這是一個使用python做的玩具代碼,個人覺得挺有意思的,是根據b站的一個up的視頻的原理講解實現的
原視頻是這個
【自制開源】520寫個小程序用女朋友的名字把她畫出來,女朋友:“這是個動物嗎?”
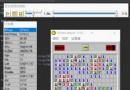
原圖參見作者頭像,轉換後結果如圖
那根據視頻裡面的原理,是這樣的
from PIL import Image
import numpy as np
from chinese_stroke_sorting import sort_by_stroke
import math
def image_binarization(self):
old_img = Image.open(self.filename)
new_img = old_img.convert('L')
return new_img
經過這個函數,可以得到一個二值化的圖片,每一個像素,都是0-255的一個值
word_arr = ['不', '夜', '熬', '要']
word_arr = sort_by_stroke(self.word_arr)
之後的word_arr就是一個根據漢字排序的列表了
根據原理,我們遍歷整個圖像矩陣,依照給的word_arr長度來平均分配漢字,什麼意思呢?以['不', '夜', '熬', '要']這個為例,像素矩陣的值是0-63的就是"不",64-127的就是"夜",128-191的就是"熬",192-255的就是"要"。
所以函數就是這樣
def to_txt(self):
word_arr = sort_by_stroke(self.word_arr)
interval = 256 / len(word_arr)
with open(self.filename.split('.')[0] + '.txt', 'w', encoding='utf-8') as f:
try:
for line in self.img_arr:
for px in line:
r = math.floor(px / interval)
f.write(word_arr[r])
else:
f.write('\n')
except IndexError as e:
print(e)
from PIL import Image
import numpy as np
from chinese_stroke_sorting import sort_by_stroke
import math
class IMG_to_TXT:
def __init__(self, filename, word_arr=None):
if word_arr is None:
word_arr = ['不', '夜', '熬', '要']
self.filename = filename
self.img_arr = None
self.word_arr = word_arr
def image_binarization(self):
old_img = Image.open(self.filename)
new_img = old_img.convert('L')
return new_img
def to_txt(self):
word_arr = sort_by_stroke(self.word_arr)
interval = 256 / len(word_arr)
with open(self.filename.split('.')[0] + '.txt', 'w', encoding='utf-8') as f:
try:
for line in self.img_arr:
for px in line:
r = math.floor(px / interval)
f.write(word_arr[r])
else:
f.write('\n')
except IndexError as e:
print(e)
def __call__(self, *args, **kwargs):
new_img = self.image_binarization()
self.img_arr = np.asarray(new_img)
self.to_txt()
if __name__ == '__main__':
i_t_txt = IMG_to_TXT(filename='cgy.png', word_arr=['一', '億', '已', '藝', '以', '衣', '異', '怡',
'宜', '咦', '姨', '益', '移', '意'])
i_t_txt()
如果想要圖片更精細一點的話,可以自定義word_arr
然後就是圖片的像素盡量不要太高,因為電腦的記事本能顯示的最大寬度是有限的,所以像素太高的話,就會導致一行的像素,不能夠以一行的文字顯示出來
細節還是挺清楚的吧