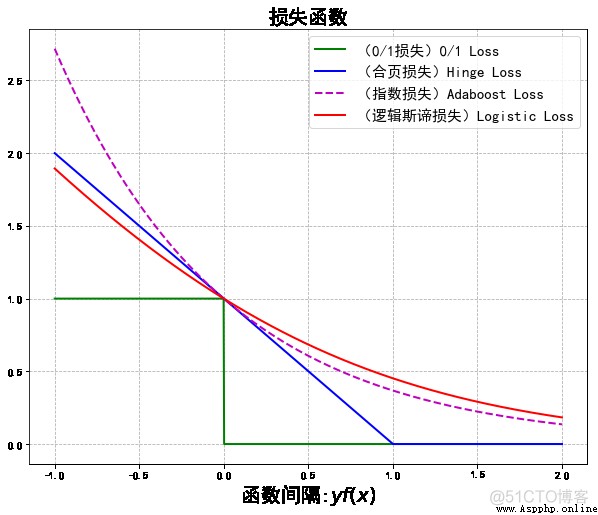
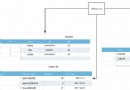
在二分類的監督學習中,支持向量機、邏輯斯谛回歸與最大熵模型、提升方法各自使用合頁損失函數、邏輯斯谛損失函數、指數損失函數,分別寫為:
這 3 種損失函數都是 0-1 損失函數的上界,具有相似的形狀。(見下圖,由代碼生成)
import numpy as np
import math
import matplotlib. pyplot as plt
plt. rcParams[ 'font.sans-serif'] = [ 'SimHei']
plt. rcParams[ 'axes.unicode_minus'] = False
plt. figure( figsize =( 10, 8))
x = np. linspace( start = - 1, stop = 2, num = 1001, dtype = np. float)
logi = np. log( 1 + np. exp( - x)) / math. log( 2)
boost = np. exp( - x)
y_01 = x < 0
y_hinge = 1.0 - x
y_hinge[ y_hinge < 0] = 0
plt. plot( x, y_01, 'g-', mec = 'k', label = '(0/1損失)0/1 Loss', lw = 2)
plt. plot( x, y_hinge, 'b-', mec = 'k', label = '(合頁損失)Hinge Loss', lw = 2)
plt. plot( x, boost, 'm--', mec = 'k', label = '(指數損失)Adaboost Loss', lw = 2)
plt. plot( x, logi, 'r-', mec = 'k', label = '(邏輯斯谛損失)Logistic Loss', lw = 2)
plt. grid( True, ls = '--')
plt. legend( loc = 'upper right', fontsize = 15)
plt. xlabel( '函數間隔:$yf(x)$', fontsize = 20)
plt. title( '損失函數', fontsize = 20)
plt. show()