️ 實習 實戰場景 僧
本篇博客繼續學習字體反爬,涉及的站點是實習 x,目標站點地址直接百度搜索即可。
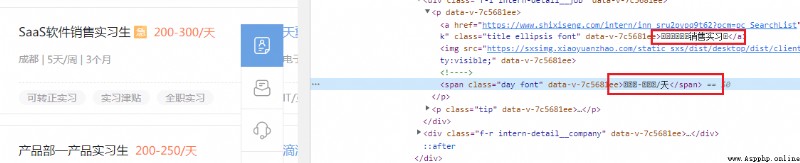
可以看到右側源碼中出現了很多“亂碼”,這其中就包含了關鍵信息。
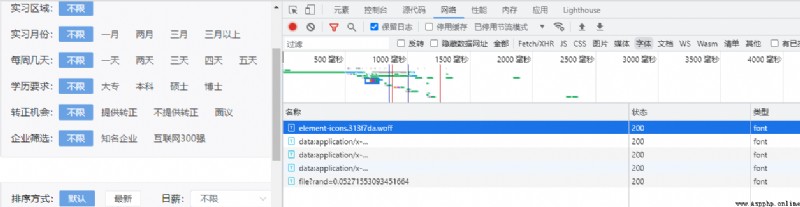
接下來按照常規的套路,在開發者工具中檢索字體相關信息,但是篩選之後,並沒有得到反爬的字體,只有一個
file? 有些許的可能性。
這裡就是一種新鮮的場景了,如果判斷不准,那只能用字體樣式和字體標簽名進行判斷了。在網頁源碼中檢索
@font-face 和
myFont,得到下圖內容,這裡發現
file 字體又出現了,看來解決問題的關鍵已經出現了。

下載文件名之後發現無後綴名,我們可以補上一個
.ttf 的後綴,接下來拖拽到 FontCreator 中,然後進行查閱。二次刷新頁面之後,再次獲取一個
file 文件,查看二者是否有編碼變化問題。
結論:每次請求字體文件,得到的響應無變化。既然沒有變化,後續的字體反爬實戰編碼就變的簡單了。
️ 實習 實戰編碼 僧
解析字體文件,獲取編碼與字符。
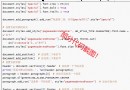
from fontTools.ttLib import TTFont
font1 = TTFont('./fonts/file.ttf')
keys,values = [],[]
for k, v in font1.getBestCmap().items():
print(k,v)
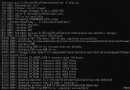
得到的結果如下所示。
2 extra bytes in post.stringData array
120 x
57345 uni4E00
57360 uni77
57403 uni56
……
然後我們查看一下實習僧站點返回的數據。
-
這其中又涉及到了編碼的轉換。
我們拿到一段帶編碼的文字,如下所示。
銷售實習
接下來查看一下頁面呈現的文字
SaaS軟件銷售實習生
其中
 對應的是
S 字符,再看一下該字符在字體文件中的編碼,如下所示。
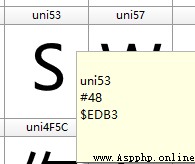
但是從剛才的結果中,並未得到
edb3 相關值,但是把十進制的編碼進行轉換之後,得到下述結果。
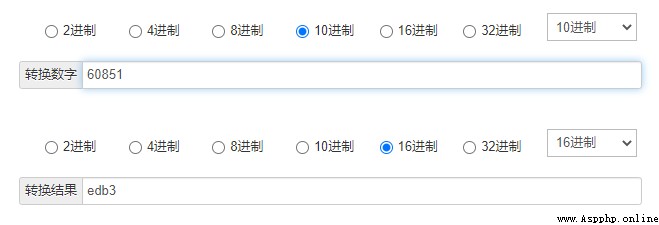
edb3 出現了,我們的本案例也完成了。
你正在閱讀 【夢想橡皮擦】 的博客 閱讀完畢,可以點點小手贊一下 發現錯誤,直接評論區中指正吧 橡皮擦的第 <font color=red>669</font> 篇原創博客