Pandas 是一個開源的第三方 Python 庫,從 Numpy 和 Matplotlib 的基礎上構建而來,享有數據分析“三劍客之一”的盛名(NumPy、Matplotlib、Pandas).
Pandas 已經成為 Python 數據分析的必備高級工具,它的目標是成為強大、靈活、可以支持任何編程語言的數據分析工具.
Pandas 這個名字來源於面板數據(Panel Data)與數據分析(data analysis)這兩個名詞的組合.Pandas 最初被應用於金融量化交易領域,現在它的應用領域更加廣泛,涵蓋了農業、工業、交通等許多行業
Pandas To solve the build and deal with 2 d、多維數組是一項繁瑣的任務. 在 ndarray 數組(NumPy 中的數組)On the basis of construct
兩種不同的數據結構:

pip install pandas
import pandas as pd
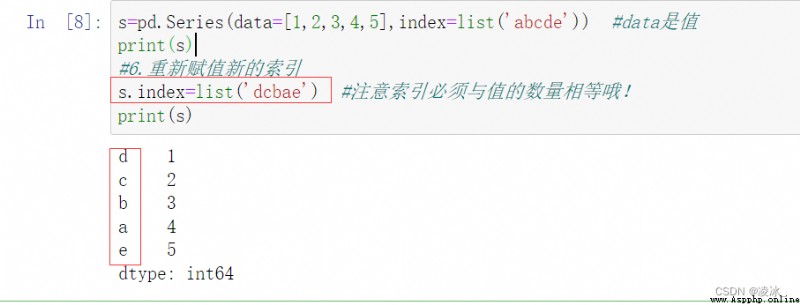
6.1 Series結構概念
Series 結構,也稱 Series 序列,是 Pandas 常用的數據結構之一,它是一種類似於一維數組的結構,由一組數據值(value)和一組標簽組成,其中標簽與數據值之間是一一對應的關系. Series 可以保存任何數據類型,比如整數、字符串、浮點數、Python 對象等,它的標簽默認為整數,從 0 開始依次遞增.
 6.2 Series對象
6.2 Series對象
使用 Series() 函數來創建 Series 對象,通過這個對象可以調用相應的方法和屬性
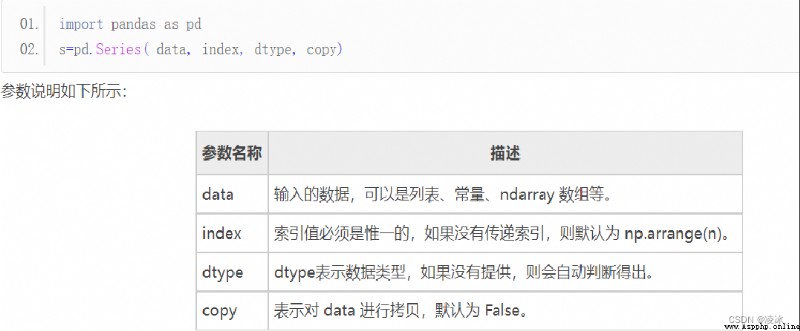 6.3 Series創建對象
6.3 Series創建對象
1、創建一個空Series對象

2、字典創建Series對象
3、數組創建Series對象
4、標量創建Series對象

6.4 Series訪問數據
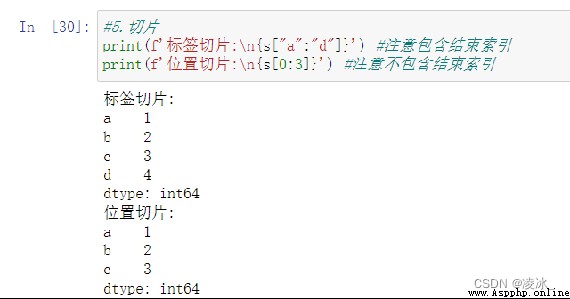
分為兩種方式: (1) 位置索引訪問 (2) The label index access

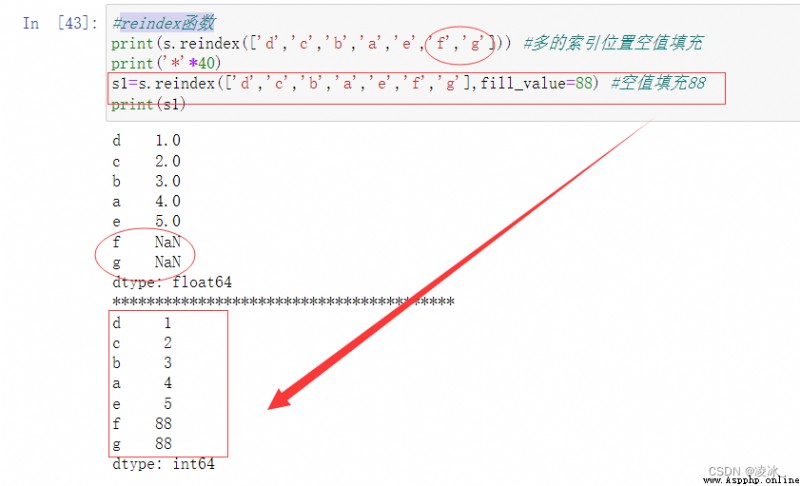
6.5 Pandas的reindex函數
返回->The data in line with the new index to construct a new object
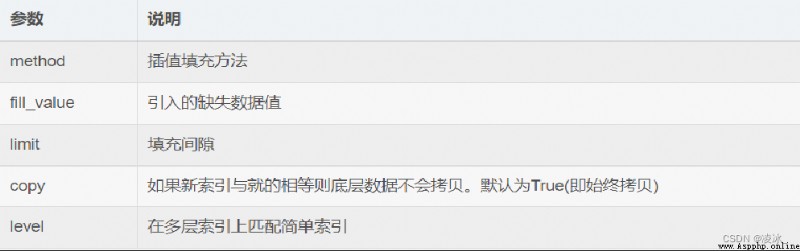
語法:DataFrame.reindex(index=None, columns=None, **kwargs)
reindex 函數的參數說明:
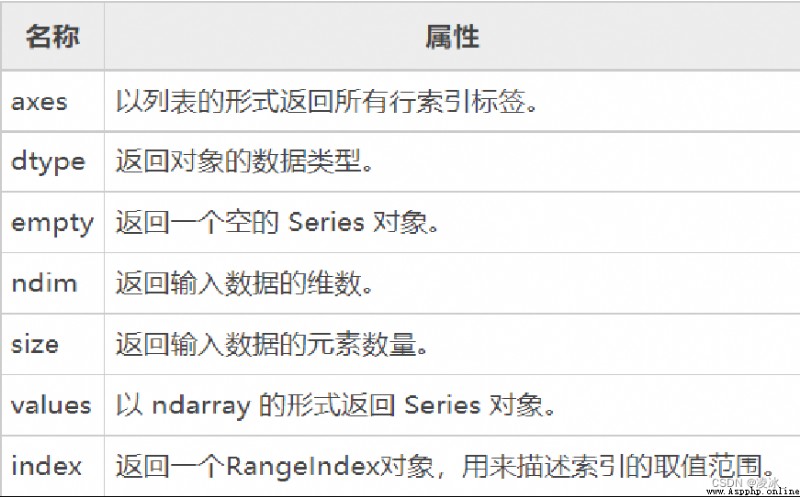
6.6 Series常用屬性
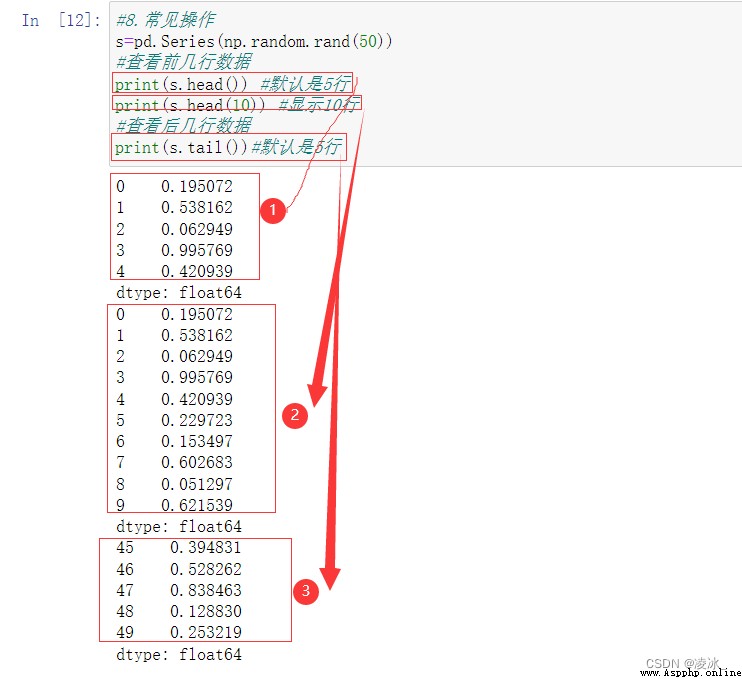
6.7 Series常用方法
1、head()、tail()查看數據
2、isnull()、nonull()檢測缺失值 所謂缺失值,顧名思義就是值不存在、丟失、缺少.

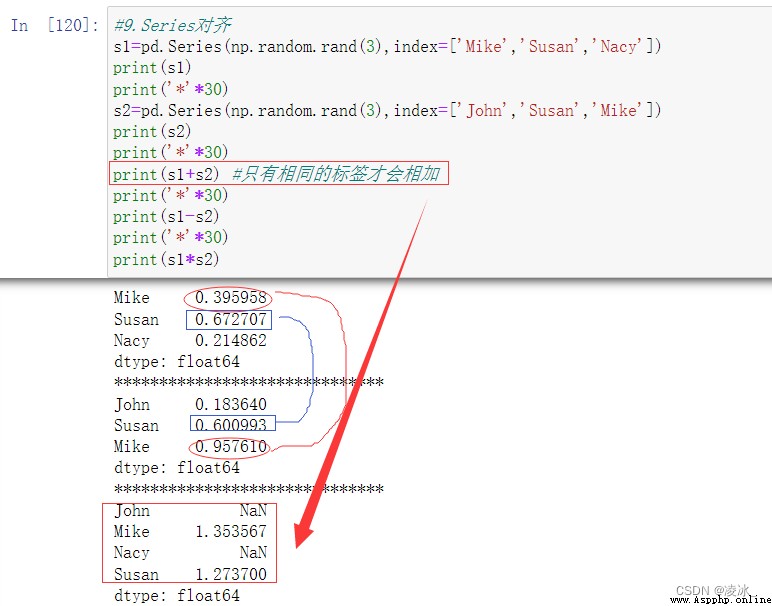
6.8 Series算術運算
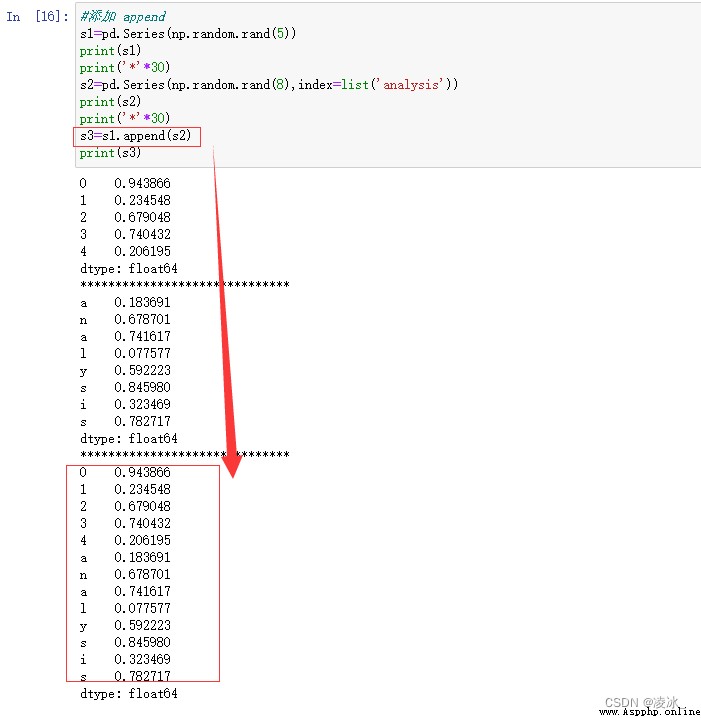
6.9 Series添加append
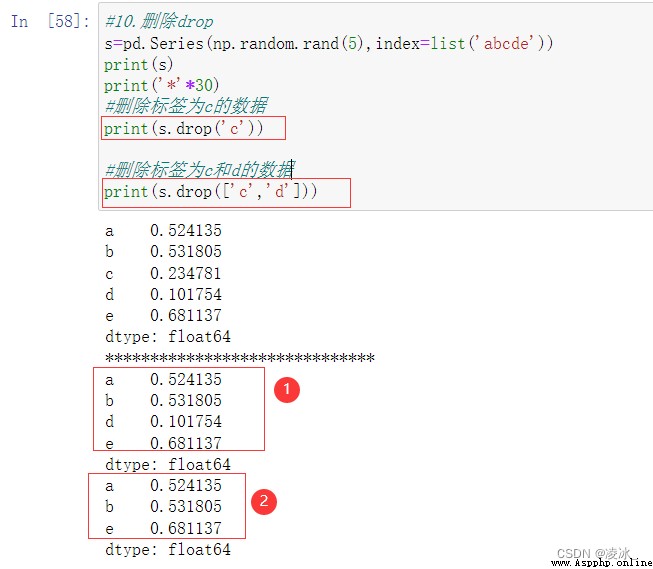
6.10 Series刪除drop
Delete data set redundant data
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')

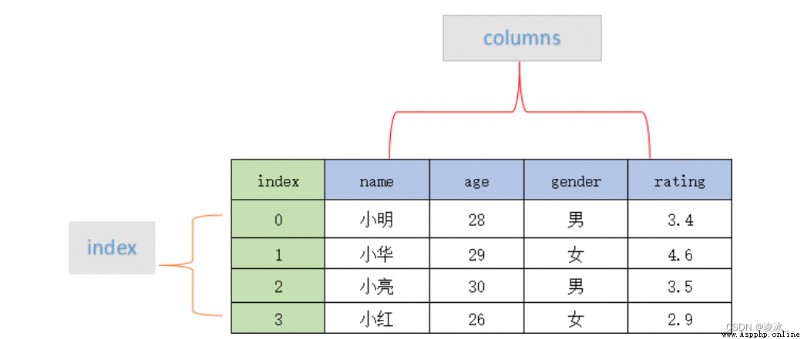
7.1 dataFrame概念
DataFrame是一個表格型的數據結構,它含有一組有序的列,每列可以是不同的值類型(數值、字符串、布爾值等).DataFrame既有行索引也有列索引,它可以被看做由Series組成的字典(共用同一個索引)
7.2 DataFrame對象
創建 DataFrame 對象的語法格式
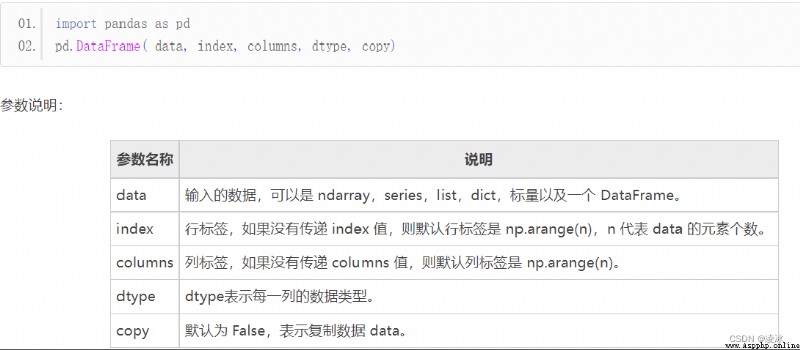
7.3 DataFrame創建對象
1、創建空對象
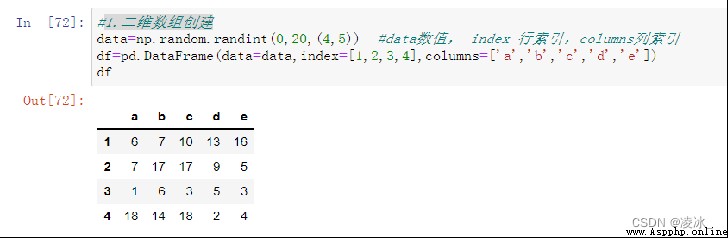
2、二維數組創建
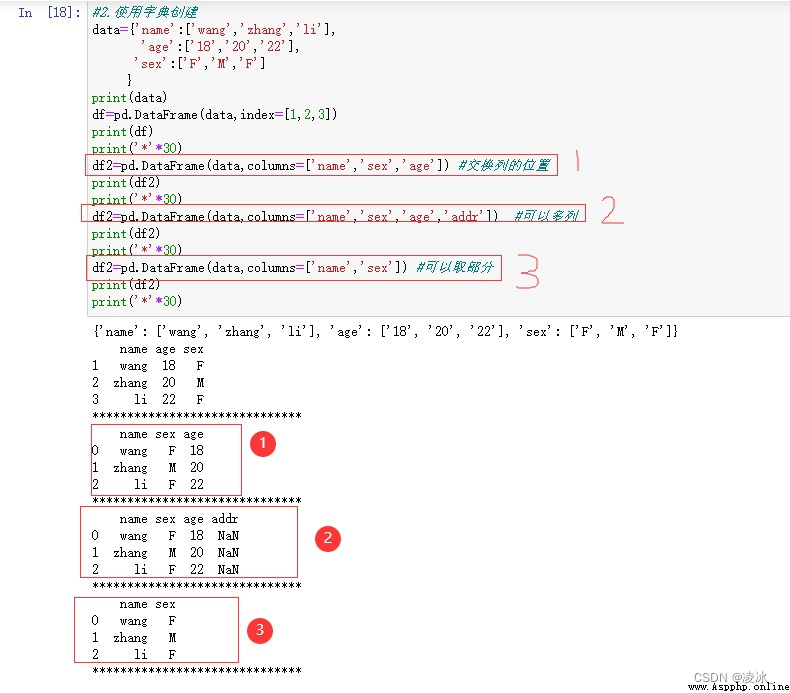
3、字典創建
4、from_dict()創建

5、列表嵌套字典創建

7.4 DataFrame常見屬性&方法


7.5 Pandas loc/iloc用法

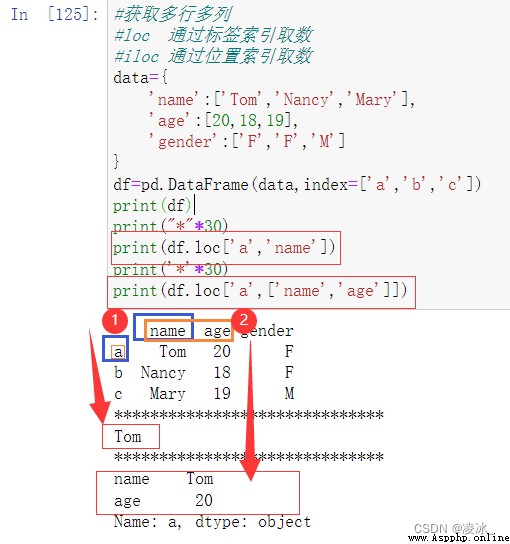
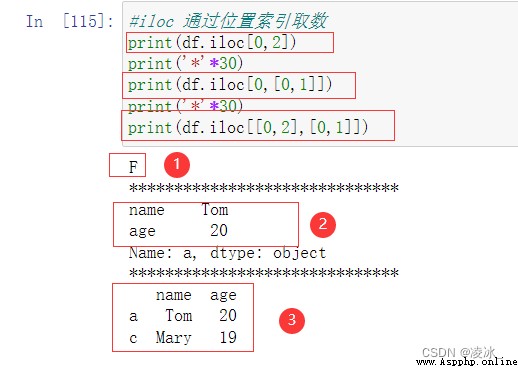
7.6 Pandas sorting排序
兩種排序方法:
1、按索引排序 sort_index(axis= , ascending= , inplace=)
2、按值排序 sort_values(by= , axis= , ascending= , inplace=)

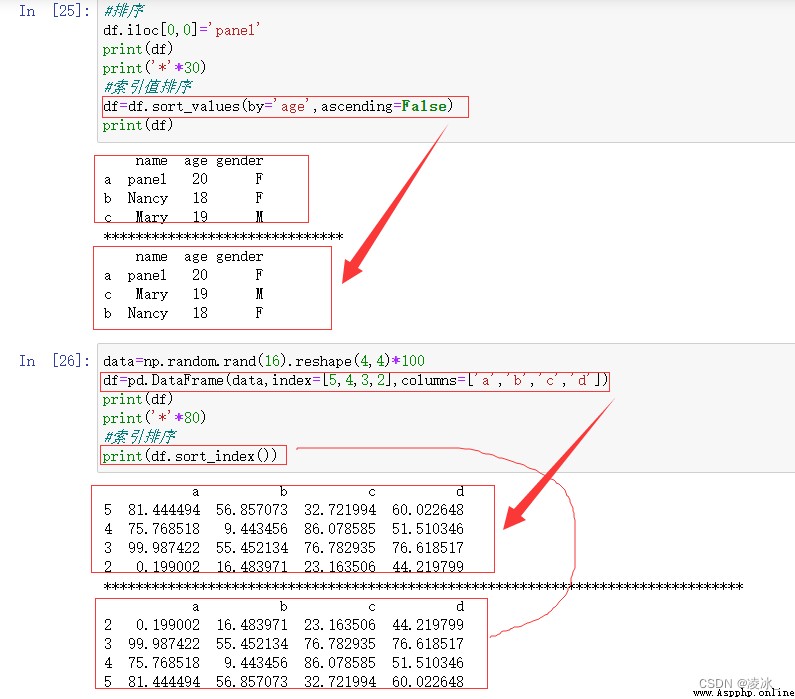
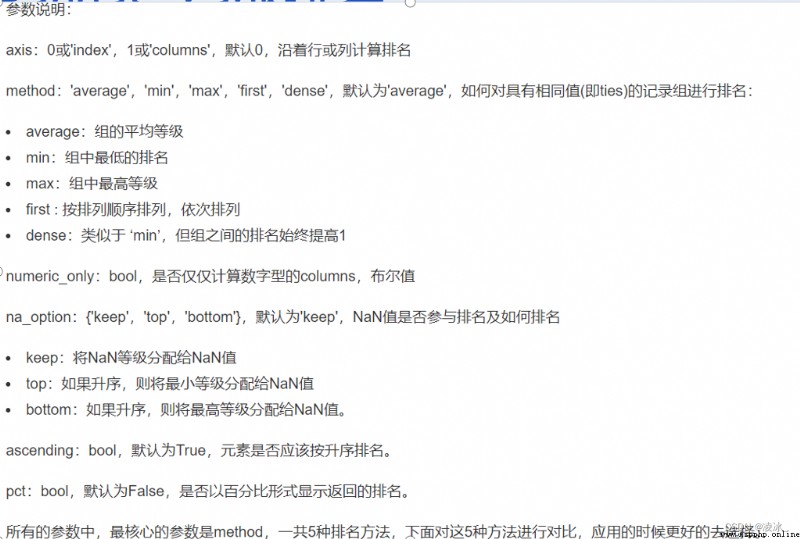
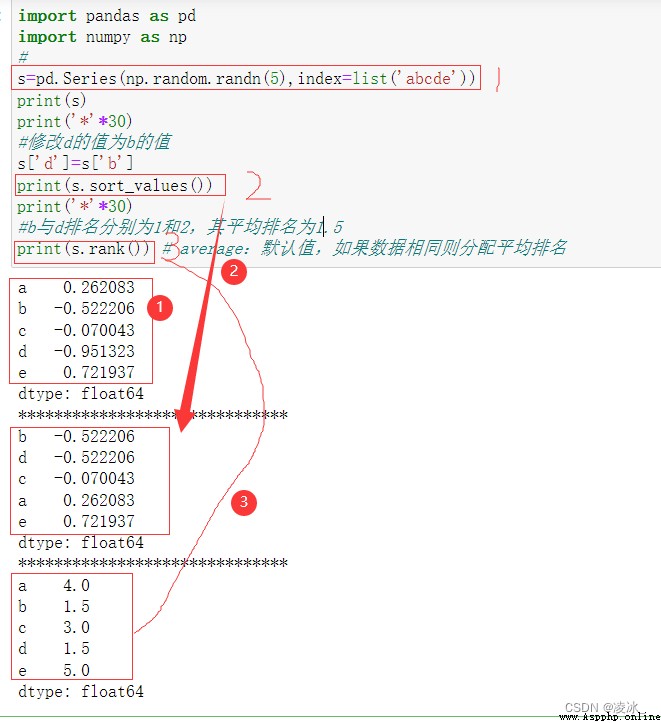
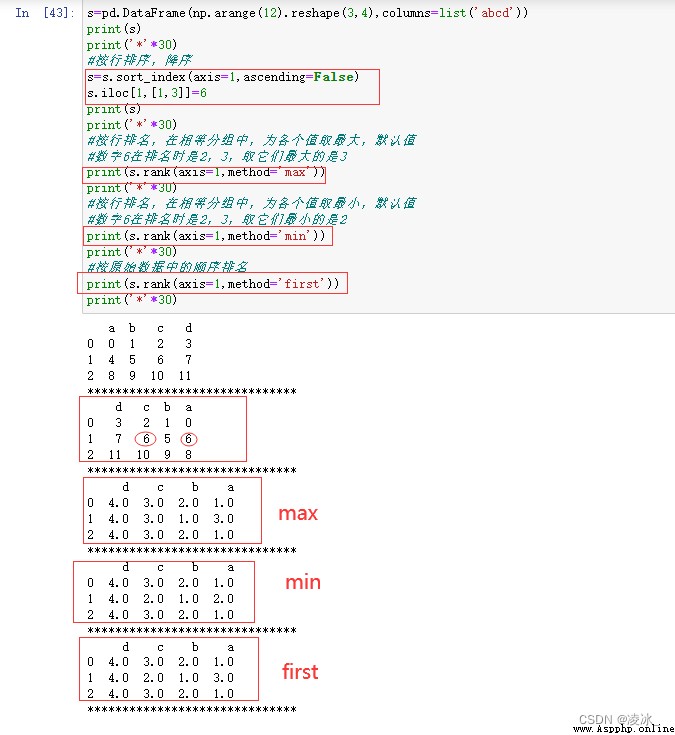
7.7 Pandas rank排名
rank函數語法:
DataFrame.rank(axis=0,method='average',numeric_only=None, na_option='keep',ascending=True,pct=False)