Pandas data frame object, a series of methods to retrieve the data object you need according to the index.
import pandas as pdimport numpy as npdf = pd.read_excel('https://www.gairuo.com/file/data/team.xlsx')df=df[df.columns[2:]]# The difference between this row and the previous row (that is, how much the current value increases from the previous row), the value of this row without the previous row is NaNdf.diff()df.diff(axis=1) # one column to the rightdf.diff(2)df.diff(-1) # The new line is the line minus the next line# Move down one line as a whole, the top line is NaNdf.shift()df.shift(3) # shift three linesdf.Q1.head().shift(-1)# Move one line up as a whole, and the bottom line is NaNdf.shift(axis=1)# move one bit to the rightdf.shift(3, axis=1) # Shift three placesdf.shift(-1, axis=1)# move one bit to the left# Implemented df.Q1.diff()df.Q1 - df.Q1.shift()# Rank, change the value to the serial numberdf.rank()df.rank(axis=1) # Horizontal ranking# Rank processing of the same value:# method='average' tied for the first calculation (1+2)/2=both are 1.5, the next is 3# method='max': tied for 1st, display 2, next 3# method='min': tied for 1st, display 1, next 3# method='dense': tied for 1st, display 1, next 2# method='first': See who is before the index in index orderdf.Q1.rank(method='max')df.rank(na_option='bottom') # put null at the enddf.rank(pct=True) # return as a percentage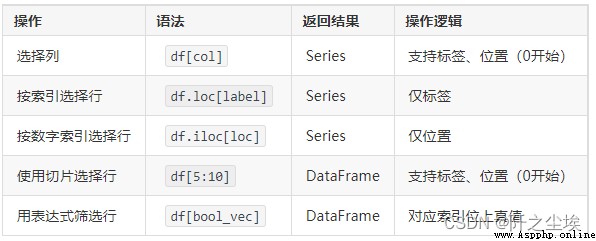
df = pd.read_excel('https://www.gairuo.com/file/data/team.xlsx')#select a columndf['name'] # will return the Series of this columndf.nametype(df.Q1)#Seriesdf[['Q1', 'Q2']] # select two columnsdf[['name']] # Select a column and return a DataFrame, note the difference from the above example#Select a linedf[:2] # first two rows of datadf[4:10]df[:] # All data, generally not so usefuldf[:10:2] # Take by steps[::-1] # reverse orderser['c':'g']# slice by label, including right # Cut the line index, if it is a character, it needs to be quoteddf.loc[0] # select the row with index 0df.loc[8:10] #8 to 10 linesdf.loc[[0,5,10]] # specify the row at index 0, 5, 10df.loc['2010':'2014'] # If the index is time, it can be queried by characterdf.loc[['Eli', 'Ben']] # if index is name# True and false selection, the length should be the same as the indexdf.loc[[False, True]*50] # True column display, every other display ## row and column cut togetherdft.loc[0:9, ['Q1', 'Q2']] # 10 rows, Q1 and Q2 columnsdft.loc[:, ['Q1', 'Q2']] # All rows, columns Q1 and Q2dft.loc[:10, 'Q1':] # Lines 0-10, all columns after Q1#df.iloc is similar to df.loc, but can only use natural indices (row and column 0-n indices), not labels.df.iloc[:3] #First three liness.iloc[:3]df.iloc[:] #all rowsdf.iloc[2:20:3] #The step size is 3df.iloc[:, [1, 2]] #All rows, 1, 2 columnsdf.iloc[:3,:-2] #The third column is to the left and the fourth row is above# Take the value of a point# Note: The index is a character that needs to be quoteddf.at[4, 'Q1'] # 65df.at['lily', 'Q1'] # 65 assumes index is namedf.at[0, 'name'] # 'Liver'df.loc[0].at['name'] # 'Liver'# The value of the specified column corresponds to the value of other columnsdf.set_index('name').at['Eorge', 'team'] # 'C'df.set_index('name').team.at['Eorge'] # 'C'# Specify the value of the corresponding index of the columndf.team.at[3] # 'C'#Also iat, like iloc, only supports numeric indexes:df.iat[4, 2] # 65df.loc[0].iat[1] # 'E'##.get can do dictionary-like operations. If there is no value, return the default value (0 in the example)df.get('name', 0) # is the name columndf.get('nameXXX', 0) # 0, return default values.get(3, 0) # 93, Series pass the index to return the specific valuedf.name.get(99, 0) # 'Ben'df.truncate(before=2,after=4) #equal to df.iloc[2:5,:]#pd.IndexSlice The usage method is similar to the method in the df.loc[] slice, which is commonly used in multi-level indexes and functions that need to specify the application range (subset parameter), especially in chained methods.df.loc[pd.IndexSlice[:, ['Q1', 'Q2']]]# variable usageidx = pd.IndexSlicedf.loc[idx[:, ['Q1', 'Q2']]]df.loc[idx[:, 'Q1':'Q4'], :] # Multi-index# Create complex conditional selectorsselected = df.loc[(df.team=='A') & (df.Q1>90)]idxs = pd.IndexSlice[selected.index, 'name']df.loc[idxs]# application selector