可以參考文章:https://blog.csdn.net/woailuohui/article/details/84604251:大佬寫的很詳細
is:比較兩個變量是否指向了同一個內存地址
而==比較的是對象所指代的value值是否相等
break語句用來終止循環語句,即循環條件沒有False條件或者序列還沒被完全遞歸完,也會停止執行循環語句。
break語句用在while和for循環中。
如果您使用嵌套循環,break語句將停止執行最深層的循環,並開始執行下一行代碼。
for letter in 'Python': # 第一個實例
if letter == 'h':
break
print '當前字母 :', letter
var = 10 # 第二個實例
while var > 0:
print '當前變量值 :', var
var = var -1
if var == 5: # 當變量 var 等於 5 時退出循環
break
print "Good bye!"
continue 語句跳出本次循環,而break跳出整個循環。
continue 語句用來告訴Python跳過當前循環的剩余語句,然後繼續進行下一輪循環。
continue語句用在while和for循環中。
for letter in 'Python': # 第一個實例
if letter == 'h':
continue
print '當前字母 :', letter
var = 10 # 第二個實例
while var > 0:
var = var -1
if var == 5:
continue
print '當前變量值 :', var
print "Good bye!"
{}、[]、set()、False、()、0、‘’、None
方式一:
a,b,c= 1,2,3
a=b=c=3
方式二:
a=b=c=2
c=1.1
d=2.2
print(c+d) 3.3000000000000003
from decimal import Decimal
print(Decimal('1.1')+Decimal('2.2')) 3.3
def fun(number):
if number>=-9 and number<=9:
return number
num=str(number)
if num[0]=='-':
num1=num[1:][::-1]
num1=int(num1)
num1=-num1
return num1
else:
num1=num[::-1]
return num1
print(fun(-1234))
print(sum(range(1,101)))
def fun():
for i in range(1,10):
for j in range(1,i+1):
print('{}*{}={}'.format(i,j,i*j),end='\t')
print()
fun()
-1是最後一個索引,-2是倒數第二個索引
print(sum(range(1,10249)))
python中的運算符:
算術運算符:+、-、*、\、%、//、
比較運算符:>,<, =,<=,>= ,!=
賦值運算符:= += -= *= /= //= **=
邏輯運算符:and or not
成員運算符:in not in
身份運算符:is is not
位運算符:
li=[[x for x in range(1,100)][i:i+3] for i in range(0,100,3)]
print(li)
print(int('1.4')) 報錯
print(int(1.4)) 1
IOError:輸入輸出異常
AttributeError:試圖訪問一個對象沒有屬性
ImportError:無法引入模塊和包,,基本是路徑的問題
IndentationError::語法錯誤,代碼沒有正確的對齊
IndexError:下標索引超出序列邊界
KeyError:試圖訪問字典中不存在的鍵
SyntaxError:代碼邏輯語法錯誤,不能執行
NameError:使用一個還未賦予對象的變量
import json
d={
"laker":"詹姆斯"}
dd=json.dumps(d,ensure_ascii=False)
print(dd)
with open('1.txt','r',encoding='utf-8') as f:
content=f.readlines()
for line in content:
print(line)
但是,當完成這一操作時,readlines() 方法(read() 也一樣)會將整個文件加載到內存中。在文件較大時,往往會引發 MemoryError(內存溢出)。
with open('1.txt','r',encoding='utf-8') as f:
while True:
content=f.readline()
for line in content:
if not line:
break
print(line)
def read_in_chunks(file_obj,chunk_size=2048):
''' 逐件讀取文件 默認塊大小:2kb '''
while True:
data=file_obj.read(chunk_size) #每次讀取指定的長度
if not data:
break
yield data
with open('1.txt','r',encoding='utf-8') as f:
g=read_in_chunks(f)
print(g.__next__())
print(g.__next__())
print(g.__next__())
print(g.__next__())
with open('1.log','r') as f:
count=0
txt=f.read()
print(txt)
for item in txt:
if item.isupper():
count+=1
print(count)
with open('c:\ scores.txt','a') as f:
f.write('輸入內容')
try中的代碼沒有拋出錯誤
如果使用常規的f.open()寫法,我們需要try、except、finally,做異常判斷,並且文件最終不管遇到什麼情況,都要執行finally f.close()關閉文件。
執行with這個結構之後。f會自動關閉。相當於自帶了一個finally。
但是with本身並沒有異常捕獲的功能,但是如果發生了運行時異常,它照樣可以關閉文件釋放資源。
f=open('./1.txt','w')
try:
f.write("hello")
except:
pass
finally:
f.close()
使用with方法
with open('a.txt') as f:
print(f.read())
os.remove('3.log')
rm file
try:把可能出現的異常代碼放進try中,代表異常處理即將要處理的代碼段。
except xxx:捕獲異常,xxx表示異常類型,如果你大概知道代碼會報出什麼異常,那麼我們可以直接把具體異常類型類型填上。執行過程中,出現了xxx異常,那麼該段代碼就會執行。
else:當try段代碼能夠正常執行,沒有出現異常的情況下,會執行else段代碼。
finally:不管有沒有異常,最終都會執行。

print(os.path.abspath(__file__)) #當前文件的路徑
print(os.path.dirname(__file__)) #當前文件所在目錄
print(os.path.basename(__file__)) #當前文件的名稱
with open('1.log','r') as f:
lit=[]
txt=f.readlines()
print(txt)
num=len(txt)
for i in range(1,num+1):
lit.append(txt[num-i])
print(lit)
[‘erwer\n’, ‘wrtwer\n’, ‘fsd\n’, ‘fsdf\n’, ‘sdfG\n’, ‘sdfg\n’, ‘GHG\n’, ‘ER’]
[‘ER’, ‘GHG\n’, ‘sdfg\n’, ‘sdfG\n’, ‘fsdf\n’, ‘fsd\n’, ‘wrtwer\n’, ‘erwer\n’]
def get_line():
with open('1.log','r') as f:
while True:
data=f.readlines(6)
if data:
yield data
else:
break
f=get_line()
print(next(f))
print(next(f))
print(next(f))
print(next(f))
print(next(f))
print(next(f))
print(next(f))
1 os.path 主要是用於對系統路徑文件的操作。
2 sys.path 主要是對Python解釋器的系統環境參數的操作(動態的改變Python解釋器搜索路徑)。
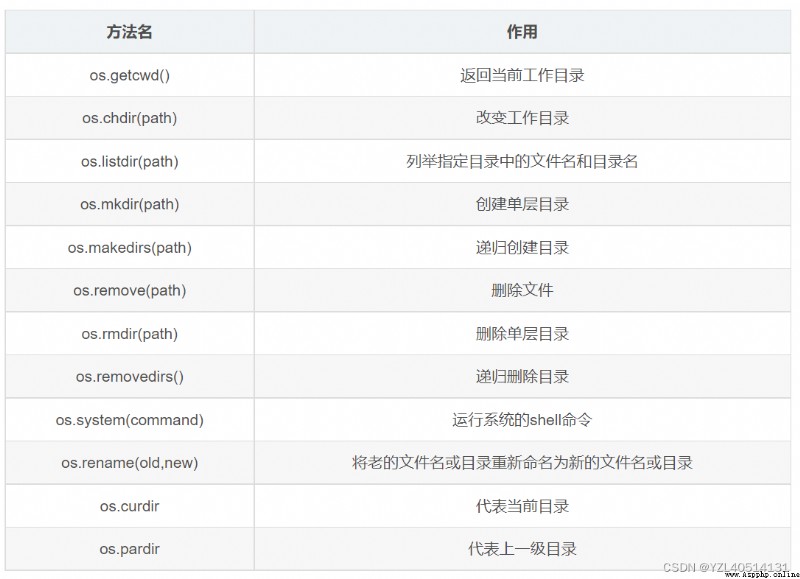
https://blog.csdn.net/YZL40514131/article/details/125609673?spm=1001.2014.3001.5501
def fun(p):
list=os.walk(p)
for path,dir_path,file_path in list:
for file in file_path:
txt=os.path.join(path,file)
print(txt)
for dir in dir_path:
d=os.path.join(path,dir)
print(d)
fun(r'D:\second_hand_car\SecondHand_list_query')
賦值(=),就是創建了對象的一個新的引用,修改其中任意一個變量都會影響到另一個。
list():表示創建了一個對象,但是並沒有創建引用
d=list():表示創建了一個對象,並且創建了一個對象的引用
a=b:表示創建了一個對象的引用,但是沒有創建對象
淺拷貝:創建一個新的對象,但它包含的是對原始對象中包含項的引用(如果用引用的方式修改其中一個對象,另外一個也會修改改變){1,完全切片方法;2,工廠函數,如list();3,copy模塊的copy()函數}
class Person:
def __init__(self,name):
self.name=name
if __name__ == '__main__':
p1=Person('kobe')
p2=Person('james')
l1=[p1,p2]
p1.name='jorden'
l2=list(l1) #淺拷貝
print(l2[0].name) #jorden
print(id(l1)) #2278620394368
print(id(l2)) #2278620429056
深拷貝:創建一個新的對象,並且遞歸的復制它所包含的對象(修改其中一個,另外一個不會改變),因此,新對象和原對象沒有任何關聯。{copy模塊的deepcopy()函數}
class Person:
def __init__(self,name):
self.name=name
if __name__ == '__main__':
p1=Person('kobe')
p2=Person('james')
l1=[p1,p2]
l3=copy.deepcopy(l1)
p1.name='curry'
print(l3[0].name) #kobe
print(id(l1)) #2351425281088
print(id(l3)) #2351425358080
random.sample(seq,k):實現從序列或集合中隨機選取k個獨立的元素
seq:元組、列表、字符串
k:選取元素個數
import random
lis=[1,2,11,8,23,24,35,7,30]
num=random.sample(lis,3)
print(num)
結果:[23, 2, 11]
random.chioce(seq):實現從序列或集合中隨機選取一個元素
seq:元組、列表、字符串
lis=[1,2,11,8,23,24,35,7,30]
num1=random.choice(lis)
print(num1)
結果:1
import smtplib
from email.mime.application import MIMEApplication
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
import os
from common.handle_path import REPORT_DIR
def send_report(report_name):
'''通過qq 郵箱發送測試報告給指定的用戶'''
# 第1步,連接qq smtp服務器,模擬登錄
# 1.1 todo 連接到qq smtp服務器---smtp.qq.com(官網找)
smtp = smtplib.SMTP_SSL(host='smtp.qq.com', port=465) # 創建一個連接服務器的對象,加斷點可以看smtp有很多方法
smtp.login(user='[email protected]', password='xxxxxxx') # gbffgrpvozcnjeag 是開啟smtp的時候,qq給的授權碼
# todo 第2步:構建一封對象
msg = MIMEMultipart()
msg['Subject'] = report_name[:-5] # 郵件標題
msg['To'] = '[email protected]'
msg['From'] = '[email protected]'
# todo 構建發送內容
text = MIMEText('你好附件是測試報告請查收', _charset='utf-8') # 構建文本對象
msg.attach(text) # 把內容添加到郵件中
# todo 上傳附件
# todo 讀取附件內容,byte格式
report_file = os.path.join(REPORT_DIR, report_name)
with open(report_file, mode='rb') as f:
content = f.read() # 讀取內容
report = MIMEApplication(content) # 構造附件對象
# todo 指定附件格式
report.add_header('content-disposition', 'attachment', filename=report_name)
msg.attach(report) # 把構造的附件添加到郵件中
# todo 第3步: 發送郵件 誰發的 #發給誰 列表裡可以添加多個qq郵箱
smtp.send_message(msg, from_addr='[email protected]', to_addrs=['[email protected]'])
if __name__ == '__main__':
send_report(report_name='接口自動化測試報告.html')
import random
num=random.randint(1,8)
print(num)
num1=random.random()
print(num1)
print('{:.2f}'.format(num1))
print(round(num1,4))
執行結果:
5
0.6067638026607728
0.61
0.6068
os
sys
re
time
json
datetime
logging
requests
unittest
random
import os
import time
import datetime
import re
import sys
import json
from collections import Counter
num=Counter("kjalfj;ldsjafl;hdsllfdhg;lahfbl;hl;ahlf;h")
print(num)
Counter({‘l’: 9, ‘;’: 6, ‘h’: 6, ‘f’: 5, ‘a’: 4, ‘j’: 3, ‘d’: 3, ‘s’: 2, ‘k’: 1, ‘g’: 1, ‘b’: 1})
import datetime
def fun():
year=input('請輸入年:')
month=input('請輸入月:')
day=input('請輸入日:')
a=datetime.date(year=int(year),month=int(month),day=int(day))
b=datetime.date(year=int(year),month=1,day=1)
c=(a-b).days
return c
print(fun())
sys.path 返回模塊的搜索路徑,初始化時使用 PYTHONPATH 環境變量的值
sys.stdout 標准輸出
sys.stdin 標准輸入
sys.stderr 錯誤輸出
pymysql
openpyxl
rest_framework
pytest
filter
Jinja2
SQLALchemy
requests
pywin32
redis
django
selenium
flask
tornade
l=[1,2,3,4]
l1=tuple(l)
print(l1)
l=(1,2,3,4)
l1=list(l)
print(l1)
1、列表可變和元組不可變
2、元組比列表的訪問和處理速度快,如果只需要對其中的元素進行訪問,而不進行任何修改,建議使用元組而不使用列表
3、因為列表可以修改,元組不可以修改,因此元組比列表具有更高的安全性。
4、列表不可以作為字典的鍵,元組可以作為字典的鍵
Python中的序列是索引的,它由正數和負數組成。正的數字使用’0’作為第一個索引,'1’作為第二個索引,以此類推。
負數的索引從’-1’開始,表示序列中的最後一個索引,’ - 2’作為倒數第二個索引,依次類推
d={
"a":"kobe","b":"james"}
d2={
"c":"curry"}
print(d.keys())
print(d.values())
print(d.items())
d={
"a":"kobe","b":"james"}
d1=d.pop("b")
print(d1) james
d={
"a":"kobe","b":"james"}
d2={
"c":"curry"}
d.update(d2)
print(d) {
'a': 'kobe', 'b': 'james', 'c': 'curry'}
li=[1,4,2,6,8,5]
list(set(li))
di={
"a":"kobe","c":"curry","b":"james"}
di1=sorted(di.keys(),key=lambda x:x,reverse=True)
d={
}
for i in di1:
d[i]=di[i]
print(d)
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
b=[i for i in a if i%2==1]
print(b)
a=(1,)
b=(1)
c=('1')
print(type(a))
print(type(b))
print(type(c))
執行結果:
<class ‘tuple’>
<class ‘int’>
<class ‘str’>
a=[1,3,4,5,6]
b=[1,3,56,7,7,5]
c=a+b
a.extend(b)
a.sort()
print(c)
print(a)
l=[[1,2],[3,4],[5,6]]
new_list=[]
for item in l:
for i in item:
new_list.append(i)
print(newlist)
join():括號裡面的是可迭代對象,x插入可迭代對象中間,形成字符串,結果一致
x = "abc"
y = "def"
z = ["d", "e", "f"]
x_1=x.join(y)
print(x_1)
x_2=x.join(z)
print(x_2)
[1,2,3,4,5,6]
foo =[-5,8,0,4,9,-4,-20,-2,8,2,-4]
foo1=sorted(foo,key=lambda x:x)
print(foo1)
foo =[-5,8,0,4,9,-4,-20,-2,8,2,-4]
foo1=sorted(foo,key=lambda x:x)
print(foo1)
foo=[{
'name':'zs','age':18},
{
'name':'li','age':24},
{
'name':'ww','age':25},]
按照姓名排序
foo1=sorted(foo,key=lambda x:x['name'])
print(foo1)
按照年領排序
foo2=sorted(foo,key=lambda x:x['age'],reverse=True)
print(foo2)
foo1=[('zs',19),('ls',18),('ww',20)]
foo2=sorted(foo1,key=lambda x:x[0])
print(foo2)
foo3=sorted(foo1,key=lambda x:x[1])
print(foo3)
foo1=[('zs',19),('ls',18),('ww',20)]
foo2=sorted(foo1,key=lambda x:x[0])
print(foo2)
foo3=sorted(foo1,key=lambda x:x[1])
print(foo3)
def dict_sortd(dic):
return sorted(zip(dic.keys(),dic.values()))
d={
"kobe":18,"james":20,"curry":19}
print(dict_sortd(d))
執行結果:[(‘curry’, 19), (‘james’, 20), (‘kobe’, 18)]
d={
"kobe":18,"james":20,"curry":19}
d1=sorted(d.keys(),key=lambda x:x)
print(d1)
歷史博文盡請關注
json.loads()
json.dumps()
l=[1,2,3,4]
l1=[2,4,5,6]
print(list(set(l) ^ set(l1))) #差集
print(list(set(l) & set(l1))) #交集
print(list(set(l) | set(l1))) #並集
[1, 3, 5, 6]
[2, 4]
[1, 2, 3, 4, 5, 6]
import openpyxl
class HandleExcel(object):
"""讓讀寫Excel格式的測試用例更方便 Attributes: filename: Excel文件的路徑。 sheet_name: 要讀取的用例在哪個Sheet中,默認是Sheet1 """
titles = ('id', 'title', 'data', 'expected') # 固定的標題
def __init__(self, filename, sheet_name):
"""創建一個HandExcel對象 args: filename: excel文件的路徑 sheet_name: 要讀取的工作表名,如果沒有指定默認使用Sheet1當做工作表名 """
self.filename = filename
self.sheet_name=sheet_name
# if sheet_name is None:
# self.sheet_name = 'Sheet1'
# else:
# self.sheet_name = sheet_name
def read_data(self) -> list: # 返回值是list
cases = [] # 用來存儲所有用例
titles = [] # 保存標題
wb = openpyxl.load_workbook(self.filename) # 獲取工作簿對象
ws = wb[self.sheet_name]
# 遍歷所有行
# 如果是表頭,把表頭保存到titles列表中,否則把數據添加到cases列表中
for i, row in enumerate(ws.rows):
if i == 0:
for cell in row:
titles.append(cell.value)
else:
cases.append(dict(zip(titles, [cell.value for cell in row])))
return cases
def write_data(self, row, column, value) -> None:
"""把數據寫到指定的單元格 args: row: 行號 column: 列號 value: 要寫入的值 returns: None """
wb = openpyxl.load_workbook(self.filename) # 獲取一個WorkBook對象
ws = wb[self.sheet_name] # 獲取一個WorkSheet對象
ws.cell(row, column, value)
wb.save(self.filename)
return None
if __name__ == '__main__':
excel = HandleExcel(r'C:\Users\api_test\data\apicases.xlsx','register')
for case in excel.read_data():
print(case)
l2=[2,4,5,6]
from random import shuffle
mylist=[x for x in range(10)]
shuffle(mylist)
print(mylist)
join():字符串的拼接,傳參類型為可迭代對象,並且可迭代對象中的元素為字符串類型
li=[1,3,5,7]
l=''.join(li)
print(l)
抱錯:TypeError: sequence item 0: expected str instance, int found
li=['1','3','5','7']
l=''.join(li)
print(l) 1357
split():字符串的拆分,拆分後為列表,傳遞的參數為分隔符
a='1357'
print(a.split(' ')) ['1357']
mytuple=3,4,5
print(mytuple)
x,y,z=mytuple
print(x+y+z)
(3, 4, 5)
12
int
float
str
bool
list
tuple
dict
set
int(str)
通過不斷的調用__next()__方法能不斷的返回下一個值的機制
q=[i*11 for i in range(1,10)]
print(q)
a=[1,2,3,4]
b=[3,4,5,6]
print(list(set(a) & set(b))) [3, 4]
print(list(set(a) | set(b))) [1, 2, 3, 4, 5, 6]
print(list(set(a) ^ set(b))) [1, 2, 5, 6]
global
會
反轉字符串
format
1、數字在[ -5 , 256]之間的數字
2、字符串的長度為0或者為1
3、當字符串的長度大於1時,滿足只能包含數字、下劃線、字母類型的字符
4、編譯時進行駐留,而非運行時
split
format
index
find
replace
upper
lower
count
strip
isdigit
isspace
join
encode
endswith
startswith
isalpha
islower
isspace
isupper
append
extend
pop
remove
count
max
min
sort
reverse
insert
clear
copy
index
count
keys
items
values
pop
update
clear
copy
fromkeys
get
將可迭代對象轉化為帶有索引的數組
lis=[1,2,3,34,54]
for index,value in enumerate(lis):
print(index,value)
print('-----------------------------')
ll={
"kobe":"laker","jorden":"bulls"}
for index,value in enumerate(ll):
print(index,value)
0 1
1 2
2 3
3 34
4 54
0 kobe
1 jorden
1.隊列可以看成是有2個口的集合一個口叫隊頭一個叫隊尾,只能在對頭進行刪除操作,在隊尾做插入。根據這樣的操作。隊列特點是先進先出
2.堆棧可以看成是有1個口的集合,這個口叫棧頂。插入和刪除操作只能在棧頂操作。根據這樣的操作。堆棧的特點是是後進先出.
3.鏈表是一種存儲方式,它可以在 非連續的內存空間裡面存儲一個集合的元素。
4.和它對應的是數組,數組要在 連續的空間裡存儲集合的元素
隊列、棧是線性數據結構的典型代表,而數組、鏈表是常用的兩種數據存儲結構;隊列和棧均可以用數組或鏈表的存儲方式實現它的功能
數組與鏈表:
數組屬於順序存儲中,由於每個元素的存儲位置都可以通過簡單計算得到,所以訪問元素的時間都相同(直接訪問數組下標);
鏈表屬於數據的鏈接存儲,由於每個元素的存儲位置是保存在它的前驅或後繼結點中的,所以只有當訪問到其前驅結點或後繼結點後才能夠按指針訪問到自己,訪問任一元素的時間與該元素結點在鏈接存儲中的位置有關。 鏈表和數組是常用的兩種數據存儲結構,都能用來保存特定類型的數據。
鏈表存放的內存空間可以是連續的,也可以是不連續的,數組則是連續的一段內存空間。一般情況下存放相同多的數據數組占用較小的內存,而鏈表還需要存放其前驅和後繼的空間。
鏈表的長度是按實際需要可以伸縮的,而數組的長度是在定義時要給定的,如果存放的數據個數超過了數組的初始大小,則會出現溢出現象。
鏈表方便數據的移動而訪問數據比較麻煩;數組訪問數據很快捷而移動數據比較麻煩。鏈表和數組的差異決定了它們的不同使用場景,如果需要很多對數據的訪問,則適合使用數組;如果需要對數據進行很多移位操作,則設和使用鏈表。
1.棧具有數據結構中棧的特點,後進先出,所有存放在它裡面的數據都是生命周期很明確(當然要求它不能存放太久,占有的空間確定而且占用空間小),能夠快速反應的!所有在Java中它存放的是8個基本數據類型和引用變量的,用完就馬上銷毀
2.堆可以理解它就是個一個可大可小,任你分配的聽話的內存操作單元;因此它的特點就是動態的分配內存,適合存放大的數據量!比如一個對象的所有信息,雖然它的引用指向棧中的某個引用變量;所有Java中堆是存放new出來的對象的。
後端:
1、對於緩沖存儲讀寫次數高、變化少的數據,比如網站首頁的信息。應用程序讀取數據時,一般是先從緩沖中給讀取,如果讀取不到或者數據已經失效,再訪問磁盤數據庫,並將數據再次寫入緩沖。
2、異步方式,如果有耗時操作,采用異步,celery
3、代碼優化,避免循環和判斷次數太多,如果有多個if else判斷,優先判斷最有可能先發生的情況。
數據庫優化
1、如有條件,數據可以存放redis,讀取速度快
2、建立索引、外鍵
前端:
1、html和css放在頁面的上部,javascript放在頁面下方,因為javascript加載比html和css加載慢,所以要優先加載html和css,以防頁面顯示不全,性能差,影響用戶體驗
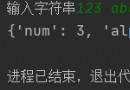
break
pyc是一種二進制文件,是由py文件經過編譯後,生成的文件,是一種byte code,py文件變成pyc文件後,加載的速度有所提高,而且pyc是一種跨平台的字節碼,是由Python的虛擬機來執行的
aStr[::-1]
a='k:1|k1:2|k2:3|k3:4'
def fun(str):
d={
}
for i in a.split("|"):
key,value= i.split(":")
d[key]=value
print(d)
fun(a)
ss=s.replace(' ','')
print(ss)
import datetime
class fun_time:
def __init__(self,file_name,level):
self.file_name=file_name
self.level=level
def __call__(self,func, *args, **kwargs):
def write(*args,**kwargs):
now_time = datetime.datetime.now()
result=func(*args,**kwargs)
time.sleep(3)
end_time = datetime.datetime.now()
print(end_time-now_time)
with open(self.file_name,'a',encoding='utf-8') as f:
f.write('函數運行時間為:{}'.format(end_time-now_time))
return result
return write
@fun_time(file_name='1.txt',level='info')
def fun_work():
sum=0
for i in range(1,1001):
sum+=i
return sum
if __name__ == '__main__':
print(fun_work())
在 result = a and b 運算中:
當a為假時,無論b為真或假,結果都為假,此時b的運算就不會進行,結果直接為a即可;
當a為真時,結果還得看b,b為真則真,b為假則假,此時結果即為b;
在result = a or b 運算中:
如果a 為真則無論b為什麼結果都會是真,結果即為b
如果a 為假則看b的情況了,b為真則結果為真,b為假則結果為假,即結果為b
可以大大加快數據的檢索速度,這也是創建索引的最主要的原因。
創建索引可以在查詢的過程中,提高系統的性能
通過創建唯一性索引,可以保持數據庫表中每一行數據的唯一性
時間方面:創建索引和維護索引要消耗時間,
空間方面:索引需要占用物理空間
主鍵索引:數據不允許重復,不允許為null,一個表只能有一個主鍵
唯一索引:數據列不允許重復,允許為null值,數據列不允許重復,允許為NULL值,一個表允許多個列創建唯一索引。
普通索引:基本的索引類型,沒有唯一性的限制,允許為NULL值。
a、不必一條記錄所有的字段都進行查詢(不要用*)
原子性:一個事務不可再分割,要麼都執行要麼都不執行。
一致性:一個事務執行會使數據從一個一致的狀態切換到另一個一致的狀態。
隔離性:一個事物的執行不會受其他事務的干擾。
持久性:一個事務一旦提交,則會永久性的改變。
@classmethod@staticmethod@property@ddt @data@pytest.mark.parametrize('test_info', plan_data)pytest數據驅動@action(method='GET',detail=False)路由器機制@cache_page(10, cache='default', key_prefix='mysite')視圖上加緩沖@pytest.fixture(scope='class'):表示每條用例執行的前置條件和後置條件
判斷某個對象是不是具體的某個數據類型
序列化和反序列操作:
序列化:將模型對象或者查詢集對象轉化為json格式的數據
反序列化:將json格式的數據轉化為其他類型的數據包括模型對象和查詢集對象
減少for循環執行次數
多個if elif 語句執行盡量將執行頻率高的語句寫到最上邊
使用生成器對象迭代數據,不用列表或者列表生成器
異步執行任務
class中是方法
class外是函數
python中一切皆對象
@pytest.fixture(scope='class')
def browser():
# todo 1、打開浏覽器
browser = webdriver.Chrome("C:\Program Files\Google\Chrome\Application\chromedriver.exe")
browser.implicitly_wait(10)
yield browser
# todo 11、關閉浏覽器
browser.quit()
class Person:
def __init__(self,age):
self.__age=age #__age是一個私有屬性
#使用屬性裝飾器,具有只讀屬性,無法賦值
@property
def age(self):
if self.__age<0:
return 18
return self.__age
#如果希望對一個“屬性”進行賦值,那就還需要使用裝飾器了
@age.setter
def age(self,value):
self.__age=value
if __name__ == '__main__':
p=Person(20)
print(p.age)
p.age=24
print(p.age)
對象屬性的查找順序:對象自己>>類中>>報錯
class Student:
school=''
def choose_course(self):
print(self.school)
print('選課技能')
#定義兩個不同的對象
s1=Student()
s2=Student()
#下面打印出來的都是哈佛,因為對象s1和對象s2的名稱空間中,都沒有school屬性,共用類的名稱空間中的school屬性
print(s1.school)
print(s2.school)
#假設s1同學轉學去了牛津了
s1.school='牛津' #對象增加了屬性
print(s1.school)
print(s2.school)
print(Student.school)
#對象自己有的屬性,優先使用自己的,沒有才去類中找,如果類中也沒有則報錯
對象自己
屬性在運行時的動態替換,叫做猴子補丁
作用是在運行的時候,動態替換模塊方法。
舉例:
class SomeClass(object):
def __init__(self):
self.name = "yoyo"
def speak(self):
return "hello world"
在不改變原來代碼的基礎上,可以重新定義一個speck方法,替換原來的
def new_speak(self):
return "new hello"
SomeClass.speak=new_speak
替換之後,調用的時候,就會變成新的方法裡面內容
some1=SomeClass()
print(some1.speak())
new hello
a={
i:i for i in range(1,10)}
print(a)
class A:
def __init__(self):
print("A")
class B(A):
def __init__(self):
print("B")
super().__init__()
class C(A):
def __init__(self):
print("C")
super().__init__()
class D(B, C):
def __init__(self):
print("D")
super().__init__()
D()
print(D.__mro__)
執行結果:
D
B
C
A
class A:
def test(self):
print('A')
class B:
def test(self):
print('B')
class C(A, B):
def __init__(self):
super().test() # 調用A類中的test方法
super(C, self).test() # 調用A類中的test方法
super(A, self).test() # 調用B類中的test方法
C()
print(C.__mro__)
執行結果:
A
A
B
類方法:對象和整個類都可以調用,需要裝飾器修飾,第一個參數時cls
實例方法:對象的方法,整個類不可以調用,第一個參數為self
靜態方法:整個類和對象都可以調用,不用傳遞參數,方便管理,需要裝飾器進行修飾
class P:
def __init__(self,name,age):
self.name=name
self.age=age
if __name__ == '__main__':
p=P('kobe',19)
print(p.__dict__)
for index,value in enumerate(p.__dict__):
print('序號{},屬性{}'.format(index,value))
dir§:查看所有的屬性和方法
https://blog.csdn.net/YZL40514131/article/details/120053124
單例模式
PO模式
數據驅動模式
工廠模式
裝飾器模式

init
new
str
repr
getattr
add
del
iter
next
call
python采用的是引用計數機制為主,標記-清除和分代收集(隔代回收)兩種機制為輔的策略
一個變量指向了內存地址,引用計數為1
兩個變量同時指向了一個內存地址,引用計數為2
a=4553223
a=4553223
b=a
c=[a]
c.append(a)
print(sys.getrefcount(a))
del a
def test():
b=667787
test()
函數執行完函數中的引用計數為0,可以進行回收
a,當一個對象的引用計數歸零時,它將被垃圾回收機制處理掉。
b,當兩個對象a和b相互引用時,del語句可以減少a和b的引用計數,並銷毀用於引用底層對象的名稱。然而由於每個對象都包含一個對其他對象的應用,因此引用計數不會歸零,對象也不會銷毀。(從而導致內存洩露)。為解決這一問題,解釋器會定期執行一個循環檢測器,搜索不可訪問對象的循環並刪除它們。
舉例:v1和v2互相引用,把v1和v2進行del
v1 = [1, 5, 6]
v2 = [6, 9, 2]
v1.append(v2)
v2.append(v1)
del v1
del v2
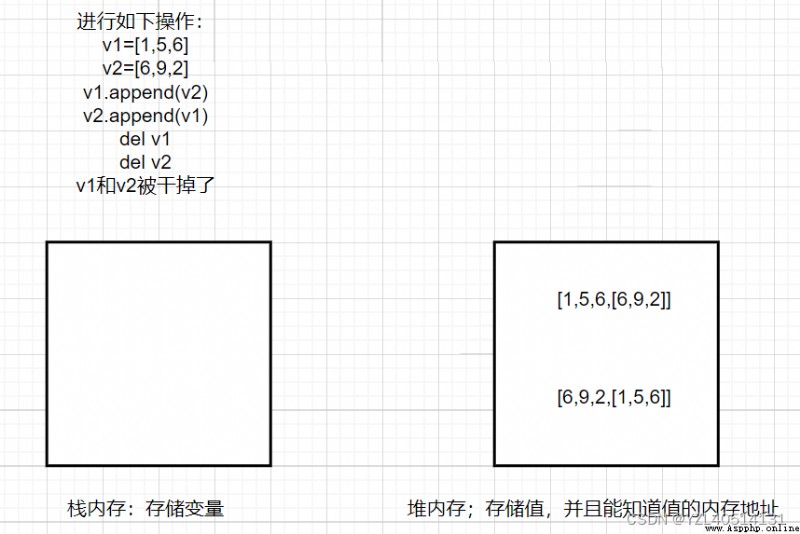
v1和v2對象被干掉了,但是堆內存中有相互引用,引用計數位為1;可是沒有變量去接收,這些內存地址程序員想用都不能用到,並且還占用內存。解決辦法就是用標記清除。
c、標記清除
在python的底層中,再去維護一個鏈表,這個鏈表中專門放那些可能存在循環引用的對象。
標記清除算法是一種基於追蹤回收 技術實現的垃圾回收算法。它分為兩個階段:第一階段是標記階段,GC會把所有的『活動對象』打上標記,第二階段是把那些沒有標記的對象『非活動對象』進行回收。
d、分代回收(幫我們回收循環嵌套的引用)
因為, 標記和清除的過程效率不高。清除非活動的對象前它必須順序掃描整個堆內存,哪怕只剩下小部分活動對象也要掃描所有對象。還有一個問題就是:什麼時候掃描去檢測循環引用?
為了解決上述的問題,python又引入了分代回收。分代回收解決了標記清楚時什麼時候掃描的問題,並且將掃描的對象分成了3級,以及降低掃描的工作量,提高效率。
0代: 0代中對象個數達到700個(阈值),掃描一次。
1代: 0代掃描10次,則1代掃描1次。
2代: 1代掃描10次,則2代掃描1次。
對於Python對象,以下幾種情況,都有其獨立的私有內存池。(字符串的駐留機制)
1、字符串長度為0或者1
2、符合標識符的字符串(只包含字母數字下劃線)
3、字符串只在編譯時進行駐留,而非運行時
4、[-5,256]之間的整數數字
答案是 No。每當python退出時,尤其是那些對其他對象具有循環引用的Python模塊或者從全局名稱空間引用的對象並不總是被解除分配或釋放。由於python擁有自己的高效清理機制,無法解除分配保留的那些內存部分會在退出時嘗試取消分配/銷毀其他所有對象。在 Python 退出時並非完全釋放。
1、生成器、迭代器
2、減少循環次數
3、if elif else
4、多線程起步
15. 簡述python引用計數機制 (重要)
找對應的作用域關系。查找順序為: 局部—> 全局 — > NameError
1、內存中加載的數據量過於龐大,如一次從數據庫取出過多數據;
2、代碼中存在死循環或循環產生過多重復的對象實體。
3、使用的第三方軟件中的BUG; 一般引用第三方jar包過多會出現此類問題。
4、啟動參數內存值設定的過小
5、集合類中有對對象的引用,使用完後未清空,產生了堆積,使得JVM不能回收;
處理:
第一步,修改JVM啟動參數,直接增加內存(-Xms,-Xmx參數一定不要忘記加)
第二步,檢查錯誤日志,查看“OutOfMemory”錯誤前是否有其 它異常或錯誤
第三步,對代碼進行走查和分析,找出可能發生內存溢出的位置