大家好,我是辣條哥~
過往給大家更新了不少基礎相關的,今天給大家上點硬貨,基礎不好的慎入,免得打擊你們的積極性~
其次對數據分析|數據可視化|pandas感興趣的可以來這裡刷刷題: →→→《Pandas狂刷120題》←←←
開發工具:pycharm
開發環境:python3.7, Windows10
使用工具包:requests
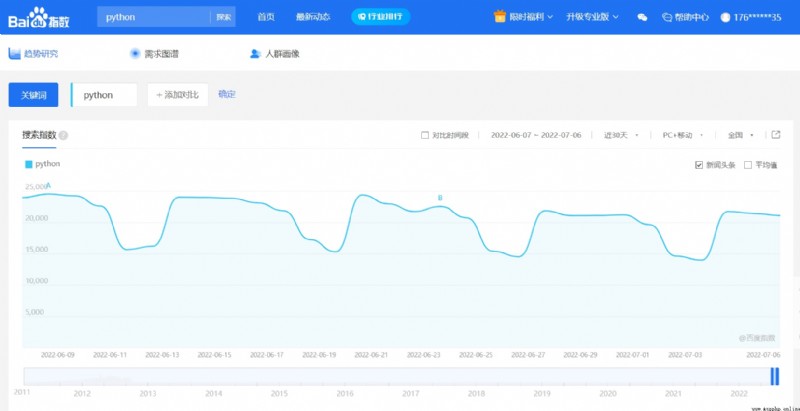
需要通過代碼來獲取到當前網頁上的曲線指數數據
這是單獨一個點,需要取出所以點的數據信息
我們獲取的數據有靜態和動態兩種,首先區分是靜態還是動態數據,在頁面鼠標右擊點擊查看網頁源代碼,在源代碼頁面來進行搜索看看我們的數據是否是存在與靜態頁面上的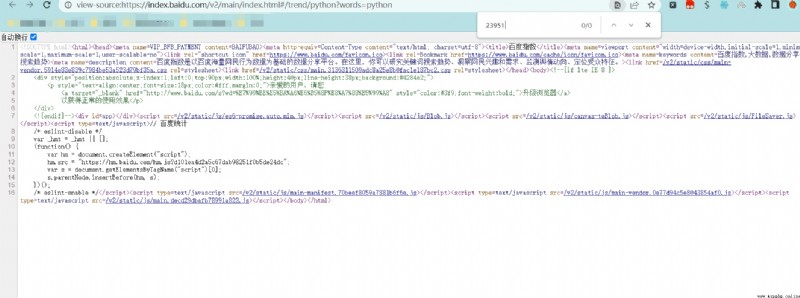
可以看到我們的數據並沒有在頁面上可以得出我們想要的數據為動態數據
動態數據的獲取我們需要使用抓包的方式來進行獲取,在浏覽器頁面鼠標右擊點擊檢查,打開我們的抓包工具,點擊network,選擇xhr選項,xhr為篩選的動態數據,刷新頁面,現在展示的就是動態數據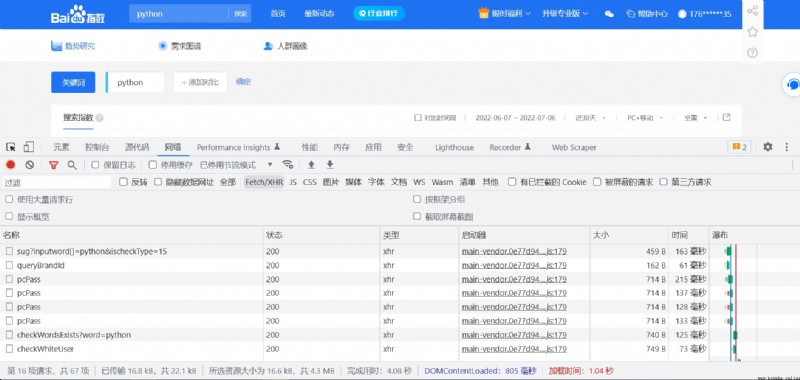
定位到我們想要的數據,要是不太熟練的可以一個個去進行確認看看那個數據是我們想要的,大致可以判斷出我們想要的數據是在當前這個請求包裡面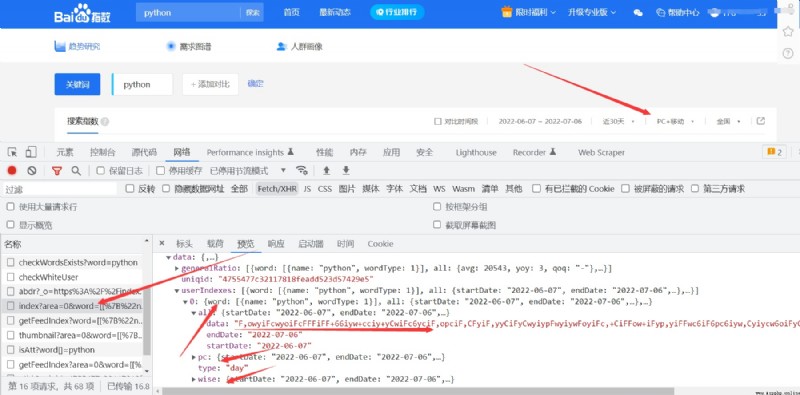
但是這個數據比較特殊,怎麼看這個數據都不像是我們想獲取的坐標點數據,可以由此得出,當前的數據為服務器加載過來的加密json數據,那我們需要考慮的就是如何去找到這個數據的解密位置,一個網頁是有html、css、js所組成的,能用來處理數據的只能在js代碼裡面我們把找到js解密位置的過程就叫做js逆向
通過全局來進行搜索定位到我們數據的位置,定位的方式有兩種服務器傳遞的數據為json信息,我們可以直接通過JSON.parse來進行定位,js代碼想處理js數據就需要通過這個關鍵字來轉換,再有我們可以通過userIndexes來進行定位,因為前端在取數據的時候一定會根據userIndexes來進行定位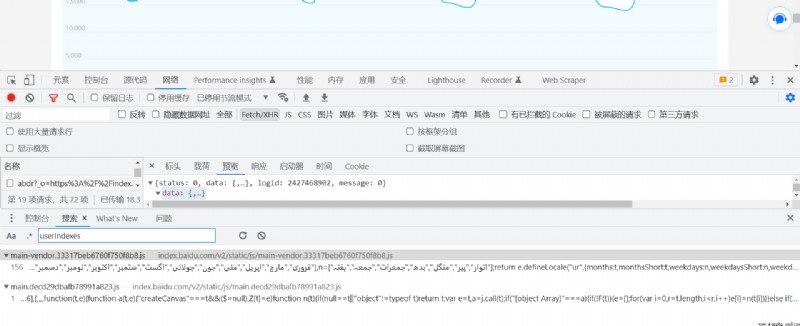
定位到的js文件有兩個,感興趣的可以一個個去進行訪問,我們要的數據在第二個文件搜索到我們想要的數據,打上斷點在進行解析,看看我們的數據是如何進行處理解密的,可以很直觀的看到下方有個decrypt函數大致推斷出是我們的解密函數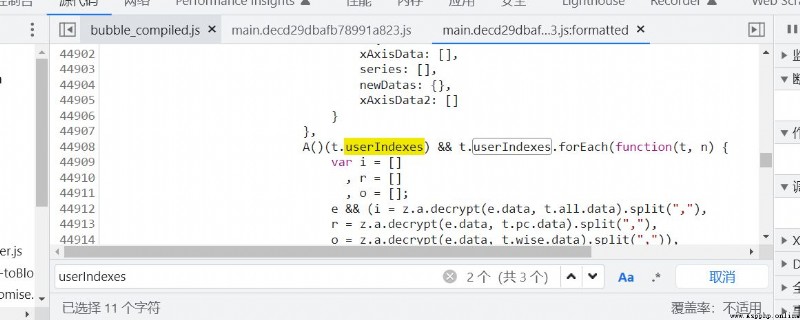
斷點之後重新刷新頁面,可以看到解密函數裡面傳遞了兩個參數,第二個參數是我們開始抓包得到服務器傳遞過來的加密數據,第一個參數目前還不是很明確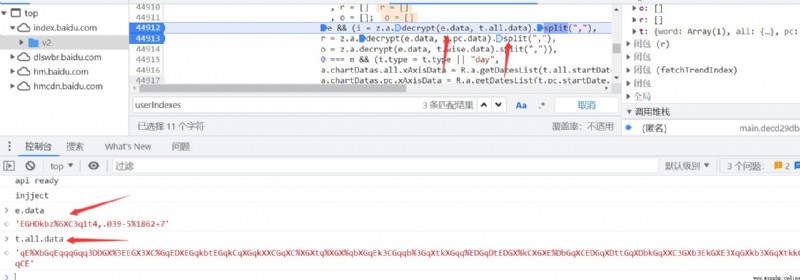
我們可以去搜索一下第一個傳遞的參數是什麼內容,可以看到我們的數據是另外一個接口請求過來的,第一個參數還需要我們對這個接口再次發送請求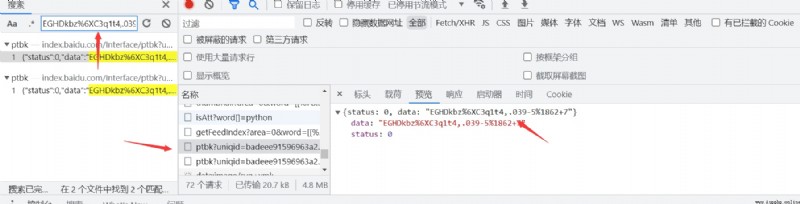
那我們的這個接口如何跟我們前面請求的數據發生關聯呢,接口數據請求的網址是根據uniqid來進行獲取的
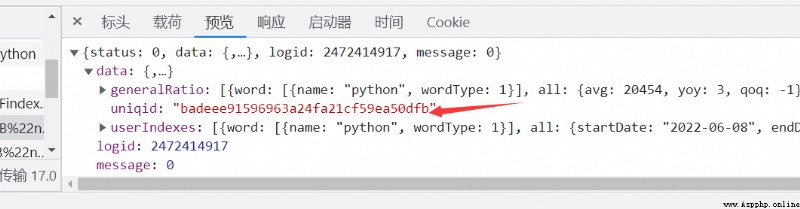
兩個參數都明確了,那我們就開始對他的js代碼來進行解析,
其實做的事情很簡單,根據加密數據的索引來進行重新排列數據,根據索引值,得出最後的曲線上的坐標數據,現在我們需要做的就是把js代碼轉換成py代碼
def decrypt(t, e):
n = list(t)
i = list(e)
a = {}
result = []
ln = int(len(n) / 2)
start = n[ln:]
end = n[:ln]
for j, k in zip(start, end):
a.update({k: j})
for j in e:
result.append(a.get(j))
return ''.join(result)
本篇文章只用於技術分享,切勿用作其他用途!!
import requests
import sys
import time
word_url = 'http://index.baidu.com/api/SearchApi/thumbnail?area=0&word={}'
headers = {
'Cipher-Text': '你的數據',
'Cookie': '你的cookie',
'Host': 'index.baidu.com',
'Referer': 'https://index.baidu.com/v2/main/index.html',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36',
# 'X-Requested-With': 'XMLHttpRequest',
}
def decrypt(t, e):
n = list(t)
i = list(e)
a = {}
result = []
ln = int(len(n) / 2)
start = n[ln:]
end = n[:ln]
for j, k in zip(start, end):
a.update({k: j})
for j in e:
result.append(a.get(j))
return ''.join(result)
def get_ptbk(uniqid):
url = 'http://index.baidu.com/Interface/ptbk?uniqid={}'
resp = requests.get(url.format(uniqid), headers=headers)
if resp.status_code != 200:
print('獲取uniqid失敗')
sys.exit(1)
return resp.json().get('data')
def get_index_data(keyword, start='2011-02-10', end='2021-08-16'):
keyword = str(keyword).replace("'", '"')
url = f'https://index.baidu.com/api/SearchApi/index?area=0&word=[[%7B%22name%22:%22python%22,%22wordType%22:1%7D]]&days=30'
resp = requests.get(url, headers=headers)
print(resp.json())
content = resp.json()
data = content.get('data')
user_indexes = data.get('userIndexes')[0]
uniqid = data.get('uniqid')
ptbk = get_ptbk(uniqid)
all_data = user_indexes.get('all').get('data')
result = decrypt(ptbk, all_data)
result = result.split(',')
print(result)
先自我介紹一下,小編13年上師交大畢業,曾經在小公司待過,去過華為OPPO等大廠,18年進入阿裡,直到現在.深知大多數初中級java工程師,想要升技能,往往是需要自己摸索成長或是報班學習,但對於培訓機構動則近萬元的學費,著實壓力不小.自己不成體系的自學效率很低又漫長,而且容易碰到天花板技術停止不前.因此我收集了一份《java開發全套學習資料》送給大家,初衷也很簡單,就是希望幫助到想自學又不知道該從何學起的朋友,同時減輕大家的負擔.添加下方名片,即可獲取全套學習資料哦