於隔離潛在惡意文件的重要安全機制
如果兩個頁面的協議,端口(如果有指定)和主機都相同,則兩個頁面具有相同的源。我們也可以把它稱為“協議/主機/端口 tuple”,或簡單地叫做“tuple". ("tuple" ,“元”,是指一些事物組合在一起形成一個整體,比如(1,2)叫二元,(1,2,3)叫三元)
CORS 全稱是跨域資源共享(Cross-Origin Resource Sharing),是一種 AJAX 跨域請求資源的方式,支持現代浏覽器
CSRF(Cross-site request forgery),中文名稱:跨站請求偽造,也被稱為:one click attack/session riding,縮寫為:CSRF/XSRF
輪詢
var xhr = new XMLHttpRequest();
setInterval(function(){
xhr.open('GET','/user');
xhr.onreadystatechange = function(){
};
xhr.send();
},1000)
長輪詢
function ajax(){
var xhr = new XMLHttpRequest();
xhr.open('GET','/user');
xhr.onreadystatechange = function(){
ajax();
};
xhr.send();
}
所謂 MVC 就是把 web 應用分為模型(M),控制器(C),視圖(V)三層,他們之間以一種插件似的,松耦合的方式連接在一起。 模型負責業務對象與數據庫的對象(ORM),視圖負責與用戶的交互(頁面),控制器(C)接受用戶的輸入調用模型和視圖完成用戶的請求
Django 中的 MTV 模式:
Model(模型):負責業務對象與數據庫的對象(ORM)
Template(模版):負責如何把頁面展示給用戶
View(視圖):負責業務邏輯,並在適當的時候調用 Model 和 Template,本質上與 MVC 相同
接口冪等性就是用戶對於同一操作發起的一次請求或者多次請求的結果是一致的,不會因為多次點擊而產生了副作用
簡潔,輕巧,擴展性強,自由度高
ORM 的全稱是 Object Relational Mapping,即對象關系映射。它的實現思想就是將關系數據庫中表的數據映射成為對象,以對象的形式展現,這樣開發人員就可以把對數據庫的操作轉化為對這些對象的操作
PV:是(page view)訪問量,頁面浏覽量或點擊量,衡量網站用戶訪問的網頁數量。在一定統計周期內用戶每打開或刷新一個頁面就記錄1次,多次打開或刷新同一頁面則浏覽量累計
UV:是(Unique Visitor)獨立訪客,統計一段時間內訪問某站點的用戶數(以cookie為依據)
supervisor 管理進程,是通過 fork/exec 的方式將這些被管理的進程當作 supervisor 的子進程來啟動,所以我們只需要將要管理進程的可執行文件的路徑添加到 supervisor 的配置文件中即可
優點:
缺點:
Admin 組件:是對 model 中對應的數據表進行增刪改查提供的組件
model 組件:負責操作數據庫
form 組件:生成 HTML 代碼;數據有效性校驗;校驗信息返回並展示
ModelForm 組件:用於數據庫操作,也可用於用戶請求的驗證
使用 execute 執行自定義的 SQL 直接執行 SQL 語句(類似於 pymysql 的用法)
from django.db import connection
cursor = connection.cursor()
cursor.execute("SELECT DATE_FORMAT(create_time, '%Y-%m') FROM blog_article;")
ret = cursor.fetchall()
print(ret)
cookie 是保存在浏覽器端的鍵值對,可以用來做用戶認證
sesseion 是將用戶的會話信息保存在服務端,key 值是隨機產生的字符串,value 值是 session 的內容,依賴於 cookie 將每個用戶的隨機字符串保存到用戶浏覽器中
BeautifulSoup 庫是解析、遍歷、維護“標簽樹”的功能庫
url = "http://www.baidu.com/"
request = requests.get(url)
html = request.content
soup = BeautifulSoup(html, "html.parser", from_encoding="utf-8")
Selenium 是模擬操作浏覽器的庫,可以根據我們的指令,讓浏覽器自動加載頁面,獲取需要的數據,甚至頁面截屏,或者判斷網站上某些動作是否發生等
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
print(browser.page_source) # browser.page_source 是獲取網頁的全部 html
browser.close()
好了,這就是今天分享的全部內容,如果喜歡就點個贊吧~
後台回復“面試題”獲取完整PDF版本