了解caffe,使用caffe,做個小例子熟悉caffe。
caffe Github: https://github.com/BVLC/caffe
caffe Tutorial :https://docs.google.com/presentation/d/1UeKXVgRvvxg9OUdh_UiC5G71UMscNPlvArsWER41PsU/edit#slide=id.gc2fcdcce7_216_498
why caffe: only for vision; very simple。caffe不用懂程序都能寫出模型。
擁有一個docker環境:https://github.com/BVLC/caffe/tree/master/docker
caffe mnist Tutorial :https://caffe.berkeleyvision.org/gathered/examples/mnist.html
微信二維碼opencv模型文件:https://github.com/WeChatCV/opencv_3rdparty
微信二維碼opencv源碼:https://github.com/opencv/opencv_contrib/blob/master/modules/wechat_qrcode/src/wechat_qrcode.cpp#L156
微信二維碼技術介紹:https://zhuanlan.zhihu.com/p/348412200
cpu:
cd ~
mkdir caffetest
docker run -ti -v ~/caffetest/:/app bvlc/caffe:cpu bash
代碼下載下來,宿主機執行:
cd $CAFFE_ROOT
./data/mnist/get_mnist.sh
./examples/mnist/create_mnist.sh
我沒編譯安裝caffe,執行create_mnist.sh報錯,lmdb數據格式何方神聖?:
caffe直接處理的數據分為兩種格式: lmdb和leveldb,兩者關系: 它們都是鍵/值對嵌入式數據庫管理系統編程庫
雖然lmdb的內存消耗是leveldb的1.1倍,但是lmdb的處理速度比leveldb快10%到15%,另外lmdb允許多種訓練模型同時讀取同一組數據集。
lmdb取代了leveldb成為了caffe默認的數據集生成格式。
docker 內的Linux發行版查看cat /etc/issue,
Ubuntu 16.04.4 LTS \n \l
dockerfile:https://github.com/BVLC/caffe/blob/9b891540183ddc834a02b2bd81b31afae71b2153/docker/cpu/Dockerfile
ubuntu安裝教程:http://caffe.berkeleyvision.org/install_apt.html
ubuntu的update太慢了,這條路以後再走。
我想在python裡面調用起二維碼檢測的代碼,不用識別二維碼,只進行目標檢測。
在線可視化prototxt模型:http://ethereon.github.io/netscope/#/editor
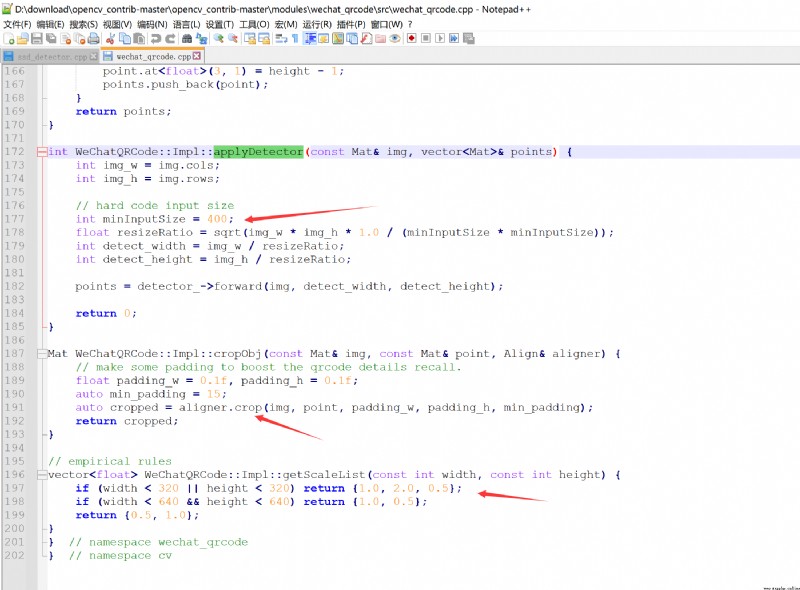
看源碼: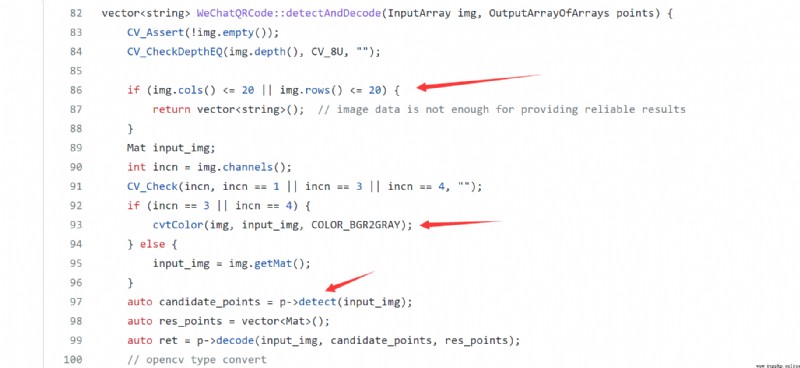
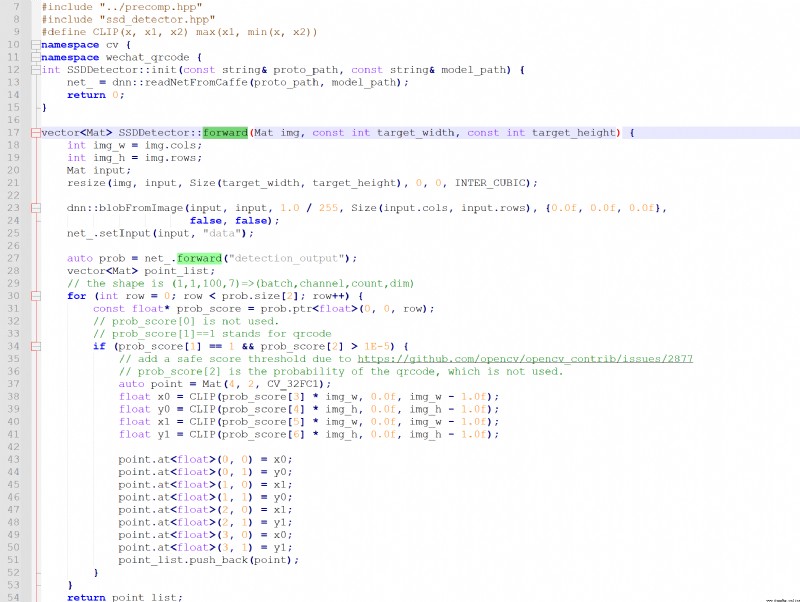
輸入圖像的處理需要:
(1)太小就不要了,他這是為了二維碼解碼,這步不管。
(2)灰度化圖片。
(3)歸一化圖片。
(4)得輸出。
import math
import cv2
import numpy as np
cvNet = cv2.dnn.readNetFromCaffe('detect.prototxt', 'detect.caffemodel')
image_path = r'C:\Users\dong.xie\Desktop\workcode\kevintest\google_crawler_for_linux\src\生活 二維碼_1\img000001.jpg'
img2 = cv2.imdecode(np.fromfile(image_path, dtype=np.uint8), 1) # img是矩陣
img = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
img_w = img.shape[1]
img_h = img.shape[0]
minInputSize = 400
resizeRatio = math.sqrt(img_w * img_h * 1.0 / (minInputSize * minInputSize))
target_width = int(img_w / resizeRatio)
target_height = int(img_h / resizeRatio)
input = cv2.resize(img, (target_width, target_height), interpolation=cv2.INTER_CUBIC)
blob = cv2.dnn.blobFromImage(input, scalefactor=1.0 / 255, size=(input.shape[1], input.shape[0]), mean=(0, 0, 0),
swapRB=False, crop=False)
cvNet.setInput(blob, name="data")
prob = cvNet.forward()
print(prob.shape)
# define CLIP(x, x1, x2) max(x1, min(x, x2))
def CLIP(x, x1, x2):
return int(max(x1, min(x, x2)))
# theshape is (1, 1, 100, 7) = > (batch, channel, count, dim)
for row in range(0, prob.shape[2]):
prob_score = prob[0][0][row]
# prob_score[0] is not used.
# prob_score[1]==1 stands for qrcode
# add a safe score threshold due to https://github.com/opencv/opencv_contrib/issues/2877
# prob_score[2] is the probability of the qrcode, which is not used.
if prob_score[1] == 1 and prob_score[2] > 1E-5:
x0 = CLIP(prob_score[3] * img_w, 0.0, img_w - 1.0)
y0 = CLIP(prob_score[4] * img_h, 0.0, img_h - 1.0)
x1 = CLIP(prob_score[5] * img_w, 0.0, img_w - 1.0)
y1 = CLIP(prob_score[6] * img_h, 0.0, img_h - 1.0)
cv2.rectangle(img2, (x0, y0), (x1, y1), (0, 0, 255), 2)
cv2.imshow("1", img2)
cv2.waitKey()
cv2.destroyAllWindows()
還是挺成功的:

# pip install opencv-contrib-python
import math
import os
import traceback
import cv2
import numpy as np
dataFile = r'''C:\Users\dong.xie\Desktop\12312'''
dst = r'E:\detection\02二維碼\images'
dst1 = r'E:\detection\02二維碼\labels'
cnt = 3000
def listPathAllfiles(dirname):
result = []
for maindir, subdir, file_name_list in os.walk(dirname):
for filename in file_name_list:
apath = os.path.join(maindir, filename)
result.append(apath)
return result
if __name__ == '__main__':
files = listPathAllfiles(dataFile)
cvNet = cv2.dnn.readNetFromCaffe('detect.prototxt', 'detect.caffemodel')
for file in files:
try:
if file.endswith(".jpg") or file.endswith(".png"):
img2 = cv2.imdecode(np.fromfile(file, dtype=np.uint8), 1) # img是矩陣
img = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
img_w = img.shape[1]
img_h = img.shape[0]
minInputSize = 400
resizeRatio = math.sqrt(img_w * img_h * 1.0 / (minInputSize * minInputSize))
target_width = int(img_w / resizeRatio)
target_height = int(img_h / resizeRatio)
input = cv2.resize(img, (target_width, target_height), interpolation=cv2.INTER_CUBIC)
blob = cv2.dnn.blobFromImage(input, scalefactor=1.0 / 255, size=(input.shape[1], input.shape[0]),
mean=(0, 0, 0),
swapRB=False, crop=False)
cvNet.setInput(blob, name="data")
prob = cvNet.forward()
# print(prob.shape)
# define CLIP(x, x1, x2) max(x1, min(x, x2))
def CLIP(x, x1, x2):
return int(max(x1, min(x, x2)))
resDet = []
# theshape is (1, 1, 100, 7) = > (batch, channel, count, dim)
for row in range(0, prob.shape[2]):
prob_score = prob[0][0][row]
# prob_score[0] is not used.
# prob_score[1]==1 stands for qrcode
# add a safe score threshold due to https://github.com/opencv/opencv_contrib/issues/2877
# prob_score[2] is the probability of the qrcode, which is not used.
if prob_score[1] == 1 and prob_score[2] > 1E-5:
x0 = CLIP(prob_score[3] * img_w, 0.0, img_w - 1.0)
y0 = CLIP(prob_score[4] * img_h, 0.0, img_h - 1.0)
x1 = CLIP(prob_score[5] * img_w, 0.0, img_w - 1.0)
y1 = CLIP(prob_score[6] * img_h, 0.0, img_h - 1.0)
resDet.append([x0, y0, x1, y1])
if len(resDet) >= 1:
cv2.imencode('.jpg', img2)[1].tofile(os.path.join(dst, "qrcode_" + str(cnt).zfill(6) + ".jpg"))
txtfile = os.path.join(dst1, "qrcode_" + str(cnt).zfill(6) + ".txt")
res = []
for x0, y0, x1, y1 in resDet:
x = round((x0 + x1) / 2 / img.shape[1], 6)
y = round((y0 + y1) / 2 / img.shape[0], 6)
w = round((x1 - x0) / img.shape[1], 6)
h = round((y1 - y0) / img.shape[0], 6)
res.append(" ".join(["1", str(x), str(y), str(w), str(h)]))
open(txtfile, "w").write("\n".join(res))
cnt += 1
except:
traceback.print_exc()