該篇文章是關鍵詞搜索法獲取高德poi,但鑒於無法突破900條記錄的上限,因此重寫了矩形搜索法的文章,具體可參考以下文章:
高德poi獲取之矩形搜索法(沖出900條限制)
(建議沒有python基礎的朋友先閱讀該篇再看矩形搜索法!)
首先我們需要明白一些常識
API的理解
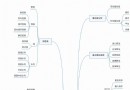
我們把整個poi的獲取理解成以下幾個步驟:
(1)找“高德地圖”這個人申請要數據
(2)高德地圖他說你申請數據需要先填一下這張數據需求表
(3)你拿到這張表(API),開始填寫表(API)裡的信息,包括POI的類別,POI的區域,需要數據的格式
(4)高德地圖看了你填寫的需求表,就從它的數據庫裡找到並且交回給你
(5)你拿到數據之後,篩選出關心的信息,之後就找各種方式把數據保存起來,例如存成一份excel表,或者一份txt文件,抑或是csv表格等等
所以通俗地講,API就是一份表,通過這個表可以讓對方返回你需要的東西,只不過實際上,這個表是用鏈接的形式發給你,在鏈接裡填入信息就相當於填表的行為了。
在高德開放平台上,我們獲取poi所需的接口位於[開發支持]-[Web服務]-[Web服務API]下,點擊即可進到主頁。我們需要用到的接口如下圖所示: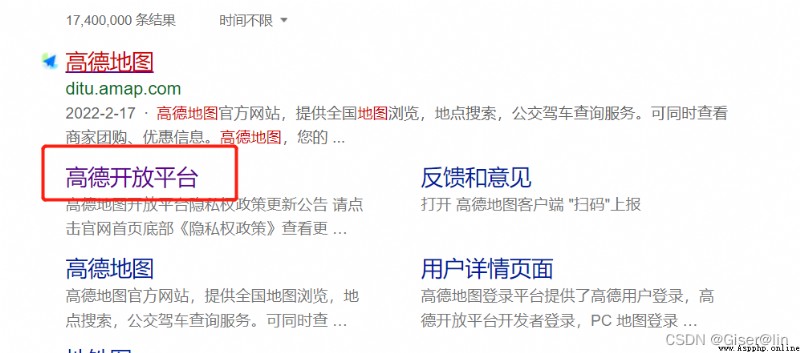
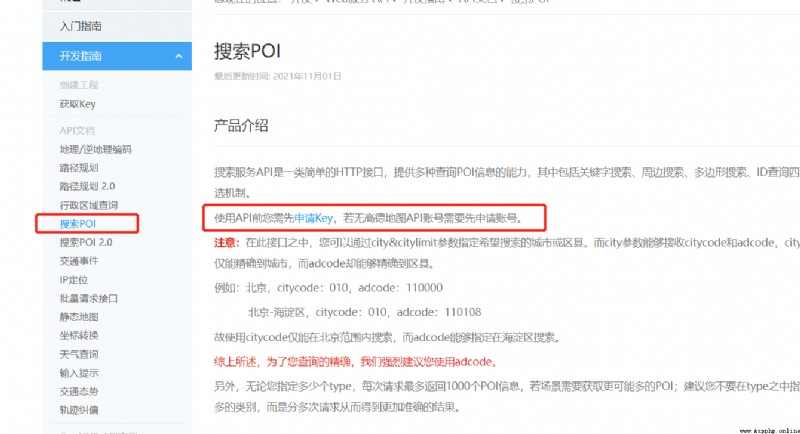
從圖上可以知道,高德地圖說想使用這個API,你必須有我家的密鑰(key),因此我們首先需要去申請一下這個key。具體怎麼申請可以參照以下這篇文章(https://zhuanlan.zhihu.com/p/96838566),接下來默認大家都有這個key了。
然後呢,我們從適用場景那裡得知,這個搜索poi有四種方法可以獲取poi,分別是關鍵字搜索、周邊搜索、多邊形搜索和ID查詢,我們這裡使用最簡單的關鍵字搜索。
在關鍵字搜索下面,我們可以看到有個請求參數的表格,這個請求參數其實就是API裡需要我們填寫的信息,我們看到那麼多參數,其實不用慌,分清哪些是必填的,哪些是可填的,接下來就好辦了。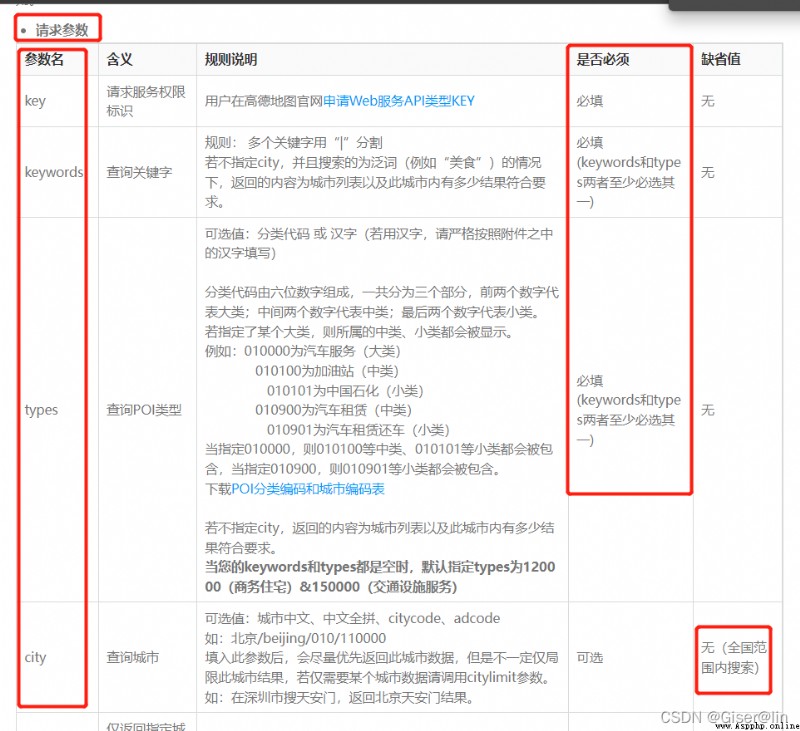

從我框選的地方可以知道,其實必填的只有兩三項。
1.key,就是我們上面申請的密鑰
2.keywords或者types,注意是兩者至少填一個,我示例裡選擇的是types
3.city,這個如果不填的話默認是幫你搜索全國的,但我們一般都會指定一個區域
4.page,你可以想象成一頁頁的紙,高德地圖默認每頁20條信息,默認返回一頁給你,也就是20條。那麼為了獲取全部的poi,我們需要高德地圖返回盡可能多頁給我們,直到搜不到poi為止,因此這個參數在控制循環的時候尤為重要
5.output,返回的數據格式類型,我們一般都返回JSON格式,方便我們處理
接下來,我們查看一下返回的參數,這部分內容比較多,因此我錄了個視頻來講解。
核心參數:
1. status
2. pois(核心參數:location、name等)
查看完返回結果參數之後,我們就已經明白了我們需要填寫的信息和最後得到的信息有哪些,那麼距離開始操作就只差最後一步了,就是拿表(API)填寫。
高德地圖裡給我們舉了個栗子: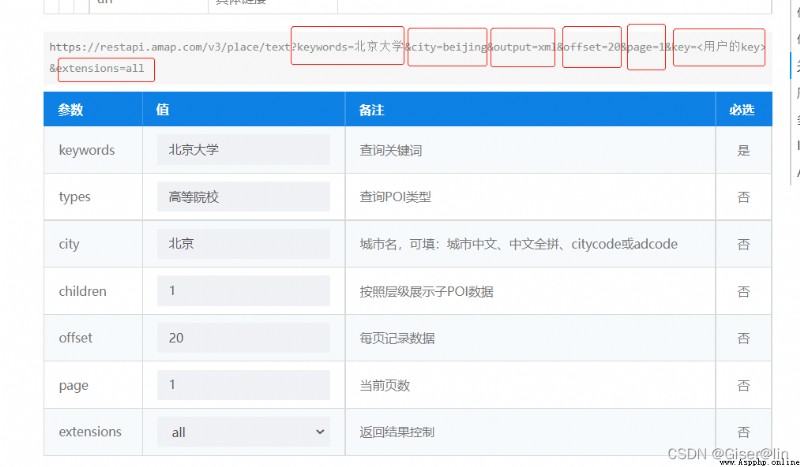
不難發現,這個API裡面有一些參數是我們熟悉的,例如keywords、city、key,並且這些關鍵詞都是通過“&”符號進行連接,因此我們只要能夠替換掉它的這些信息,就可以完成API的構建啦。
例如我需要獲取東莞市的,就把 city=beijing改成city = 東莞市需要獲取公園類型的poi,就把keywords換成types,然後types = 公園即可。
這是我的一些想法:
我們現在已經學會怎麼通過修改鏈接裡的關鍵詞來構建我們所需的API,那麼下一步其實只需要向高德地圖發出申請即可
但仔細思考,我們可以把整個過程劃分成以下三個部分:
通過上面過程的劃分,我們可以抽象成三個函數,一個舉手函數,一個反復舉手函數,一個保存結果函數。
雖然我在這次實驗中需要獲取高德地圖poi,但如果下次我需要獲取另外一個地方的其他類型poi,我能否用這次的方法來直接獲取而不是重新寫一次代碼?
因此我想將上述的過程都封裝成函數,下次再使用的時候只需要改改地區、poi類別即可完成所有工作。
這裡我們引入所需要的庫
#庫的說明
1.requests --爬蟲常用庫
2.json --該庫能夠幫我們處理高德返回的JSON格式的數據
3.xlwt --名字很奇怪,但它是xlsx、xls writer的意思,就是存儲為excel表格庫
4.Coordin_transformlat -- 這個是自己寫的一個坐標轉換的庫,其目的是為了解決開頭說的坐標偏移的問題
5.urlib -- 主要使用該庫裡的quote函數,因為當我們向電腦輸入漢字時,計算機其實並不認識漢字,因為它只認識0101這些二進制代碼,那麼quote函數就可以將漢字翻譯成計算機能夠懂的語言。
#引入所需的庫
import requests
import json
from urllib.parse import quote
import xlwt
from Coordin_transformlat import gcj02towgs84
回想一下剛剛的api,申請必須填寫的幾個參數:key,city,types或keywords,同時,容易忽略的一個參數是page,在請求函數裡page是個可選參數,表示當前頁數,我們可以通過遞增page的值來反復地提交申請,例如第一次先申請第一頁,第二次申請第二頁這樣實現,所以這裡至少需要四個參數
代碼理解
url: 是一個鏈接,通過訪問這個鏈接,我們可以獲取得到所需的數據
User-Agent:用戶代理頭,因為我們編寫的是爬蟲程序,通過爬蟲去獲取數據,而網站其實是不太支持爬蟲爬取數據,因為爬蟲的訪問次數太快太多了,後台容易崩潰。那怎麼讓對方認不出來這是個爬蟲呢?
通過添加User-Agent來給爬蟲戴上用戶(指正常浏覽網站的人)的面具,這樣瞞過對方視線,一般設置在headers裡。
request.get():我們通過get(url,header)來爬取數據
get()方法,只要你輸入一個網址就可以模擬人浏覽網站的行為,相當於訪問url這個鏈接
def Get_poi(key,city,types,page):
'''
這是一個能夠從高德地圖獲取poi數據的函數
key:為用戶申請的高德密鑰
city:目標城市
types:POI數據的類型
page:當前頁數
'''
#設置header
header = {'User-Agent': "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50"}
#構建url
#{}在鏈接裡表示占位符,也就是占住位置先不填寫,.format()裡就是往剛剛占位符的地方填寫變量,按照順序一一對應,第一個{}裡是key,第二個{}裡是types
url = 'https://restapi.amap.com/v3/place/text?key={}&types={}&city={}&page={}&output=josn'.format(key,types,quote(city),page)
#用get函數請求數據
r = requests.get(url,headers=header)
#設置數據的編碼為'utf-8'
r.encoding = 'utf-8'
#將請求得到的數據按照'utf-8'編碼成字符串
data = r.text
return data
這裡只需要重復調用上面構造好的申請函數,直到最後一頁的數據條數(Count)為0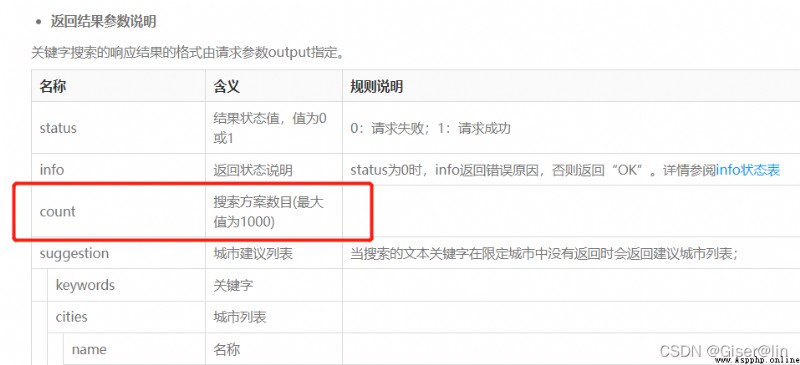
因此這裡只要當前頁數(page)的記錄條數(count)不為0,就一直執行循環
def Get_times(key,city,types):
'''
這是一個控制申請次數的函數
'''
page = 1
#創建一個poilist的空列表
poilist = []
#執行以下代碼,直到count為0的時候跳出循環
while True:
#調用第一個函數來獲取數據
result = Get_poi(key,city,types,page)
#json.loads可以對獲取回來JSON格式的數據進行解碼
content = json.loads(result)
#content的樣子其實跟返回結果參數是一樣的,可以想象成有很多個字段的excel表格,下面這個語句就是提取出pois那個字段
pois = content['pois']
#pois的信息寫入空列表裡,這裡由於不知道返回的數據長什麼樣子,所以會難以理解些
for i in range(len(pois)):
poilist.append(pois[i])
#遞增page
page = page + 1
#判斷當前頁下的count是否等於0
if content['count'] == '0':
break
#將寫好poi信息的列表返回
return poilist
content的樣子: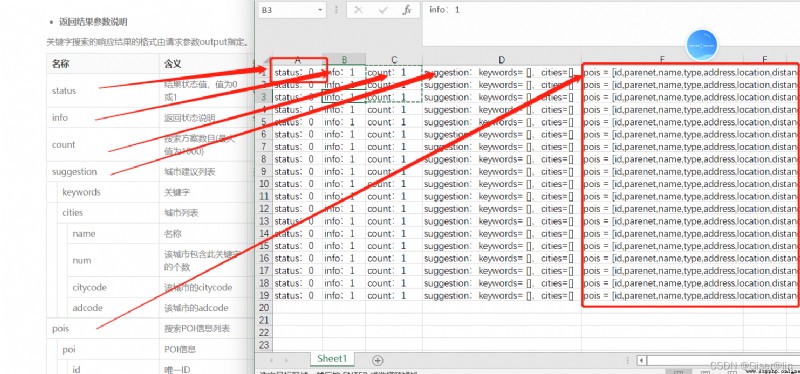
這圖裡,我們可以看到有很多條數據,這些數據就是高德地圖返回給我們的,但類似於info、suggestion這些字段我們是不關心的,我們只關心pois這個字段,所以我們用pois = content['pois']這行代碼來提取出pois這個字段。
但如果觀察得仔細,你會發現pois字段裡面還有很多的信息,除了我們關心的location、name以外,還有id、parent、email等,所以第三步需要我們再一次篩選信息
通過上述的函數,我們得到了只包含pois字段的列表,但這個pois字段裡還有很多無關的信息,因此我們這裡單獨提取出經緯度(location)、名稱(name)、地址(address)
(下面這段代碼是直接搬了別人的過來,現成的就不用自己再寫一遍了,意義不大)
借鑒博客:(https://blog.csdn.net/john_ashley/article/details/114196683)
def write_to_excel(poilist, city,types):
'''
這是一個可以將列表寫入excel的函數
poilist -- 上面得到的poilist
city -- 城市名,這個參數是保存excel文件的名字用的
types -- poi類別,這個也是為了保存excel文件,可直接看代碼最後一行
'''
#我們可以把這兩行代碼理解成新建一個excel表,第一句是新建excel文件
book = xlwt.Workbook(encoding='utf-8', style_compression=0)
#往這個excel文件新建一個sheet表格
sheet = book.add_sheet(types, cell_overwrite_ok=True)
# 第一行(列標題)
sheet.write(0, 0, 'x')
sheet.write(0, 1, 'y')
sheet.write(0, 2, 'count')
sheet.write(0, 3, 'name')
sheet.write(0, 4, 'address')
sheet.write(0, 5, 'adname')
#最難理解的地方應該是這裡了,放到代碼後面講解
for i in range(len(poilist)):
name = poilist[i]['name']
location = poilist[i]['location']
address = poilist[i]['address']
adname = poilist[i]['adname']
lng = str(location).split(",")[0]
lat = str(location).split(",")[1]
#這裡是坐標系轉換,也放到代碼後面詳解
result = gcj02towgs84(location)
lng = result[0]
lat = result[1]
# 每一行寫入
sheet.write(i + 1, 0, lng)
sheet.write(i + 1, 1, lat)
sheet.write(i + 1, 2, 1)
sheet.write(i + 1, 3, name)
sheet.write(i + 1, 4, address)
sheet.write(i + 1, 5, adname)
# 最後,將以上操作保存到指定的Excel文件中
book.save(city + "_" + types + '.xls')
第三個文件其實難以理解的地方只有for循環跟坐標系轉換,第一個是技術問題,第二個是背景問題,我們先來將坐標系。
1.為什麼高德地圖得到的坐標系不能直接使用?
其實是因為國家規定,中國大陸所有公開地理數據都需要至少用GCJ-02進行加密,也就是說我們從國內公司的產品中得到的數據,一定是經過了加密的。絕大部分國內互聯網地圖提供商都是使用GCJ-02坐標系,包括高德地圖,谷歌地圖中國區等。
2.關於這個GCJ-02坐標系
GCJ-02(G-Guojia國家,C-Cehui測繪,J-Ju局),又被稱為火星坐標系,是一種基於WGS-84制定的大地測量系統,由中國國測局制定。此坐標系所采用的混淆算法會在經緯度中加入隨機的偏移。所以這就是我們為什麼需要對獲取得到的經緯度進行坐標系轉換的原因了。
3.“Coordin_transformlat – 這個是自己寫的一個坐標轉換的庫” 這個怎麼理解呢?
其實呢,就是自己寫了一個python文件,只不過在這個文件裡有一些方法,我希望在另外的文件裡也能用上,所以通過import的方法引入,例如我在A文件裡寫了某個方法,然後我在B文件裡也想使用這個方法,那麼我在B文件裡import A即可。
當B文件運行的時候,系統讀到了這個方法,就會去A文件裡看看這個方法是怎樣的,大致如此。
4.Coordin_transformlat這個模塊有什麼用呢?
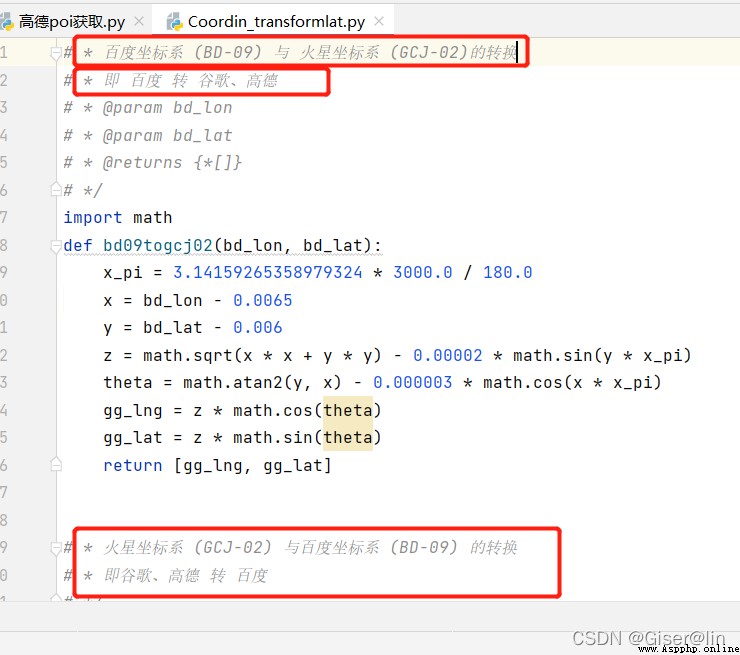
從上面標注其實可以發現,這個模塊裡頭有許多函數,如bd09todcj02,gcj02tobd09,wgs84togcj02等等,其實這些都是坐標轉換的函數,目的不就是實現坐標轉換嗎?所以在代碼中的那句result = gcj02towgs84(location)就不難理解了,是從火星坐標系(gcj02)轉向WGS84坐標系。
Coordin_transformlat源代碼
# * 百度坐標系 (BD-09) 與 火星坐標系 (GCJ-02)的轉換
# * 即 百度 轉 谷歌、高德
# * @param bd_lon
# * @param bd_lat
# * @returns {*[]}
# */
import math
def bd09togcj02(bd_lon, bd_lat):
x_pi = 3.14159265358979324 * 3000.0 / 180.0
x = bd_lon - 0.0065
y = bd_lat - 0.006
z = math.sqrt(x * x + y * y) - 0.00002 * math.sin(y * x_pi)
theta = math.atan2(y, x) - 0.000003 * math.cos(x * x_pi)
gg_lng = z * math.cos(theta)
gg_lat = z * math.sin(theta)
return [gg_lng, gg_lat]
# * 火星坐標系 (GCJ-02) 與百度坐標系 (BD-09) 的轉換
# * 即谷歌、高德 轉 百度
# */
def gcj02tobd09(lng, lat):
x_PI = 3.14159265358979324 * 3000.0 / 180.0
z = math.sqrt(lng * lng + lat * lat) + 0.00002 * math.sin(lat * x_PI)
theta = math.atan2(lat, lng) + 0.000003 * math.cos(lng * x_PI)
bd_lng = z * math.cos(theta) + 0.0065
bd_lat = z * math.sin(theta) + 0.006
return [bd_lng, bd_lat]
# wgs84轉高德
def wgs84togcj02(lng, lat):
PI = 3.1415926535897932384626
ee = 0.00669342162296594323
a = 6378245.0
dlat = transformlat(lng - 105.0, lat - 35.0)
dlng = transformlng(lng - 105.0, lat - 35.0)
radlat = lat / 180.0 * PI
magic = math.sin(radlat)
magic = 1 - ee * magic * magic
sqrtmagic = math.sqrt(magic)
dlat = (dlat * 180.0) / ((a * (1 - ee)) / (magic * sqrtmagic) * PI)
dlng = (dlng * 180.0) / (a / sqrtmagic * math.cos(radlat) * PI)
mglat = lat + dlat
mglng = lng + dlng
return [mglng, mglat]
# GCJ02/谷歌、高德 轉換為 WGS84 gcj02towgs84
def gcj02towgs84(localStr):
lng = float(localStr.split(',')[0])
lat = float(localStr.split(',')[1])
PI = 3.1415926535897932384626
ee = 0.00669342162296594323
a = 6378245.0
dlat = transformlat(lng - 105.0, lat - 35.0)
dlng = transformlng(lng - 105.0, lat - 35.0)
radlat = lat / 180.0 * PI
magic = math.sin(radlat)
magic = 1 - ee * magic * magic
sqrtmagic = math.sqrt(magic)
dlat = (dlat * 180.0) / ((a * (1 - ee)) / (magic * sqrtmagic) * PI)
dlng = (dlng * 180.0) / (a / sqrtmagic * math.cos(radlat) * PI)
mglat = lat + dlat
mglng = lng + dlng
return [lng * 2 - mglng,lat * 2 - mglat]
def transformlat(lng, lat):
PI = 3.1415926535897932384626
ret = -100.0 + 2.0 * lng + 3.0 * lat + 0.2 * lat *
lat + 0.1 * lng * lat + 0.2 * math.sqrt(abs(lng))
ret += (20.0 * math.sin(6.0 * lng * PI) + 20.0 *
math.sin(2.0 * lng * PI)) * 2.0 / 3.0
ret += (20.0 * math.sin(lat * PI) + 40.0 *
math.sin(lat / 3.0 * PI)) * 2.0 / 3.0
ret += (160.0 * math.sin(lat / 12.0 * PI) + 320 *
math.sin(lat * PI / 30.0)) * 2.0 / 3.0
return ret
def transformlng(lng, lat):
PI = 3.1415926535897932384626
ret = 300.0 + lng + 2.0 * lat + 0.1 * lng * lng +
0.1 * lng * lat + 0.1 * math.sqrt(abs(lng))
ret += (20.0 * math.sin(6.0 * lng * PI) + 20.0 *
math.sin(2.0 * lng * PI)) * 2.0 / 3.0
ret += (20.0 * math.sin(lng * PI) + 40.0 *
math.sin(lng / 3.0 * PI)) * 2.0 / 3.0
ret += (150.0 * math.sin(lng / 12.0 * PI) + 300.0 *
math.sin(lng / 30.0 * PI)) * 2.0 / 3.0
return ret
for i in range(len(poilist)):
name = poilist[i]['name']
location = poilist[i]['location']
address = poilist[i]['address']
adname = poilist[i]['adname']
lng = str(location).split(",")[0]
lat = str(location).split(",")[1]
如果你想理解上面的循環體,那麼必須要了解以下的知識:
- poilist是長什麼樣的
- for循環裡的i
- 多維列表的遍歷。
那麼下面我就一一講解一下。
poilist的樣子大概是這樣的:
這裡需要注意的是,poilist它本身是一個列表,這個大列表裡面包含著295個子項,每一個子項又是字典形式的。
畫出示意圖大概就是下面這樣: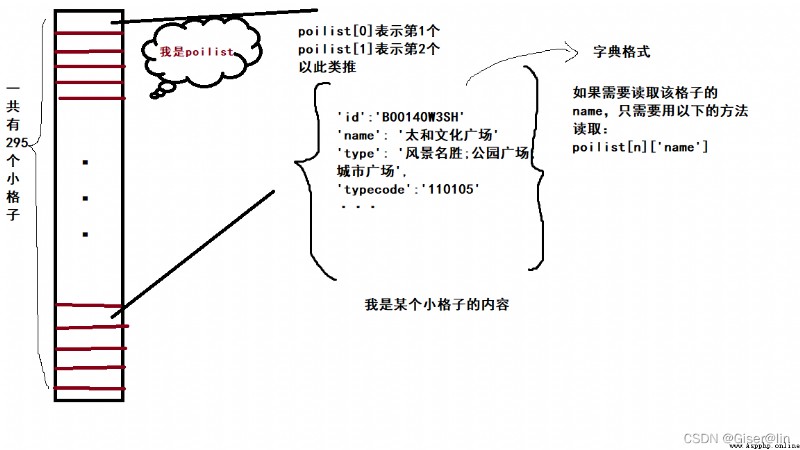
name = poilist[i]['name']
location = poilist[i]['location']
address = poilist[i]['address']
adname = poilist[i]['adname']
所以你再看這幾行代碼的時候,是不是就沒那麼陌生了
而在for循環裡的i,它其實是個變量。
你可以想象一下"有十只羊,按順序排好隊,一只只地送上屠宰場"這個情景,我們假設一個准備送上屠宰場的羊 的變量,那麼隨著羊一只只地走了,這個變量也在不斷地指向下一只羊,它所指代的內容是不斷變化的。
再比如,在for i in range(1,10)這個代碼裡,第一次循環i是1,然後下一次循環的時候i就變成了2,下一次變成了3,只到所有的都輪過一遍才結束。
因此,不難理解,在我們的代碼 for i in range(len(poilist)):裡,i是一個變化著的數值,從0開始,直到變成poilist的長度那麼大的數字結束。然後剛好這個數字放在了poilist[i]裡,可以不斷地指向poilist的每個子項。
import requests
import json
from urllib.parse import quote
import xlwt
from Coordin_transformlat import gcj02towgs84
def Get_poi(key, city, types, page):
'''
這是一個能夠從高德地圖獲取poi數據的函數
key:為用戶申請的高德密鑰
city:目標城市
types:POI數據的類型
page:當前頁數
'''
# 設置header
header = {
'User-Agent': "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50"}
# 構建url
# {}在鏈接裡表示占位符,也就是占住位置先不填寫,.format()裡就是往剛剛占位符的地方填寫變量,按照順序一一對應,第一個{}裡是key,第二個{}裡是types
url = 'https://restapi.amap.com/v3/place/text?key={}&types={}&city={}&page={}&output=josn'.format(key, types,
quote(city), page)
# 用get函數請求數據
r = requests.get(url, headers=header)
# 設置數據的編碼為'utf-8'
r.encoding = 'utf-8'
# 將請求得到的數據按照'utf-8'編碼成字符串
data = r.text
return data
def Get_times(key, city, types):
'''
這是一個控制申請次數的函數
'''
page = 1
# 創建一個poilist的空列表
poilist = []
# 執行以下代碼,直到count為0的時候跳出循環
while True:
# 調用第一個函數來獲取數據
result = Get_poi(key, city, types, page)
# json.loads可以對獲取回來JSON格式的數據進行解碼
content = json.loads(result)
# content的樣子其實跟返回結果參數是一樣的,可以想象成有很多個字段的excel表格,下面這個語句就是提取出pois那個字段
pois = content['pois']
# pois的信息寫入空列表裡,這裡由於不知道返回的數據長什麼樣子,所以會難以理解些
for i in range(len(pois)):
poilist.append(pois[i])
# 遞增page
page = page + 1
# 判斷當前頁下的count是否等於0
if content['count'] == '0':
break
# 將寫好poi信息的列表返回
return poilist
def write_to_excel(poilist, city,types):
'''
這是一個可以將列表寫入excel的函數
poilist -- 上面得到的poilist
city -- 城市名,這個參數是保存excel文件的名字用的
types -- poi類別,這個也是為了保存excel文件,可直接看代碼最後一行
'''
#我們可以把這兩行代碼理解成新建一個excel表,第一句是新建excel文件
book = xlwt.Workbook(encoding='utf-8', style_compression=0)
#往這個excel文件新建一個sheet表格
sheet = book.add_sheet(types, cell_overwrite_ok=True)
# 第一行(列標題)
sheet.write(0, 0, 'x')
sheet.write(0, 1, 'y')
sheet.write(0, 2, 'count')
sheet.write(0, 3, 'name')
sheet.write(0, 4, 'address')
sheet.write(0, 5, 'adname')
#最難理解的地方應該是這裡了,放到代碼後面講解
for i in range(len(poilist)):
name = poilist[i]['name']
location = poilist[i]['location']
address = poilist[i]['address']
adname = poilist[i]['adname']
lng = str(location).split(",")[0]
lat = str(location).split(",")[1]
#這裡是坐標系轉換,也放到代碼後面詳解
result = gcj02towgs84(location)
lng = result[0]
lat = result[1]
# 每一行寫入
sheet.write(i + 1, 0, lng)
sheet.write(i + 1, 1, lat)
sheet.write(i + 1, 2, 1)
sheet.write(i + 1, 3, name)
sheet.write(i + 1, 4, address)
sheet.write(i + 1, 5, adname)
# 最後,將以上操作保存到指定的Excel文件中
book.save(city + "_" + types + '.xls')
#這裡修改為自己的高德密鑰
key = '**********'
#這裡修改自己的poi類型
types = ['公園廣場','汽車服務']
#建議將大區域切分成幾個小區域來獲取,保證獲取的數據齊全
city_list = ['白雲區','天河區','越秀區','黃埔區']
#先遍歷city_list裡面的每個區域
for city in city_list:
#再遍歷types裡的每個類別
for type in types:
poi = Get_times(key,city,type)
print('當前城市:' + str(city) + ', 分類:' + str(type) + ", 總的有" + str(len(poi)) + "條數據")
write_to_excel(poi,city,type)
print('*'*50+'分類:' + str(type) + "寫入成功"+'*'*50)
print('====爬取完成====')
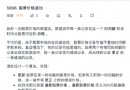
汽車服務的有幾條數據都是897,應該是區域內的poi數量超過1000了,因此這個通過關鍵字搜索poi的方法還有待改善~碼不動了,改日再戰!
總的來說,過程還是挺順利的!

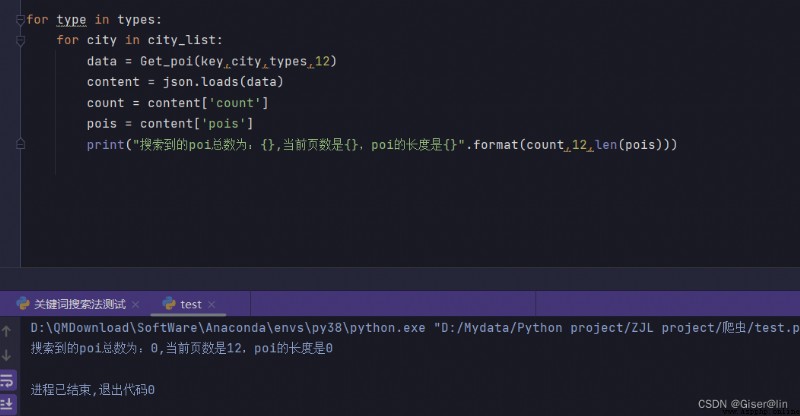
在2022年7月6日高德POI進行了一次更新之後,關鍵詞搜索法也出現了一些新的問題,例如獲取到的POI數量最多為200條,這裡我也嘗試獲取某個區的酒店poi,發現從11頁開始POI的數量就變為0了。
這個問題也困擾著我,暫時無法用該方法解決。所幸的是矩形搜索法目前能夠很好地解決這個問題,所以建議大家將該方法作為熟悉高德POI的一種方式,實戰中用矩形搜索法去獲取齊全的POI數據。
ng)