本文小編為大家詳細介紹“怎麼使用Python代碼實現模擬百度搜索”,內容詳細,步驟清晰,細節處理妥當,希望這篇“怎麼使用Python代碼實現模擬百度搜索”文章能幫助大家解決疑惑,下面跟著小編的思路慢慢深入,一起來學習新知識吧。
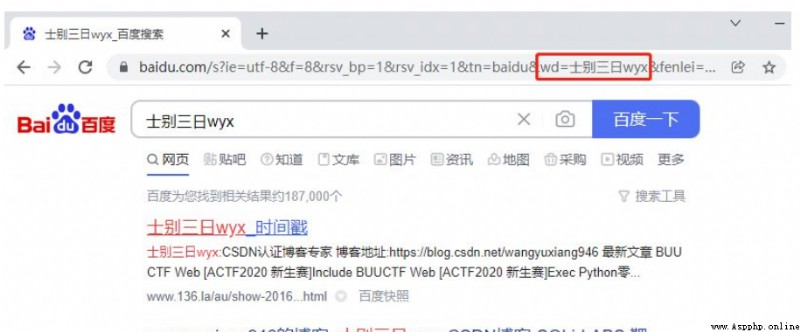
地址欄中有很多參數,但實際有用的參數只有 wd ,只需要保留這一個參數即可,其余刪掉。
url = 'https://www.baidu.com/s?wd=士別三日wyx'
搜索內容肯定不能寫死,需要由用戶「輸入」
kw = input('百度一下:')url = 'https://www.baidu.com/s?wd=' + kw利用百度的接口發送「請求」,獲取響應內容。
大部分網站都會對用戶的請求進行「過濾」,以防止惡意攻擊行為,比如查看是否是浏覽器發出的請求
「UA偽裝」是指在HTTP請求頭中添加 User-agent ,偽裝成浏覽器的請求,網站檢查請求頭時,發現有UA請求頭,就會認為是浏覽器的請求,從而放行。
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:92.0) Gecko/20100101 Firefox/92.0',}response = requests.get(url=url, headers=headers)響應的內容實際上就是構成頁面的 HTML 代碼,將響應內容寫入HTML文件,就獲得了百度搜索的響應頁面
fileName = 'a.html'with open(fileName, 'w', encoding='utf-8') as fp: fp.write(response.text)
頁面生成以後肯定不能再手動打開,那也太low了,使用默認「浏覽器」自動打開生成的頁面
webbrowser.open(fileName)
源碼如下
import webbrowserimport requestskw = input('百度一下:')url = 'https://www.baidu.com/s?wd=' + kwheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:92.0) Gecko/20100101 Firefox/92.0',}response = requests.get(url=url, headers=headers)fileName = 'a.html'with open(fileName, 'w', encoding='utf-8') as fp: fp.write(response.text)webbrowser.open(fileName)輸入想要百度的內容,按下回車

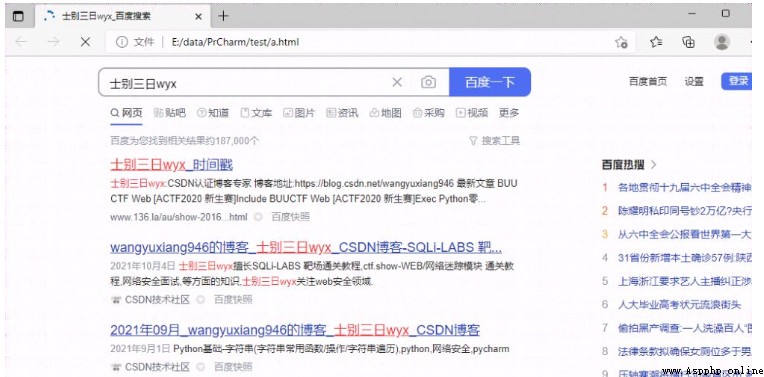
即可自動使用默認浏覽器打開搜索結果的頁面
讀到這裡,這篇“怎麼使用Python代碼實現模擬百度搜索”文章已經介紹完畢,想要掌握這篇文章的知識點還需要大家自己動手實踐使用過才能領會,如果想了解更多相關內容的文章,歡迎關注億速雲行業資訊頻道。