歡迎小伙伴的點評,相互學習、互關必回、全天在線
博主🧑🧑 Summarized the recent studypython The crawler lessons,10Minute introduction to the crawler,文章如下
The process of web crawler is very simple,The main can be divided into three parts:
獲取網頁:Just send the request to a url,The url will be returned to the data of the web.Similar to type the url in your browser and press the enter key,And then can see the entire page of website.
解析網頁:Is extracted from the data of the web to data.Similar to the page you want to find the price of the product,Price is what you want to extract the data.
存儲數據:Is to store data down.我們可以存儲csv中,也可以存儲在數據庫中.
獲取網頁的基礎技術:requests、urllib和selenium.
解析網頁的基礎技術:re正則表達式、BeautifulSoup和lxml.
存儲數據的基礎技術:存入txt文件和存入csv文件.
pip install requests
import requests
url = "http://www.baidu.com"
response = requests.get( url )
response.encoding = "utf-8" #設置接收編碼格式
print(" r的類型" + str( type(response) ) )
print(" 狀態碼是:" + str( response.status_code ) )
print(" 頭部信息:" + str( response.headers ) )
print( " 響應內容:" )
print( response.text )
#保存文件
file = open("baidu.html","w",encoding="utf") #打開一個文件,w是文件不存在則新建一個文件,這裡不用wb是因為不用保存成二進制
file.write( response.text )
file.close()
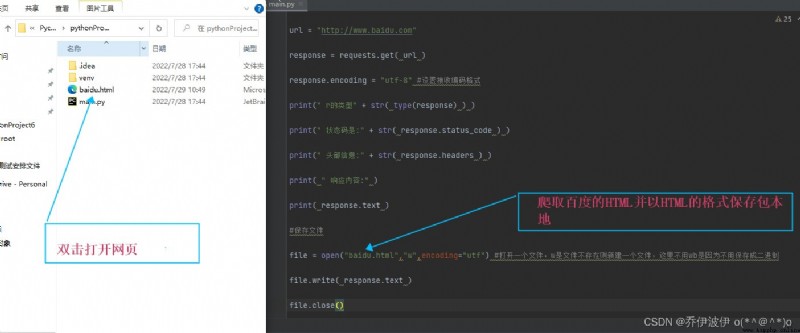
這裡有一個問題 Open the page no baidulogo
That's ok let's go to thelogoHad to climb down,Look at the information found baidu crawllogo如下圖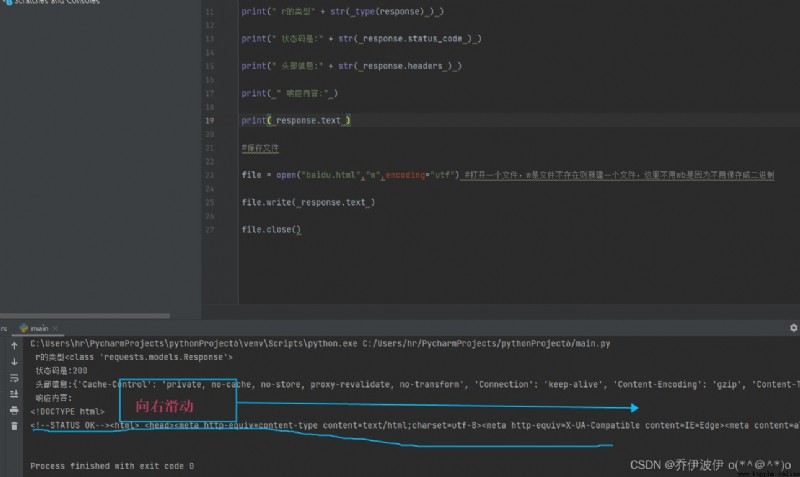
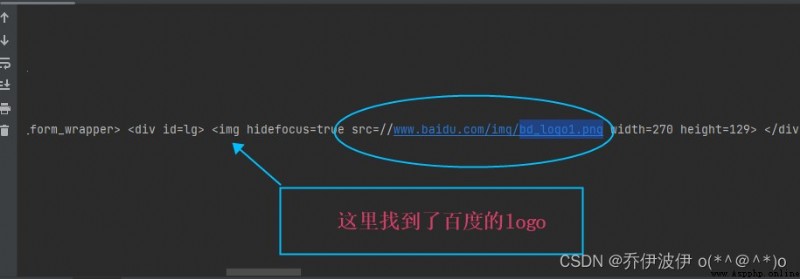
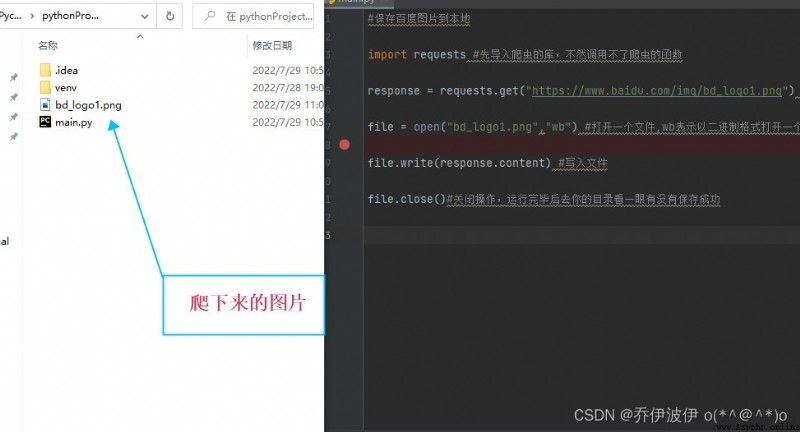
把百度logo的URLCopy down to grab images
import requests #先導入爬蟲的庫,不然調用不了爬蟲的函數
response = requests.get("https://www.baidu.com/img/bd_logo1.png") #get方法的到圖片響應
file = open("bd_logo1.png","wb") #打開一個文件,保存到本地
file.write(response.content) #寫入文件
file.close()#關閉操作

For the web crawler technology learning,We should from the macroscopic Angle to think about