pandas數據框對象,根據索引取出自己需要的數據對象的一系列方法。
import pandas as pd
import numpy as np
df = pd.read_excel('https://www.gairuo.com/file/data/team.xlsx')
df=df[df.columns[2:]]# 本行與前一行的差值(即當前值比上一行增加了多少),無前一行的本行值為 NaN
df.diff()
df.diff(axis=1) # 向右一列
df.diff(2)
df.diff(-1) # 新的本行為本行減去後一行# 整體下移一行,最頂的一行為 NaN
df.shift()
df.shift(3) # 移三行
df.Q1.head().shift(-1)# 整體上移一行,最底的一行為 NaN
df.shift(axis=1)# 向右移動一位
df.shift(3, axis=1) # 移三位
df.shift(-1, axis=1)# 向左移動一位
# 實現了 df.Q1.diff()
df.Q1 - df.Q1.shift()# 排名, 將值變了序號數
df.rank()
df.rank(axis=1) # 橫向排名
# 相同值的排名處理:
# method='average' 並列第1 計算(1+2)/2=都是1.5,下個是3
# method='max':並列第1,顯示2,下個 3
# method='min':並列第1,顯示1,下個3
# method='dense':並列第1,顯示1,下個 2
# method='first':按索引順序看誰在索引前
df.Q1.rank(method='max')
df.rank(na_option='bottom') # 把空值放在最後
df.rank(pct=True) # 以百分比形式返回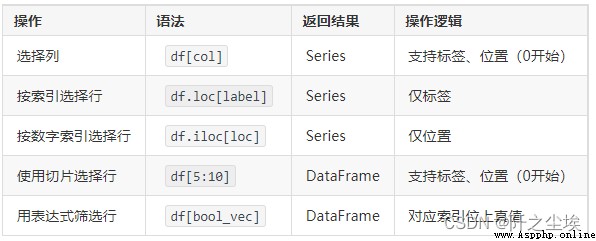
df = pd.read_excel('https://www.gairuo.com/file/data/team.xlsx')
#選一列
df['name'] # 會返回本列的 Series
df.name
type(df.Q1)#Series
df[['Q1', 'Q2']] # 選擇兩列
df[['name']] # 選擇一列,返回 DataFrame,注意和上例區別#選行
df[:2] # 前兩行數據
df[4:10]
df[:] # 所有數據,一般沒這麼用的
df[:10:2] # 按步長取
s[::-1] # 反轉順序
ser['c':'g']# 按標簽切片,包含右邊# 切行索引,如果是字符需要加引號
df.loc[0] # 選擇索引為 0 的行
df.loc[8:10] #8到10行
df.loc[[0,5,10]] # 指定索引 0,5,10 的行
df.loc['2010':'2014'] # 如果索引是時間可以用字符查詢
df.loc[['Eli', 'Ben']] # 如果索引是 name
# 真假選擇,長度要和索引一樣
df.loc[[False, True]*50] # 為真的列顯示,隔一個顯示一個##行列一起切
dft.loc[0:9, ['Q1', 'Q2']] # 10行,Q1 和 Q2兩列
dft.loc[:, ['Q1', 'Q2']] # 所有行,Q1 和 Q2兩列
dft.loc[:10, 'Q1':] # 0-10 行,Q1後邊的所有列#df.iloc 與 df.loc 相似,但只能用自然索引(行和列的 0 - n 索引),不能用標簽。
df.iloc[:3] #前三行
s.iloc[:3]
df.iloc[:] #所有行
df.iloc[2:20:3] #步長為3
df.iloc[:, [1, 2]] #所有行,1、2列
df.iloc[:3,:-2] #第三列以左,第四行以上#取一個點的值
# 注:索引是字符需要加引號
df.at[4, 'Q1'] # 65
df.at['lily', 'Q1'] # 65 假定索引是 name
df.at[0, 'name'] # 'Liver'
df.loc[0].at['name'] # 'Liver'
# 指定列的值對應其他列的值
df.set_index('name').at['Eorge', 'team'] # 'C'
df.set_index('name').team.at['Eorge'] # 'C'
# 指定列的對應索引的值
df.team.at[3] # 'C'#同樣 iat 和 iloc 一樣,僅支持數字索引:
df.iat[4, 2] # 65
df.loc[0].iat[1] # 'E'##.get 可以做類似字典的操作,如果無值給返回默認值(例中是0)
df.get('name', 0) # 是 name 列
df.get('nameXXX', 0) # 0, 返回默認值
s.get(3, 0) # 93, Series 傳索引返回具體值
df.name.get(99, 0) # 'Ben'df.truncate(before=2,after=4) #等於df.iloc[2:5,:]#pd.IndexSlice 的使用方法類似於df.loc[] 切片中的方法,常用在多層索引中,以及需要指定應用范圍(subset 參數)的函數中,特別是在鏈式方法中。
df.loc[pd.IndexSlice[:, ['Q1', 'Q2']]]
# 變量化使用
idx = pd.IndexSlice
df.loc[idx[:, ['Q1', 'Q2']]]
df.loc[idx[:, 'Q1':'Q4'], :] # 多索引# 創建復雜條件選擇器
selected = df.loc[(df.team=='A') & (df.Q1>90)]
idxs = pd.IndexSlice[selected.index, 'name']
df.loc[idxs]# 應用選擇器