目錄
前言
一、爬取的成果:
二、目標
實現的功能:
三、獲取評論的方式
1.點贊投幣數:
2.評論
小結:
大概的步驟:
四、操作
1.引入庫
2.獲得bv號
3.得到點贊投幣等信息
4.通過bv得到url,進而得到oid參數
5.判斷+獲取置頂評論
6.獲取非置頂評論
7.最後的運行
總結:
我是一個大一剛開始敲代碼沒多久的新生,學校有個工作室安排了一些考核,然後建議我們寫點博客,這也是我第一次寫博客了,覺得以此來記錄一下自己的學習歷程還是挺有意義的。我對於很多東西理解淺薄,要是有錯誤還請多多指教。
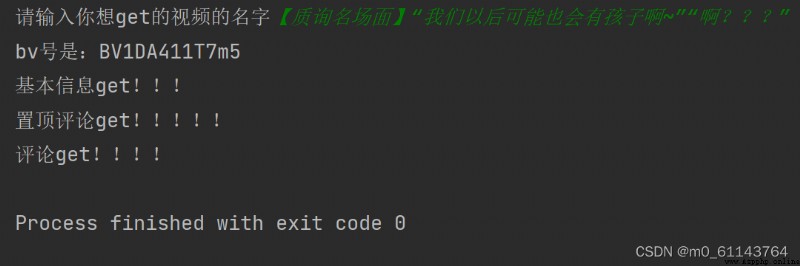
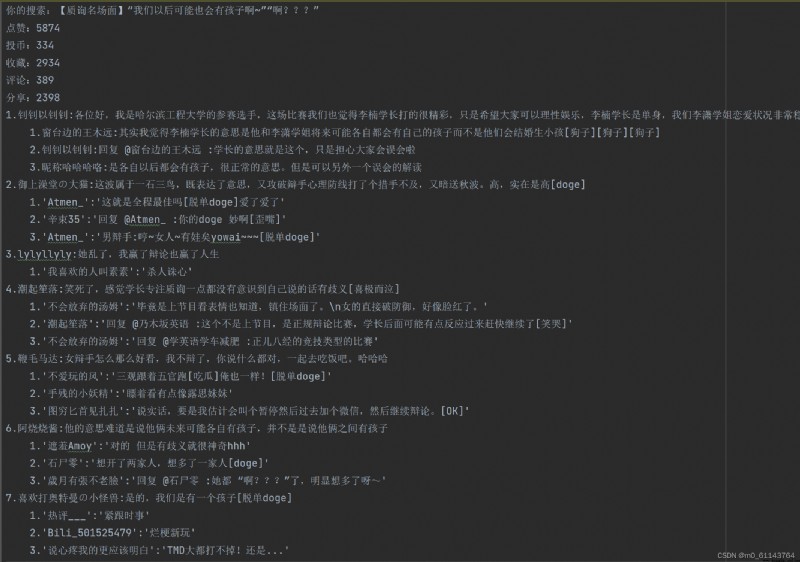
通過搜索視頻名,得到該視頻的點贊投幣數等信息,以及該視頻的評論
以搜索 【質詢名場面】“我們以後可能也會有孩子啊~”“啊???” 為例:
點f12後按ctrl+f搜索一下點贊數,發現就在網頁源代碼裡
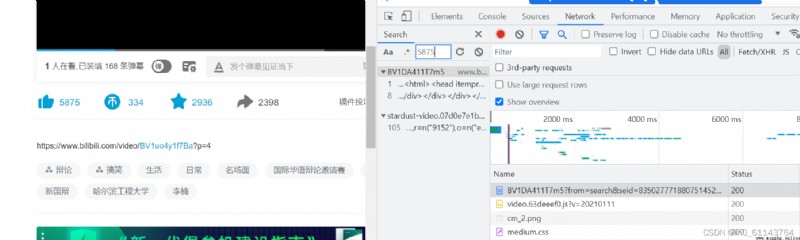
然後我們點開這個包再一次搜索點贊數
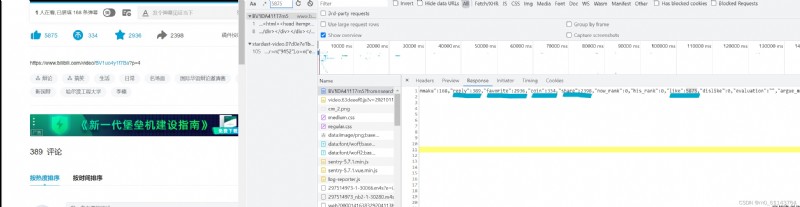
可以發現都在這裡,那就很好辦了,用正則摳下來就好了
我們搜索評論內容會發現評論不在網頁源代碼裡面

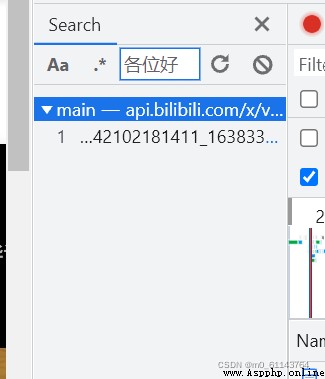

發現他的url是這個,但是就出了問題
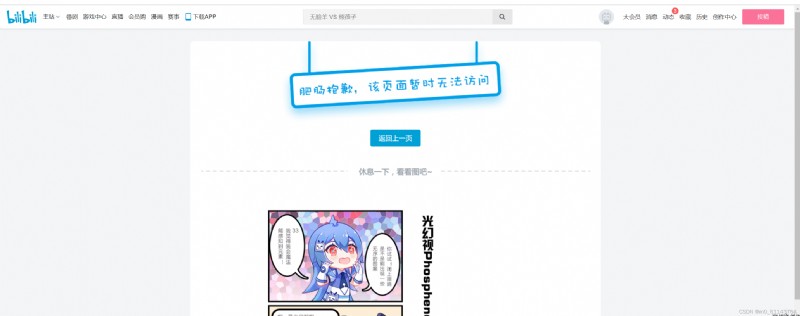
後來經過嘗試我們只需要保留
"jsonp": "jsonp", "type":1, "oid":oid, "next":page
這四個參數就好了
1.oid參數:
oid大概是每個視頻的特有的id吧。。。。我們需要從網頁源代碼裡獲取它

我們還可以發現後面跟著的bvid就是bv號,我們構造正則的時候就可以更好的定位到他
2.next參數
每一個接口是20條評論,可以通過調整next獲得更多的評論,但是怎麼知道next應該最大到多少嘞?超過了不是會報錯嗎?那我就通過try,except來解決了
所以目標很明確了,我們能夠通過bilibili主頁面搜索進入的話就能得到bv號,拿到了bv號就可以得到oid參數,通過oid參數我們可以得到含有評論的json文件,在通過,然後不管是通過索引還是正則都可以獲取到評論啦。
1、我們可以通過selenium搜索並打開搜索視頻的頁面,並且得到該視頻的bv號
2、通過bv號我們可以得到該視頻的url,用正則表達式獲得點贊投幣等信息
3、通過抓包工具我們可以知道評論的接口,每個視頻有不同地id參數,可通過網頁源代碼獲得
4、然後就是抓取評論的環節了,此時還需要判斷是否有置頂評論
import re
import requests
import json
from selenium.webdriver import Chrome
from selenium.webdriver.common.keys import Keys def getbv(search):
browser=Chrome()
browser.get('https://www.bilibili.com/') #打開bilibili
browser.maximize_window()
browser.find_element_by_tag_name('input').send_keys(f'{search}',Keys.ENTER) #輸入搜索並按下回車
windows=browser.window_handles
browser.switch_to.window(windows[-1]) #切換到新窗口
browser.find_element_by_xpath('//*[@id="all-list"]/div[1]/div[2]/ul/li/a').click()#點擊頁面第一個視頻
windows = browser.window_handles
browser.switch_to.window(windows[-1]) #切換到新窗口
obj=re.compile(r'video/(?P<bv>.*?)\?') #用正則表達式匹配bv號
bv=obj.search(browser.current_url).group('bv')
browser.close()
print('bv號是:'+bv) #讓我們看到程序拿到了bv號
return bv def info(bv,search):
url="https://www.bilibili.com/video/"+bv
headers={
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36"
}
resp=requests.get(url,headers=headers)
#用正則匹配源代碼中的點贊投幣等信息
obj=re.compile(r'"reply":(?P<comment>.*?),"favorite":(?P<collect>.*?),"coin":(?P<coin>.*?),"share":(?P<share>.*?),"now_rank".*?"like":(?P<goods>.*?),"dislike"',re.S)
result=obj.search(resp.text)
with open('b站評論.txt', mode='w', encoding='utf-8') as f: #把獲取的信息寫入文件中
f.write('你的搜索:'+search+'\n')
f.write('點贊:')
f.write(str(result.group('goods').strip()))
f.write('\n投幣:')
f.write(str(result.group('coin').strip()))
f.write('\n收藏:')
f.write(str(result.group('collect').strip()))
f.write('\n評論:')
f.write(str(result.group('comment').strip()))
f.write('\n分享:')
f.write(str(result.group('share').strip())+'\n')
print('信息get!!!') #告訴我們程序已經拿到了這些信息
resp.close() def getoid(bv):
resp=requests.get("https://www.bilibili.com/video/"+bv)
obj=re.compile(f'"aid":(?P<id>.*?),"bvid":"{bv}"') #在網頁源代碼裡可以找到id,用正則獲取到
oid=obj.search(resp.text).group('id')
print('oid是'+oid) #在程序運行時告訴我們已經獲取到了參數oid
return oid def gettopcomment(oid):
try: #需要判斷是否有置頂的評論,函數返回值為主評論計數
#如果有,之後的評論從2開始計數,則返回2
#如果沒有,之後的評論從1開始計數,則返回1
param={
"jsonp": "jsonp",
"type":1,
"oid":oid, #oid參數為上一步獲取的
"next":0
}
url="https://api.bilibili.com/x/v2/reply/main"
resp=requests.get(url,params=param)
# pprint.pprint(resp.json()) #!!!!!從這裡我們可以逐層往裡找到評論和評論人等信息
data=json.loads(resp.text)['data']
f=open('b站評論.txt',mode='a',encoding='utf-8')
f.write('1.'+data['top']['upper']['member']['uname']+':'+data['top']['upper']['content']['message']+'\n')
soncount=1
if data['top']['upper']['replies']!=None:
for i in data['top']['upper']['replies']:
f.write('\t'+f'{soncount}.'+i['member']['uname']+':'+i['content']['message']+'\n')
soncount+=1
print('置頂評論get!!!!!')
return 2
except:
print('莫得置頂評論!!')
return 1 def getcomment(oid,count):
try:
f=open('b站評論.txt',mode='a',encoding='utf-8')
page = 0
while True:
parameters={
"jsonp": "jsonp",
"type":1,
"oid":oid,
"next":page #翻面的參數
}
url="https://api.bilibili.com/x/v2/reply/main"
resp=requests.get(url,params=parameters)
data=json.loads(resp.text)['data']
#這裡構造的正則是有點雞賊的,就是將字典轉化為字符串了,然後用正則進行匹配
obj=re.compile("'uname': (?P<info>.*?), 'sex':.*?'message': (?P<content>.*?), 'plat'",re.S)
for i in data['replies']:
#這裡主評論的獲得方法跟上一個置頂評論的獲取是一樣滴
f.write(f'{count}.'+i['member']['uname']+":"+i['content']['message']+'\n')
count+=1
if i['replies'] == None:continue
#這裡面就有將字典轉化成字符串的行為了哦哦哦哦哦
ret=obj.finditer(str(i['replies']))
soncount=1 #這東西是子評論計數
for j in ret:
f.write('\t'+f'{soncount}.'+j.group('info')+":"+j.group('content')+'\n')
soncount+=1
page+=1 #在上面的參數表中有,是用於翻面的參數
except:
print('評論get!!!!')
resp.close()if __name__=='__main__':
search=input('請輸入你想get的視頻的名字')
bv = getbv(search)
info(bv,search)
oid = getoid(bv)
count=gettopcomment(oid)
getcomment(oid,count)大概就是這樣啦,,,我的知識實在匮乏,,也很難講清楚啦,就當是梳理了一遍了吧。
還請諸位大佬不吝賜教。