在本教程中,我們將使用 Python 以編程方式處理 SQLite3 數據庫.
SQLite 通常是一種無服務器數據庫,您可以在包括 Python 在內的幾乎所有編程語言中使用它.無服務器意味著無需安裝單獨的服務器來使用 SQLite,因此您可以直接與數據庫連接.
SQLite 是一個輕量級數據庫,它可以提供零配置的關系數據庫管理系統,因為無需配置或設置任何東西即可使用它.
我們將使用 SQLite 版本 3 或 SQLite3,所以讓我們開始吧.
目錄
要在 Python 中使用 SQLite3,首先,您必須導入_sqlite3_模塊,然後創建一個連接對象,它將我們連接到數據庫並讓我們執行 SQL 語句.
您可以使用_connect()_函數創建連接對象:
import sqlite3
con = sqlite3.connect('mydatabase.db')
這將創建一個名為“mydatabase.db”的新文件.

要在 Python 中執行 SQLite 語句,您需要一個游標對象.您可以使用_cursor()_方法創建它.
SQLite3 游標是連接對象的一種方法.要執行SQLite3語句,首先要建立連接,然後使用連接對象創建游標對象,如下所示:
con = sqlite3.connect('mydatabase.db')
cursorObj = con.cursor()
現在我們可以使用游標對象調用_execute()_方法來執行任何 SQL 查詢.
當您創建與 SQLite 的連接時,如果它不存在,它將自動創建一個數據庫文件.這個數據庫文件是在磁盤上創建的;我們還可以使用 :memory: 和 connect 函數在 RAM 中創建數據庫.該數據庫稱為內存數據庫.
考慮下面的代碼,其中我們使用_try_、_except_和_finally_塊創建了一個數據庫來處理任何異常:
import sqlite3
from sqlite3 import Error
def sql_connection():
try:
con = sqlite3.connect(':memory:')
print("Connection is established: Database is created in memory")
except Error:
print(Error)
finally:
con.close()
sql_connection()
首先,我們導入_sqlite3_模塊,然後我們定義一個函數 sql_connection.在這個函數內部,我們有一個_try_塊,_connect()_函數在建立連接後返回一個連接對象.
然後我們有_except_塊,它在任何異常的情況下都會打印錯誤消息.如果沒有錯誤,將建立連接並顯示如下消息.

之後,我們在_finally_塊中關閉了我們的連接.關閉連接是可選的,但這是一種很好的編程習慣,因此您可以從任何未使用的資源中釋放內存.
要在 SQLite3 中創建表,您可以在_execute()_方法中使用 Create Table 查詢.考慮以下步驟:
讓我們創建具有以下屬性的員工:
employees (id, name, salary, department, position, hireDate)
代碼將是這樣的:
import sqlite3
from sqlite3 import Error
def sql_connection():
try:
con = sqlite3.connect('mydatabase.db')
return con
except Error:
print(Error)
def sql_table(con):
cursorObj = con.cursor()
cursorObj.execute("CREATE TABLE employees(id integer PRIMARY KEY, name text, salary real, department text, position text, hireDate text)")
con.commit()
con = sql_connection()
sql_table(con)
在上面的代碼中,我們定義了兩個方法,第一個方法建立連接,第二個方法創建一個游標對象來執行create table語句.
在_提交()_方法保存所有我們所做的更改.最後,這兩種方法都被調用.
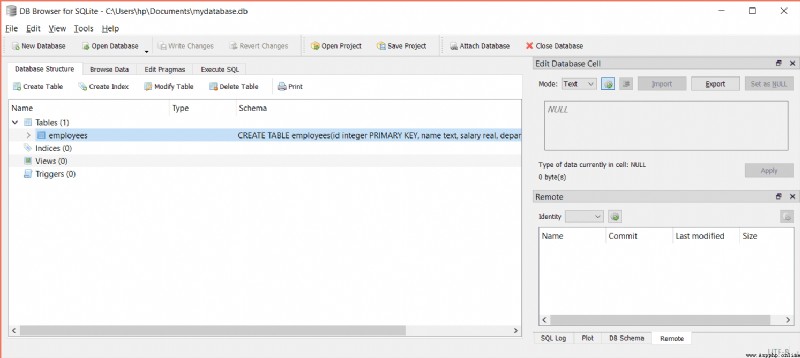
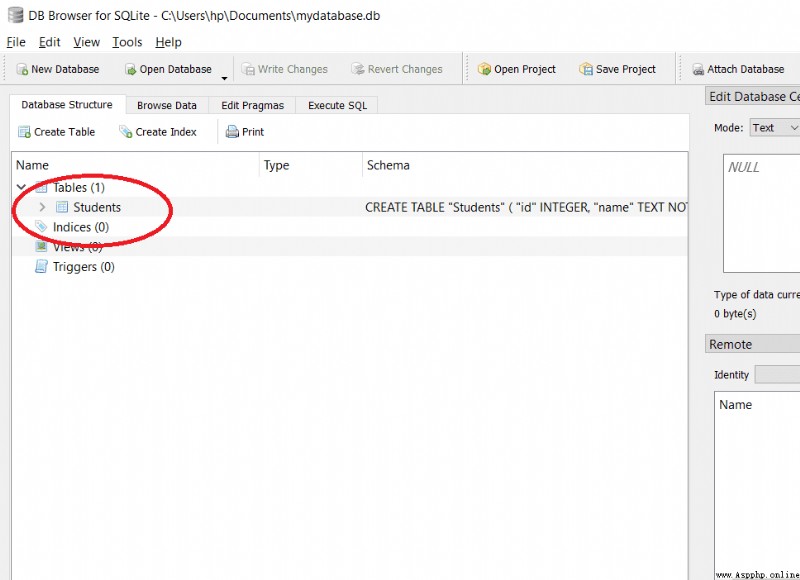
要檢查我們的表是否已創建,您可以使用SQLite的數據庫浏覽器來查看您的表.使用該程序打開 mydatabase.db 文件,您應該會看到您的表:
要在表中插入數據,我們使用 INSERT INTO 語句.考慮以下代碼行:
cursorObj.execute("INSERT INTO employees VALUES(1, 'John', 700, 'HR', 'Manager', '2017-01-04')")
con.commit()
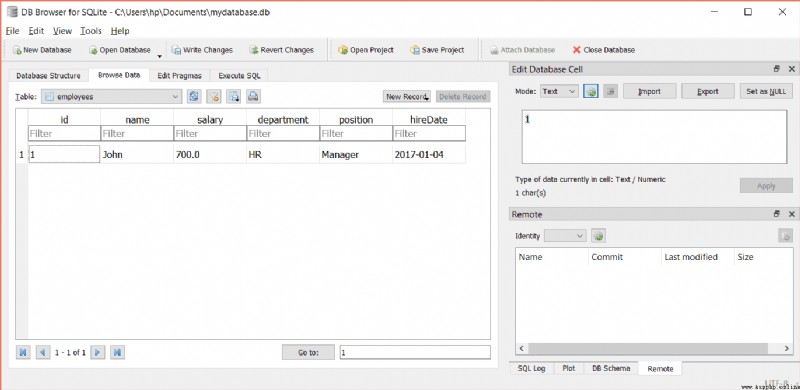
要檢查數據是否已插入,請單擊 DB Browser 中的 Browse Data:
我們還可以將值/參數傳遞給_execute()_方法中的 INSERT 語句.您可以使用問號 () 作為每個值的占位符.INSERT 的語法如下所示:
cursorObj.execute(‘’‘INSERT INTO employees(id, name, salary, department, position, hireDate) VALUES(, , , , , )’‘’, entities)
其中實體包含占位符的值如下:
entities = (2, ‘Andrew’, 800, ‘IT’, ‘Tech’, ‘2018-02-06’)
整個代碼如下:
import sqlite3
con = sqlite3.connect('mydatabase.db')
def sql_insert(con, entities):
cursorObj = con.cursor()
cursorObj.execute('INSERT INTO employees(id, name, salary, department, position, hireDate) VALUES(?, ?, ?, ?, ?, ?)', entities)
con.commit()
entities = (2, 'Andrew', 800, 'IT', 'Tech', '2018-02-06')
sql_insert(con, entities)
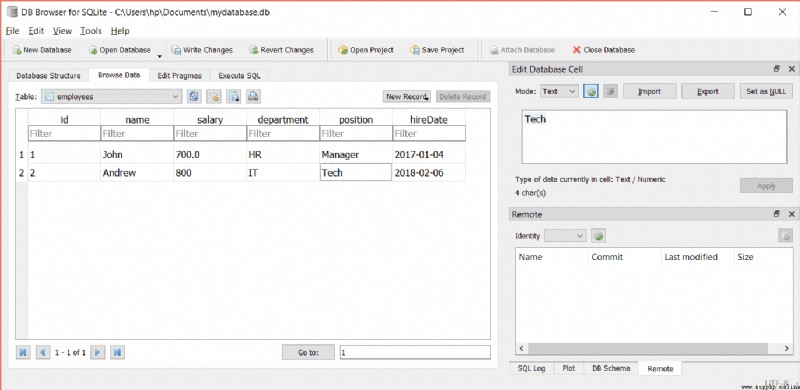
要更新表,只需創建一個連接,然後使用該連接創建一個游標對象,最後在_execute()_方法中使用 UPDATE 語句.
假設我們要更新 id 等於 2 的員工的姓名.為了更新,我們將使用 UPDATE 語句和 id 等於 2 的員工.我們將使用 WHERE 子句作為選擇該員工的條件.
考慮以下代碼:
import sqlite3
con = sqlite3.connect('mydatabase.db')
def sql_update(con):
cursorObj = con.cursor()
cursorObj.execute('UPDATE employees SET name = "Rogers" where id = 2')
con.commit()
sql_update(con)
這會將名稱從 Andrew 更改為 Rogers,如下所示:
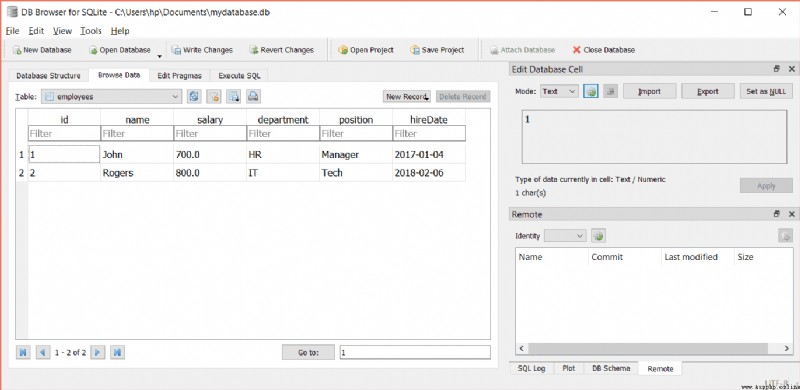
您可以使用 select 語句從特定表中選擇數據.如果要從表中選擇數據的所有列,可以使用星號 (*).其語法如下:
select * from table_name
在SQLite3中,SELECT語句是在游標對象的execute方法中執行的.例如選擇employees表的所有列,運行如下代碼:
cursorObj.execute('SELECT * FROM employees ')
如果要從表中選擇幾列,請指定如下所示的列:
select column1, column2 from tables_name
例如,
cursorObj.execute(‘SELECT id, name FROM employees’)
select語句從數據庫表中選擇需要的數據,如果要獲取選中的數據,則使用游標對象的_fetchall()_方法.我們將在下一節中演示這一點.
要從數據庫中獲取數據,我們將執行 SELECT 語句,然後使用游標對象的_fetchall()_方法將值存儲到變量中.之後,我們將遍歷變量並打印所有值.
代碼將是這樣的:
import sqlite3
con = sqlite3.connect('mydatabase.db')
def sql_fetch(con):
cursorObj = con.cursor()
cursorObj.execute('SELECT * FROM employees')
rows = cursorObj.fetchall()
for row in rows:
print(row)
sql_fetch(con)
上面的代碼會打印出我們數據庫中的記錄如下:
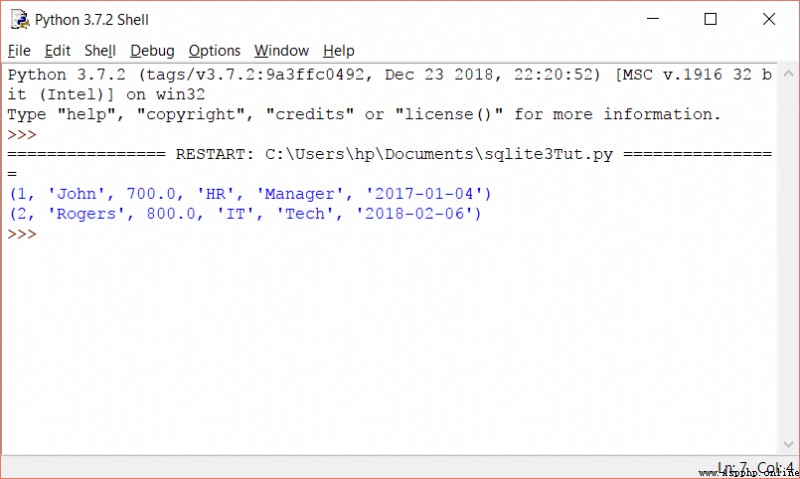
您還可以在_一行中_使用_fetchall()_,如下所示:
[print(row) for row in cursorObj.fetchall()]
如果要從數據庫中獲取特定數據,可以使用 WHERE 子句.例如,我們想要獲取工資大於 800 的員工的 id 和姓名.為此,讓我們用更多行填充我們的表,然後執行我們的查詢.
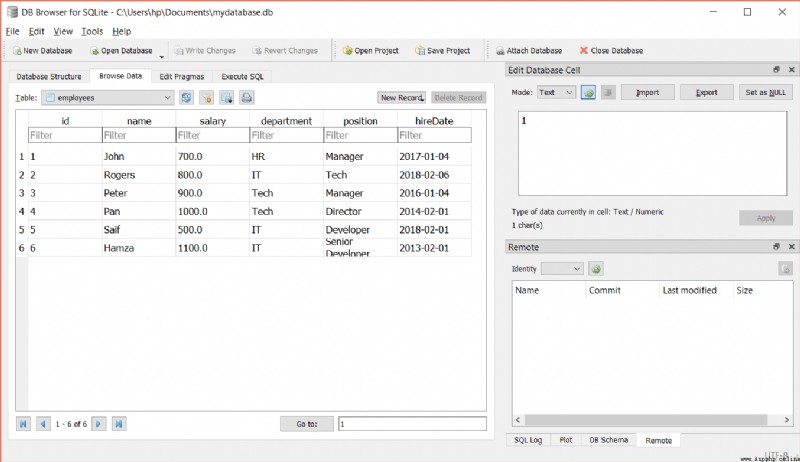
您可以使用插入語句來填充數據,也可以在 DB 浏覽器程序中手動輸入它們.
現在,要獲取工資大於 800 的人的 id 和姓名:
import sqlite3
con = sqlite3.connect('mydatabase.db')
def sql_fetch(con):
cursorObj = con.cursor()
cursorObj.execute('SELECT id, name FROM employees WHERE salary > 800.0')
rows = cursorObj.fetchall()
for row in rows:
print(row)
sql_fetch(con)
在上面的 SELECT 語句中,我們沒有使用星號 (*),而是指定了 id 和 name 屬性.結果將如下所示:
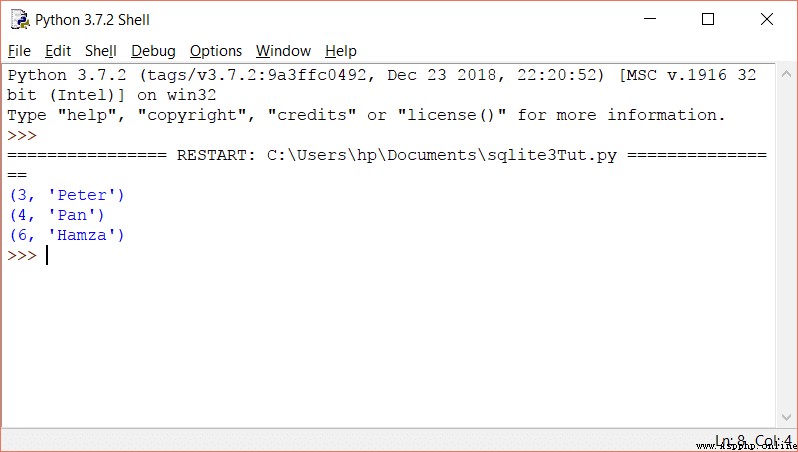
SQLite3 rowcount 用於返回最近執行的 SQL 查詢影響或選擇的行數.
當我們在 SELECT 語句中使用 rowcount 時,將返回 -1,因為在全部提取之前,選擇了多少行是未知的.考慮下面的例子:
print(cursorObj.execute(‘SELECT * FROM employees’).rowcount)
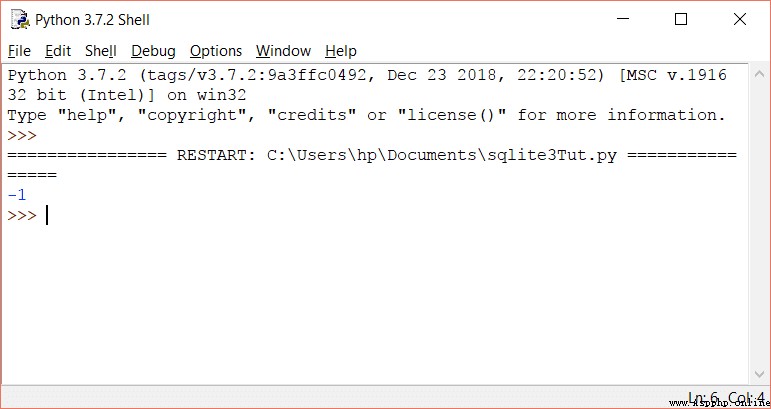
因此,要獲取行數,需要獲取所有數據,然後獲取結果的長度:
rows = cursorObj.fetchall()
print len (rows)
當您使用不帶任何條件(where 子句)的 DELETE 語句時,將刪除表中的所有行,並返回 rowcount 中已刪除行的總數.
print(cursorObj.execute(‘DELETE FROM employees’).rowcount)
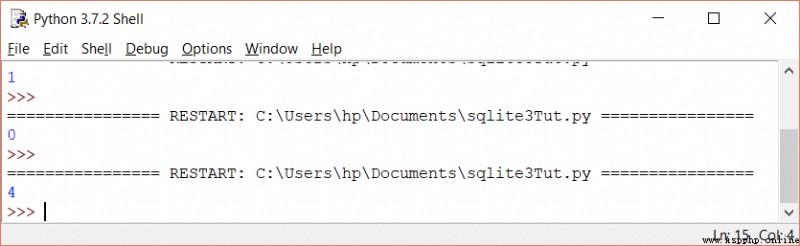
如果沒有行被刪除,它將返回零.
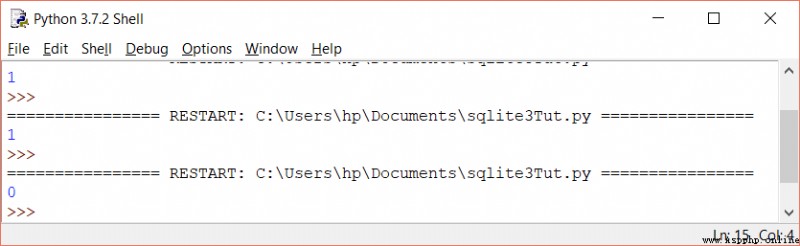
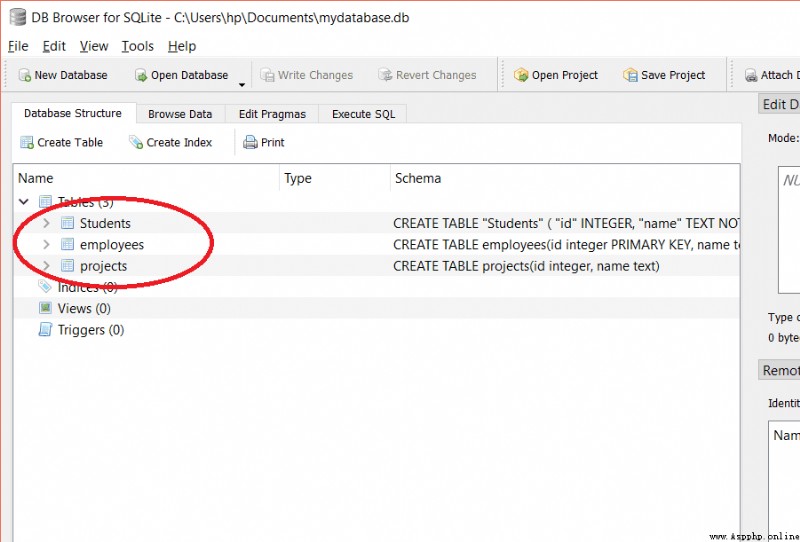
要列出 SQLite3 數據庫中的所有表,您應該查詢 sqlite_master 表,然後使用_fetchall()_從 SELECT 語句中獲取結果.
sqlite_master 是 SQLite3 中的主表,存放所有的表.
import sqlite3
con = sqlite3.connect('mydatabase.db')
def sql_fetch(con):
cursorObj = con.cursor()
cursorObj.execute('SELECT name from sqlite_master where type= "table"')
print(cursorObj.fetchall())
sql_fetch(con)
這將列出所有表,如下所示:

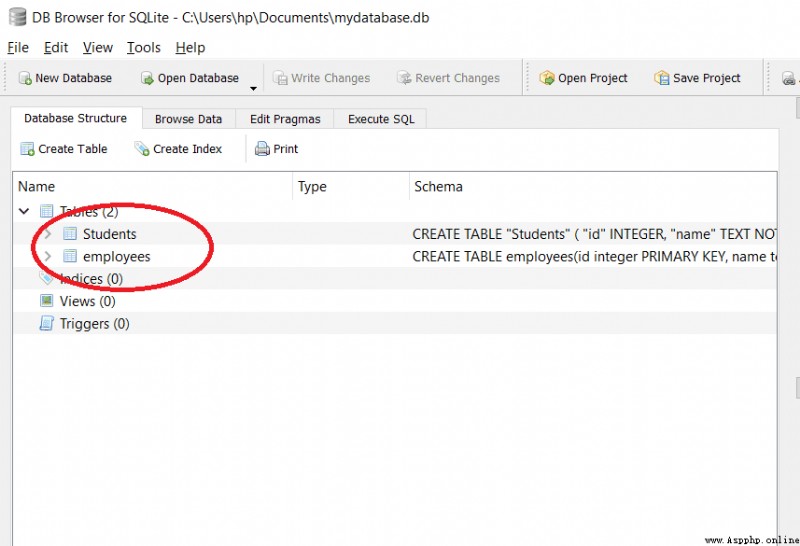
創建表時,我們應該確保該表不存在.同樣,刪除/刪除表時,該表應該存在.
為了檢查表是否已經存在,我們在 CREATE TABLE 語句中使用“if not exists”,如下所示:
create table if not exists table_name (column1, column2, …, columnN)
例如:
import sqlite3
con = sqlite3.connect('mydatabase.db')
def sql_fetch(con):
cursorObj = con.cursor()
cursorObj.execute('create table if not exists projects(id integer, name text)')
con.commit()
sql_fetch(con)
同樣,要在刪除時檢查表是否存在,我們在 DROP TABLE 語句中使用“if exists”,如下所示:
drop table if exists table_name
例如,
cursorObj.execute(‘drop table if exists projects’)
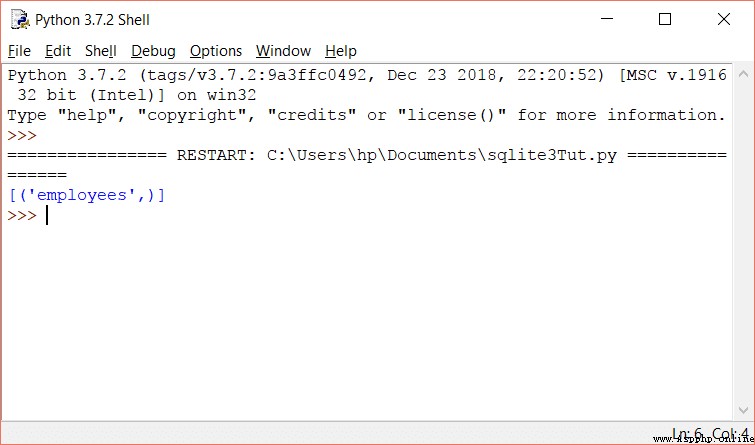
我們還可以通過執行以下查詢來檢查我們要訪問的表是否存在:
cursorObj.execute('SELECT name from sqlite_master WHERE type = "table" AND name = "employees"')
print(cursorObj.fetchall())
如果員工表存在,它將返回其名稱如下:
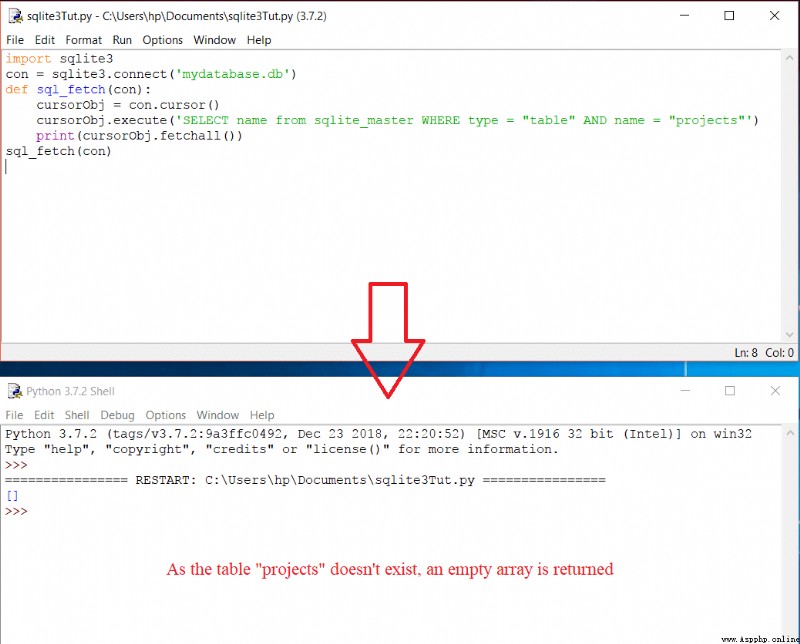
如果我們指定的表名不存在,將返回一個空數組:
您可以使用 DROP 語句刪除/刪除表.DROP 語句的語法如下:
drop table table_name
要刪除表,該表應存在於數據庫中.因此,建議在 drop 語句中使用“if exists”,如下所示:
drop table if exists table_name
例如,
import sqlite3
con = sqlite3.connect('mydatabase.db')
def sql_fetch(con):
cursorObj = con.cursor()
cursorObj.execute('DROP table if exists employees')
con.commit()
sql_fetch(con)
異常是運行時錯誤.在Python 編程中,所有異常都是從 BaseException 派生的類的實例.
在 SQLite3 中,我們有以下主要的 Python 異常:
任何與數據庫相關的錯誤都會引發 DatabaseError.
IntegrityError 是 DatabaseError 的子類,在出現數據完整性問題時會引發.例如,所有表中的外部數據均未更新,從而導致數據不一致.
當存在語法錯誤或未找到表或使用錯誤數量的參數/參數調用函數時,將引發異常 ProgrammingError.
當數據庫操作失敗時會引發此異常,例如異常斷開連接.這不是程序員的錯.
當您使用數據庫未定義或不支持的某些方法時,將引發 NotSupportedError 異常.
您可以使用 executemany 語句一次插入多行.
考慮以下代碼:
import sqlite3
con = sqlite3.connect('mydatabase.db')
cursorObj = con.cursor()
cursorObj.execute('create table if not exists projects(id integer, name text)')
data = [(1, "Ridesharing"), (2, "Water Purifying"), (3, "Forensics"), (4, "Botany")]
cursorObj.executemany("INSERT INTO projects VALUES(?, ?)", data)
con.commit()
這裡我們創建了一個有兩列的表,“data”每列有四個值.我們將變量與查詢一起傳遞給_executemany()_方法.
請注意,我們使用了占位符來傳遞值.
上面的代碼將生成以下結果:

使用完數據庫後,最好關閉連接.您可以使用_close()_方法關閉連接.
要關閉連接,請使用連接對象並調用_close()_方法,如下所示:
con = sqlite3.connect('mydatabase.db')
#program statements
con.close()
在 Python SQLite3 數據庫中,我們可以通過導入_datatime_模塊輕松存儲日期或時間.以下格式是可用於日期時間的最常見格式:
YYYY-MM-DD
YYYY-MM-DD HH:MM
YYYY-MM-DD HH:MM:SS
YYYY-MM-DD HH:MM:SS.SSS
HH:MM
HH:MM:SS
HH:MM:SS.SSS
now
考慮以下代碼:
import sqlite3
import datetime
con = sqlite3.connect('mydatabase.db')
cursorObj = con.cursor()
cursorObj.execute('create table if not exists assignments(id integer, name text, date date)')
data = [(1, "Ridesharing", datetime.date(2017, 1, 2)), (2, "Water Purifying", datetime.date(2018, 3, 4))]
cursorObj.executemany("INSERT INTO assignments VALUES(?, ?, ?)", data)
con.commit()
在這段代碼中,我們首先導入了 datetime 模塊,並創建了一個名為 assignments 的表,其中包含三列.
第三列的數據類型是日期.為了在列中插入日期,我們使用了_datetime.date_.同樣,我們可以使用_datetime.time_來處理時間.
上面的代碼將生成以下輸出:

SQLite3 數據庫的巨大靈活性和移動性使其成為任何開發人員使用它並將其與任何產品一起發布的首選.
您可以在 Windows、Linux、Mac OS、Android 和 iOS 項目中使用 SQLite3 數據庫,因為它們具有出色的可移植性.因此,您隨項目一起發送一個文件,僅此而已.
先自我介紹一下,小編13年上師交大畢業,曾經在小公司待過,去過華為OPPO等大廠,18年進入阿裡,直到現在.深知大多數初中級java工程師,想要升技能,往往是需要自己摸索成長或是報班學習,但對於培訓機構動則近萬元的學費,著實壓力不小.自己不成體系的自學效率很低又漫長,而且容易碰到天花板技術停止不前.因此我收集了一份《java開發全套學習資料》送給大家,初衷也很簡單,就是希望幫助到想自學又不知道該從何學起的朋友,同時減輕大家的負擔.添加下方名片,即可獲取全套學習資料哦