標注是:
下面程序folderFile 字典定義了數據集存儲的位置信息,VOCrootpath 給出了VOC存儲地址。
# coding:utf-8
import os.path
from xml.dom.minidom import Document
import cv2
import numpy as np
def writexml(filename, saveimg, bboxes, xmlpath):
doc = Document()
annotation = doc.createElement('annotation')
doc.appendChild(annotation)
folder = doc.createElement('folder')
folder_name = doc.createTextNode('widerface')
folder.appendChild(folder_name)
annotation.appendChild(folder)
filenamenode = doc.createElement('filename')
filename_name = doc.createTextNode(filename)
filenamenode.appendChild(filename_name)
annotation.appendChild(filenamenode)
source = doc.createElement('source')
annotation.appendChild(source)
database = doc.createElement('database')
database.appendChild(doc.createTextNode('wider face Database'))
source.appendChild(database)
annotation_s = doc.createElement('annotation')
annotation_s.appendChild(doc.createTextNode('PASCAL VOC2007'))
source.appendChild(annotation_s)
image = doc.createElement('image')
image.appendChild(doc.createTextNode('flickr'))
source.appendChild(image)
flickrid = doc.createElement('flickrid')
flickrid.appendChild(doc.createTextNode('-1'))
source.appendChild(flickrid)
owner = doc.createElement('owner')
annotation.appendChild(owner)
flickrid_o = doc.createElement('flickrid')
flickrid_o.appendChild(doc.createTextNode('muke'))
owner.appendChild(flickrid_o)
name_o = doc.createElement('name')
name_o.appendChild(doc.createTextNode('muke'))
owner.appendChild(name_o)
size = doc.createElement('size')
annotation.appendChild(size)
width = doc.createElement('width')
width.appendChild(doc.createTextNode(str(saveimg.shape[1])))
height = doc.createElement('height')
height.appendChild(doc.createTextNode(str(saveimg.shape[0])))
depth = doc.createElement('depth')
depth.appendChild(doc.createTextNode(str(saveimg.shape[2])))
size.appendChild(width)
size.appendChild(height)
size.appendChild(depth)
segmented = doc.createElement('segmented')
segmented.appendChild(doc.createTextNode('0'))
annotation.appendChild(segmented)
for i in range(len(bboxes)):
bbox = bboxes[i]
objects = doc.createElement('object')
annotation.appendChild(objects)
object_name = doc.createElement('name')
object_name.appendChild(doc.createTextNode('face'))
objects.appendChild(object_name)
pose = doc.createElement('pose')
pose.appendChild(doc.createTextNode('Unspecified'))
objects.appendChild(pose)
truncated = doc.createElement('truncated')
truncated.appendChild(doc.createTextNode('0'))
objects.appendChild(truncated)
difficult = doc.createElement('difficult')
difficult.appendChild(doc.createTextNode('0'))
objects.appendChild(difficult)
bndbox = doc.createElement('bndbox')
objects.appendChild(bndbox)
xmin = doc.createElement('xmin')
xmin.appendChild(doc.createTextNode(str(bbox[0])))
bndbox.appendChild(xmin)
ymin = doc.createElement('ymin')
ymin.appendChild(doc.createTextNode(str(bbox[1])))
bndbox.appendChild(ymin)
xmax = doc.createElement('xmax')
xmax.appendChild(doc.createTextNode(str(bbox[0] + bbox[2])))
bndbox.appendChild(xmax)
ymax = doc.createElement('ymax')
ymax.appendChild(doc.createTextNode(str(bbox[1] + bbox[3])))
bndbox.appendChild(ymax)
f = open(xmlpath, "w")
f.write(doc.toprettyxml(indent=''))
f.close()
if __name__ == '__main__':
# 給出下面五個路徑
folderFile = {
"traintxt": r"E:\WIIDERFACE\wider_face_split\wider_face_split\wider_face_train_bbx_gt.txt",
"trainimagepath": r"E:\WIIDERFACE\WIDER_train\WIDER_train\images",
"valtxt": r"E:\WIIDERFACE\wider_face_split\wider_face_split\wider_face_val_bbx_gt.txt",
"valimagepath": r"E:\WIIDERFACE\WIDER_val\WIDER_val\images",
"texttxt": r"E:\WIIDERFACE\wider_face_split\wider_face_split\wider_face_test_filelist.txt",
"textimagepath": r"E:\WIIDERFACE\WIDER_test\WIDER_test\images", }
# 給出VOC數據存儲地址
VOCrootpath = r"E:\WIIDERFACE\WIDER_VOC"
needPath = [os.path.join(VOCrootpath, "train", "Annotations"),
os.path.join(VOCrootpath, "train", "JPEGImages"),
os.path.join(VOCrootpath, "val", "Annotations"),
os.path.join(VOCrootpath, "val", "JPEGImages"),
os.path.join(VOCrootpath, "test", "JPEGImages"), ]
for ph in needPath:
if not os.path.exists(ph):
os.makedirs(ph)
for gtfile, gtimages, imgsavepath, vocxmlsavepath in [
(folderFile["traintxt"], folderFile["trainimagepath"], needPath[1], needPath[0]),
(folderFile["valtxt"], folderFile["valimagepath"], needPath[3], needPath[2])]:
with open(gtfile, "r", encoding="utf-8") as f:
while True:
gt_con = f.readline().strip()
if gt_con is None or gt_con == "":
break
im_path = os.path.join(gtimages, gt_con)
im_data = cv2.imdecode(np.fromfile(im_path, dtype=np.uint8), 1) # img是矩陣
if im_data is None:
continue
numbox = int(f.readline())
bboxes = []
if numbox == 0: # numbox 為0 的情況處理
f.readline()
else:
for i in range(numbox):
line = f.readline()
infos = line.split(" ") # 用空格分割
bbox = (int(infos[0]), int(infos[1]), int(infos[2]), int(infos[3]))
bboxes.append(bbox) # 將一張圖片的所有人臉數據加入bboxes
filename = gt_con.replace("/", "_").replace("-", "_")[:-4] # 將存儲位置作為圖片名稱,斜槓轉為下劃線
cv2.imencode('.jpg', im_data)[1].tofile(os.path.join(imgsavepath, filename + ".jpg"))
xmlpath = os.path.join(vocxmlsavepath, filename + ".xml")
writexml(filename, im_data, bboxes, xmlpath)
gtfile = folderFile["texttxt"]
gtimages = folderFile["textimagepath"]
imgsavepath = needPath[4]
with open(gtfile, "r", encoding="utf-8") as f:
while True:
gt_con = f.readline().strip()
if gt_con is None or gt_con == "":
break
im_path = os.path.join(gtimages, gt_con)
im_data = cv2.imdecode(np.fromfile(im_path, dtype=np.uint8), 1) # img是矩陣
if im_data is None:
continue
filename = gt_con.replace("/", "_").replace("-", "_")[:-4] # 將存儲位置作為圖片名稱,斜槓轉為下劃線
cv2.imencode('.jpg', im_data)[1].tofile(os.path.join(imgsavepath, filename + ".jpg"))
YOLO格式: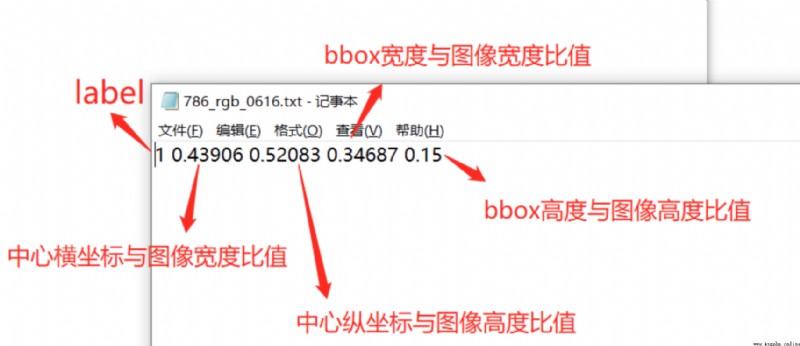
下面的代碼會在各自的Annotations同級目錄創建出labels文件夾,然後將Annotations內的xml標注轉換成yolov5的標注文件:
# coding:utf-8
import os
import os.path
import xml.etree.ElementTree as ET
def convert_annotation(xmldir: str, txtdir: str, image_id: str, classes: dict):
in_file = open(os.path.join(xmldir, '%s.xml' % (image_id)), 'r', encoding='UTF-8')
out_file = open(os.path.join(txtdir, '%s.txt' % (image_id)), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
size_width = int(size.find('width').text)
size_height = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes[cls]
xmlbox = obj.find('bndbox')
b = [float(xmlbox.find('xmin').text),
float(xmlbox.find('xmax').text),
float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text)]
if size_width == 0 or size_height == 0 or b[0] == b[1] or b[2] == b[3]:
print("不合理的圖不再給labels ", image_id)
# if os.path.exists(xmldir + '%s.xml' % (image_id)):
# os.remove(xmldir + '%s.xml' % (image_id))
out_file.close()
os.remove(os.path.join(txtdir, '%s.txt' % (image_id)))
return 1
# 標注越界修正
if b[0] < 0:
b[0] = 0
if b[1] > size_width:
b[1] = size_width
if b[2] < 0:
b[2] = 0
if b[3] > size_height:
b[3] = size_height
txt_data = [round(((b[0] + b[1]) / 2.0 - 1) / size_width, 6),
round(((b[2] + b[3]) / 2.0 - 1) / size_height, 6),
round((b[1] - b[0]) / size_width, 6),
round((b[3] - b[2]) / size_height, 6)]
if txt_data[0] < 0 or txt_data[1] < 0 or txt_data[2] < 0 or txt_data[3] < 0:
print("不合理的圖不再給labels ", image_id)
out_file.close()
os.remove(os.path.join(txtdir, '%s.txt' % (image_id)))
return 1
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in txt_data]) + '\n')
in_file.close()
out_file.close()
return 0
def listPathAllfiles(dirname):
result = []
for maindir, subdir, file_name_list in os.walk(dirname):
for filename in file_name_list:
apath = os.path.join(maindir, filename)
result.append(apath)
return result
if __name__ == '__main__':
classes = {
'face': 0} # 標簽名:標簽id
# 給出VOC數據存儲地址
VOCrootpath = r"E:\WIIDERFACE\WIDER_VOC"
needPath = [os.path.join(VOCrootpath, "train", "Annotations"),
os.path.join(VOCrootpath, "train", "JPEGImages"),
os.path.join(VOCrootpath, "val", "Annotations"),
os.path.join(VOCrootpath, "val", "JPEGImages"),
os.path.join(VOCrootpath, "test", "JPEGImages"),
os.path.join(VOCrootpath, "train", "labels"),
os.path.join(VOCrootpath, "val", "labels"), ]
for ph in needPath:
if not os.path.exists(ph):
os.makedirs(ph)
for xmlpath, txtpath in [[needPath[0], needPath[5]],
[needPath[2], needPath[6]]]:
allfiles = listPathAllfiles(xmlpath)
print("一共有文件個數:", len(allfiles))
failNum = 0
for xmlName in allfiles:
# xml存儲路徑,yololabels存儲路徑,xml文件名稱不帶.xml後綴,需要的類及其類id的字典
if convert_annotation(xmlpath, txtpath, os.path.basename(xmlName)[:-4], classes) == 1:
failNum += 1
print("失敗了多少個文件的labels:", failNum)
會遇到一些xml裡面標注不合規,但是沒多少,無關緊要了。但得注意,標簽不行就不要給txt文件,裡面沒內容的txt文件yolo會認為是對應圖裡沒目標。
C:\Users\dong.xie\.conda\envs\py38\python.exe C:/Users/dong.xie/Desktop/workcode/kevintest/dataset_cleaner/005VOC轉yolo.py
一共有文件個數: 12880
不合理的圖不再給labels 0__Parade_0_Parade_Parade_0_452
不合理的圖不再給labels 12__Group_12_Group_Large_Group_12_Group_Large_Group_12_31
不合理的圖不再給labels 29__Students_Schoolkids_29_Students_Schoolkids_Students_Schoolkids_29_230
不合理的圖不再給labels 2__Demonstration_2_Demonstration_Demonstration_Or_Protest_2_202
不合理的圖不再給labels 2__Demonstration_2_Demonstration_Demonstration_Or_Protest_2_520
不合理的圖不再給labels 2__Demonstration_2_Demonstration_Demonstration_Or_Protest_2_543
不合理的圖不再給labels 2__Demonstration_2_Demonstration_Demonstration_Or_Protest_2_546
不合理的圖不再給labels 2__Demonstration_2_Demonstration_Demonstration_Or_Protest_2_666
不合理的圖不再給labels 2__Demonstration_2_Demonstration_Demonstrators_2_206
不合理的圖不再給labels 2__Demonstration_2_Demonstration_Demonstrators_2_373
不合理的圖不再給labels 2__Demonstration_2_Demonstration_Demonstrators_2_559
不合理的圖不再給labels 2__Demonstration_2_Demonstration_Political_Rally_2_444
不合理的圖不再給labels 2__Demonstration_2_Demonstration_Political_Rally_2_71
不合理的圖不再給labels 2__Demonstration_2_Demonstration_Protesters_2_346
不合理的圖不再給labels 33__Running_33_Running_Running_33_660
不合理的圖不再給labels 35__Basketball_35_Basketball_basketballgame_ball_35_805
不合理的圖不再給labels 35__Basketball_35_Basketball_Basketball_35_102
不合理的圖不再給labels 35__Basketball_35_Basketball_Basketball_35_220
不合理的圖不再給labels 36__Football_36_Football_americanfootball_ball_36_184
不合理的圖不再給labels 36__Football_36_Football_Football_36_63
不合理的圖不再給labels 39__Ice_Skating_39_Ice_Skating_iceskiing_39_380
不合理的圖不再給labels 46__Jockey_46_Jockey_Jockey_46_576
不合理的圖不再給labels 46__Jockey_46_Jockey_Jockey_46_717
不合理的圖不再給labels 48__Parachutist_Paratrooper_48_Parachutist_Paratrooper_Parachutist_Paratrooper_48_258
不合理的圖不再給labels 48__Parachutist_Paratrooper_48_Parachutist_Paratrooper_Parachutist_Paratrooper_48_283
不合理的圖不再給labels 54__Rescue_54_Rescue_rescuepeople_54_29
不合理的圖不再給labels 58__Hockey_58_Hockey_icehockey_puck_58_947
不合理的圖不再給labels 7__Cheering_7_Cheering_Cheering_7_17
失敗了多少個文件的labels: 28
一共有文件個數: 3226
不合理的圖不再給labels 0__Parade_0_Parade_Parade_0_275
不合理的圖不再給labels 0__Parade_0_Parade_Parade_0_317
不合理的圖不再給labels 2__Demonstration_2_Demonstration_Demonstration_Or_Protest_2_476
不合理的圖不再給labels 2__Demonstration_2_Demonstration_Political_Rally_2_335
不合理的圖不再給labels 37__Soccer_37_Soccer_soccer_ball_37_281
不合理的圖不再給labels 39__Ice_Skating_39_Ice_Skating_iceskiing_39_583
不合理的圖不再給labels 50__Celebration_Or_Party_50_Celebration_Or_Party_houseparty_50_715
不合理的圖不再給labels 7__Cheering_7_Cheering_Cheering_7_171
不合理的圖不再給labels 7__Cheering_7_Cheering_Cheering_7_426
失敗了多少個文件的labels: 9
Process finished with exit code 0
此時獲得了這樣的文件層級結構:
E:\WIIDERFACE\WIDER_VOC
├─test
│ └─JPEGImages
├─train
│ ├─Annotations
│ ├─JPEGImages
│ └─labels
└─val
├─Annotations
├─JPEGImages
└─labels
為了便於yolov5識別,將三個JPEGImages名稱改寫為images。
同時,生成三個images的txtlist便於yolov5識別,下面程序即會在E:\WIIDERFACE\WIDER_VOC目錄生成對應imageslisttxt:
import os
def listPathAllfiles(dirname):
result = []
for maindir, subdir, file_name_list in os.walk(dirname):
for filename in file_name_list:
apath = os.path.join(maindir, filename)
result.append(apath)
return result
if __name__ == '__main__':
classes = {
'face': 0} # 標簽名:標簽id
# 給出VOC數據存儲地址
VOCrootpath = r"E:\WIIDERFACE\WIDER_VOC"
needPath = [os.path.join(VOCrootpath, "train", "Annotations"),
os.path.join(VOCrootpath, "train", "images"),
os.path.join(VOCrootpath, "val", "Annotations"),
os.path.join(VOCrootpath, "val", "images"),
os.path.join(VOCrootpath, "test", "images"),
os.path.join(VOCrootpath, "train", "labels"),
os.path.join(VOCrootpath, "val", "labels"), ]
for imagespath in [needPath[1], needPath[3], needPath[4]]:
allfiles = listPathAllfiles(imagespath)
fatherpath = os.path.dirname(imagespath)
txtname = os.path.basename(fatherpath)
f = open(os.path.join(VOCrootpath, txtname + ".txt"), "w", encoding="utf-8")
allfiles = list(map(lambda x: x.replace("\\", "/"), allfiles))
f.write("\n".join(allfiles))
f.close()
print(imagespath, "圖片數量", len(allfiles))
E:\WIIDERFACE\WIDER_VOC\train\images 圖片數量 12880
E:\WIIDERFACE\WIDER_VOC\val\images 圖片數量 3226
E:\WIIDERFACE\WIDER_VOC\test\images 圖片數量 16097
寫數據yaml文件,下載權重文件: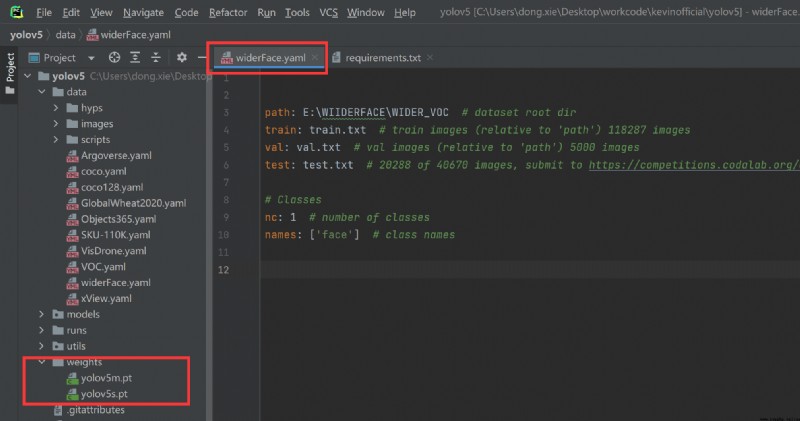
path: E:\WIIDERFACE\WIDER_VOC # dataset root dir
train: train.txt # train images (relative to 'path') 118287 images
val: val.txt # val images (relative to 'path') 5000 images
test: test.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# Classes
nc: 1 # number of classes
names: ['face'] # class names
訓練:
python train.py --batch-size 4 --data widerFace.yaml --img 640 --epochs 10 --weight weights/yolov5m.pt
看到這個樣子就行: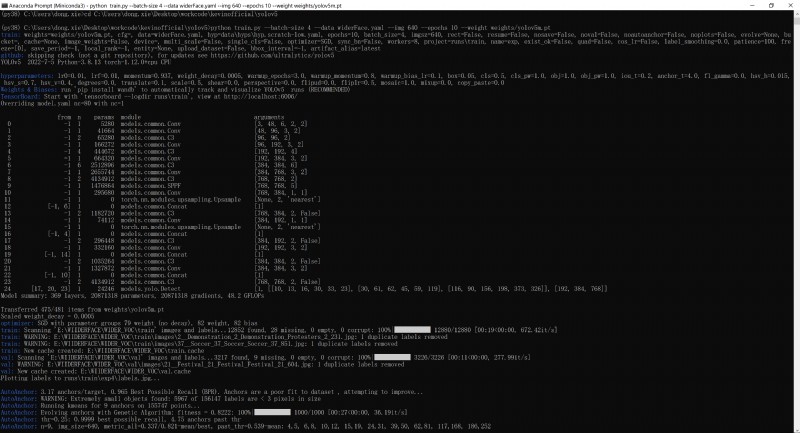
import os
import cv2
import matplotlib.pyplot as plt
import numpy as np
ASSETS_DIRECTORY = "assets"
plt.rcParams["savefig.bbox"] = "tight"
def listPathAllfiles(dirname):
result = []
for maindir, subdir, file_name_list in os.walk(dirname):
for filename in file_name_list:
apath = os.path.join(maindir, filename)
result.append(apath)
return result
if __name__ == '__main__':
labelspath = r'E:\WIIDERFACE\WIDER_VOC\train\labels'
imagespath = r'E:\WIIDERFACE\WIDER_VOC\train\images'
labelsFiles = listPathAllfiles(labelspath)
for lbf in labelsFiles:
labels = open(lbf, "r").readlines()
labels = list(map(lambda x: x.strip().split(" "), labels))
imgfileName = os.path.join(imagespath, os.path.basename(lbf)[:-4] + ".jpg")
img = cv2.imdecode(np.fromfile(imgfileName, dtype=np.uint8), 1) # img是矩陣
for lbs in labels:
lb = list(map(float, lbs))[1:]
x1 = int((lb[0] - lb[2] / 2) * img.shape[1])
y1 = int((lb[1] - lb[3] / 2) * img.shape[0])
x2 = int((lb[0] + lb[2] / 2) * img.shape[1])
y2 = int((lb[1] + lb[3] / 2) * img.shape[0])
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 0, 255), 5)
cv2.imshow("1", img)
cv2.waitKey()
cv2.destroyAllWindows()
python -m torch.distributed.launch --nproc_per_node 4 train.py --batch-size 128 --data widerFace.yaml --img 640 --epochs 400 --weight weights/yolov5m.pt --device 0,1,2,3