編輯
編輯
前言
博客:【紅目香薰的博客_CSDN博客-計算機理論,2022年藍橋杯,MySQL領域博主】
本文由在下【紅目香薰】原創,首發於CSDN
2022年最大願望:【服務百萬技術人次】
Python初始環境地址:【Python可視化數據分析01、python環境搭建】
環境需求
環境:win10
開發工具:PyCharm Community Edition 2021.2
數據庫:MySQL5.6
目錄
Python可視化數據分析09、Pandas_MySQL讀寫
前言
環境需求
前言
前置環境
基礎操作
MySQL增刪改
MySQL讀取操作
在Python中,最有名的ORM框架是SQLAlchemy。使用SQLAlchemy寫入數據到數據庫中的步驟如下:
導入SQLAlchemy模塊的create_engine()函數和pandas()函數
創建引擎,其中傳入的字符串格式為:數據庫類型+Python連接mysql的庫名://用戶名:密碼@IP地址:端口號/數據庫名
使用Pandas下的io.sql模塊下的to_sql()函數將DataFrame對象中的數據保存到數據庫中
使用Pandas模塊中的read_sql()函數讀取數據庫中的記錄,並保存到DataFrame對象中
pip3 install sqlalchemy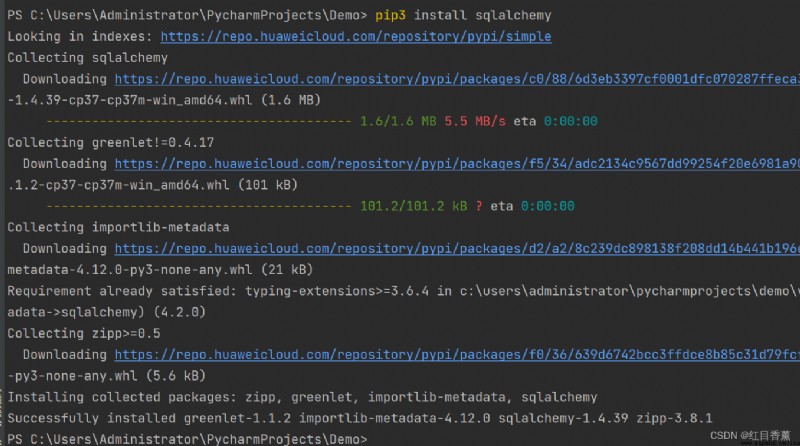 編輯
編輯
pip3 install pymysql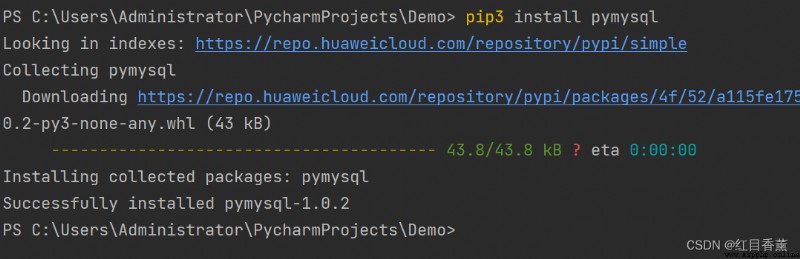 編輯
編輯
1、打開MySQL服務
 編輯
編輯
2、創建【mytest】數據庫
3、創建【user】表
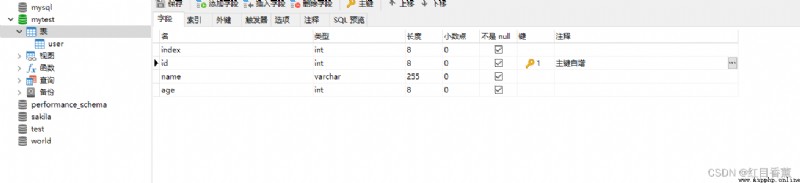 編輯
編輯
示例:
import pandas as pdfrom sqlalchemy import create_engine # 引入create_engine方法df = pd.DataFrame({"id": [1, 2, 3], "name": ["雷靜", "小鳳", "春夢"], "age": ["21", "22", "20"]})conn = create_engine('mysql+pymysql://root:[email protected]:3306/mytest?charset=utf8')# 將df對象保存到數據庫名為mytest的庫,名稱為user的數據庫表中pd.io.sql.to_sql(df, 'user', conn, schema='mytest', if_exists='append')# # 執行“select * from words;”SQL語句讀取數據庫中的數據df1 = pd.read_sql('select * from user;', con=conn)print(df1)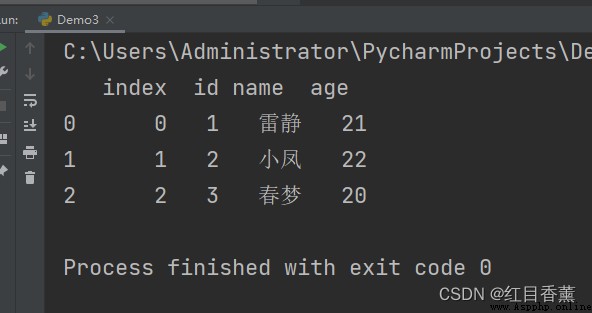
編輯import pandas as pdfrom sqlalchemy import create_engine # 引入create_engine方法from sqlalchemy.orm import sessionmakerconn = create_engine('mysql+pymysql://root:[email protected]:3306/mytest?charset=utf8')# 修改-刪除DB_Session = sessionmaker(bind=conn)session = DB_Session()# session.execute("insert into user values(3,0,'小龍女',22)")# session.execute("update user set name='曉鳳' where id=2")session.execute("delete from user where id=4")session.commit()# # 執行“select * from words;”SQL語句讀取數據庫中的數據df = pd.read_sql('select * from user;', con=conn)print(df)import pandas as pdfrom sqlalchemy import create_engine # 引入create_engine方法conn = create_engine('mysql+pymysql://root:[email protected]:3306/mytest?charset=utf8')# # 執行“select * from words;”SQL語句讀取數據庫中的數據df = pd.read_sql('select * from user;', con=conn)print(df)# 基礎信息print(df.info)# 查看列名print(df.columns)# 查看各列數據類型print(df.dtypes)# 查看下標print(df.index)# 數據浏覽前2條print(df.head(2))# 查看name到age列print(df.loc[:, "name":"age"])# 基本統計print("最大年齡:", df.age.max())print("平均年齡:", df.age.mean())# 查詢print(df[df.name == "春夢"])# 排序·True正序False倒序print(df.sort_values(by=["age"], ascending=False))# 在第二列【下標是1】添加列df.insert(1, "sex", "女")print(df)# 在最後添加列df["introduce"] = "巾帼"print(df)# 刪除某行df = df.drop(1)print(df)# 替換value = pd.Series([1, "女", "雷靜靜", 20, "大眼姑娘"], index=["id", "sex", "name", "age", "introduce"])df.loc[0] = valuevalue = pd.Series([4, "女", "小龍女", 18, "冰山美人"], index=["id", "sex", "name", "age", "introduce"])df.loc[3] = valueprint(df)# 條數print(len(df))
index id name age
0 0 1 雷靜 21
1 1 2 小鳳 22
2 2 3 春夢 20
<bound method DataFrame.info of index id name age
0 0 1 雷靜 21
1 1 2 小鳳 22
2 2 3 春夢 20>
Index(['index', 'id', 'name', 'age'], dtype='object')
index int64
id int64
name object
age int64
dtype: object
RangeIndex(start=0, stop=3, step=1)
index id name age
0 0 1 雷靜 21
1 1 2 小鳳 22
name age
0 雷靜 21
1 小鳳 22
2 春夢 20
最大年齡: 22
平均年齡: 21.0
index id name age
2 2 3 春夢 20
index id name age
1 1 2 小鳳 22
0 0 1 雷靜 21
2 2 3 春夢 20
index sex id name age
0 0 女 1 雷靜 21
1 1 女 2 小鳳 22
2 2 女 3 春夢 20
index sex id name age introduce
0 0 女 1 雷靜 21 巾帼
1 1 女 2 小鳳 22 巾帼
2 2 女 3 春夢 20 巾帼
index sex id name age introduce
0 0 女 1 雷靜 21 巾帼
2 2 女 3 春夢 20 巾帼
index sex id name age introduce
0 NaN 女 1 雷靜靜 20 大眼姑娘
2 2.0 女 3 春夢 20 巾帼
3 NaN 女 4 小龍女 18 冰山美人
3Process finished with exit code 0