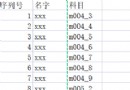
歡迎小伙伴的點評,相互學習、互關必回、全天在線
博主🧑🧑 總結了近期學習python 爬蟲的心得,10分鐘入門爬蟲,文章如下
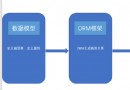
網絡爬蟲的流程其實非常簡單,主要可以分三個部分:
獲取網頁:就是給一個網址發送請求,該網址會返回整個網頁的數據。類似與在浏覽器中鍵入網址並按回車鍵,然後可以看到網站的整個頁面。
解析網頁:就是從整個網頁的數據中提取想要的數據。類似於你在頁面中想找到產品的價格,價格就是你要提取的數據。
存儲數據:就是把數據存儲下來。我們可以存儲csv中,也可以存儲在數據庫中。
獲取網頁的基礎技術:requests、urllib和selenium。
解析網頁的基礎技術:re正則表達式、BeautifulSoup和lxml。
存儲數據的基礎技術:存入txt文件和存入csv文件。
pip install requests
import requests
url = "http://www.baidu.com"
response = requests.get( url )
response.encoding = "utf-8" #設置接收編碼格式
print(" r的類型" + str( type(response) ) )
print(" 狀態碼是:" + str( response.status_code ) )
print(" 頭部信息:" + str( response.headers ) )
print( " 響應內容:" )
print( response.text )
#保存文件
file = open("baidu.html","w",encoding="utf") #打開一個文件,w是文件不存在則新建一個文件,這裡不用wb是因為不用保存成二進制
file.write( response.text )
file.close()
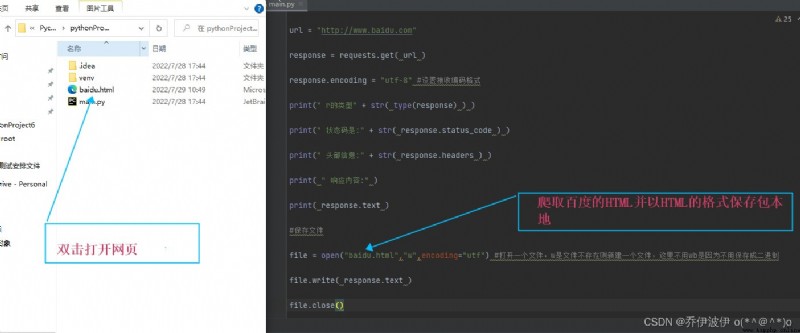
這裡有一個問題 打開頁面沒有百度logo
沒關系咱們去把logo爬下來就好了,看一下爬取的信息發現了百度的logo如下圖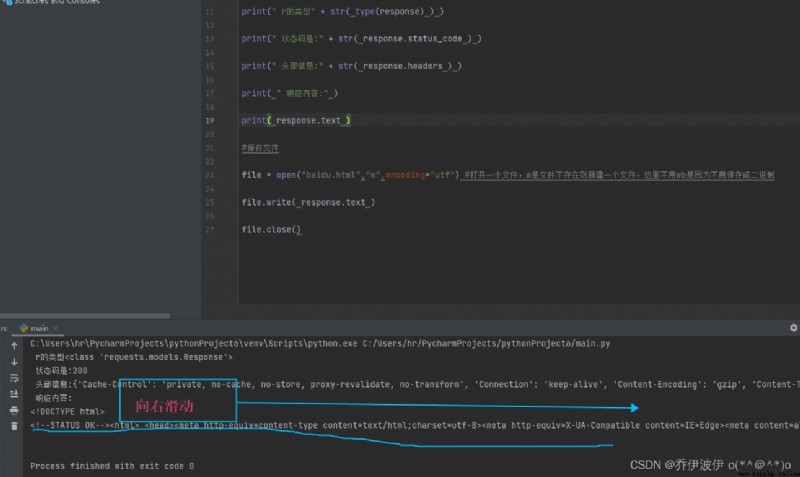
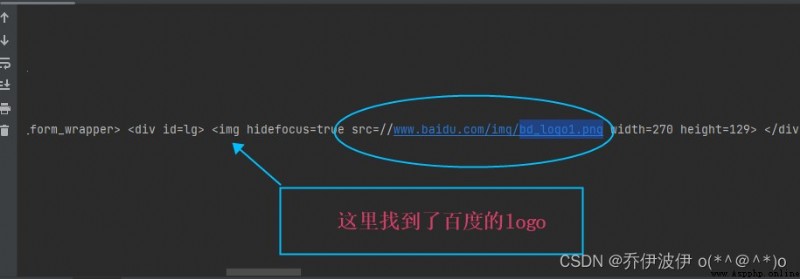
把百度logo的URL拷貝下來用來抓取圖片
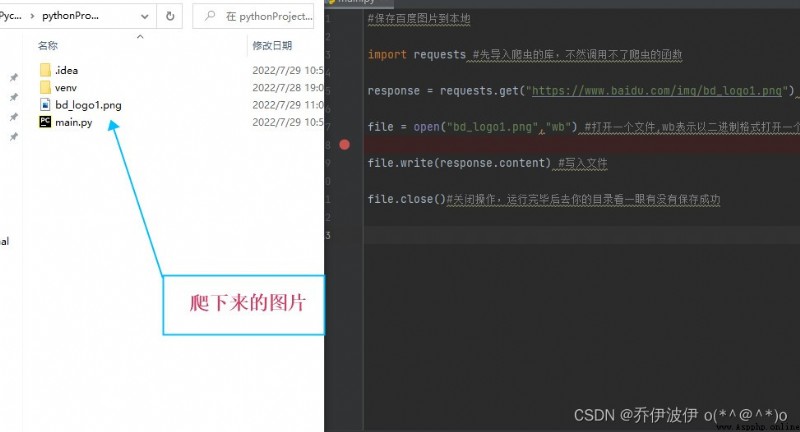
import requests #先導入爬蟲的庫,不然調用不了爬蟲的函數
response = requests.get("https://www.baidu.com/img/bd_logo1.png") #get方法的到圖片響應
file = open("bd_logo1.png","wb") #打開一個文件,保存到本地
file.write(response.content) #寫入文件
file.close()#關閉操作

對於網絡爬蟲技術的學習,我們應該從宏觀的角度出發去思考