Gensim The theme model in includes three , Namely LDA (Latent Dirichlet Allocation) Theme model 、 With the author factor Author theme model (Author-Topic Model, ATM) And time factor Dynamic topic model (Dynamic Topic Models, DTM) .
Author theme model (ATM) In addition to the content of the article after word segmentation , It also includes the corresponding relationship between the author and the article ; The output of the model is for each author for each topic ( Number of topics n You can set it yourself ) Inclination of .
LDA Topic models have been widely used in many studies , There are also quite a lot of program materials on the Internet , but ATM The relevant code information of the model is not very complete , Some time ago, I also encountered some problems in the process of searching for information in the competition , After reading the official documents in English, it was solved . So this article introduces Gensim In bag ATM The process of complete implementation of the model , The complete code is attached at the end .
Catalog
1. ATM Model principle
2. Author-Topic Model English document of
3. Python call Gensim Implementation process
3.1 Import related packages
3.2 Prepare the data
3.3 Text vectorization
3.4 model training
3.5 Model results output
3.6 Model saving and loading
4. Complete implementation
Author Topic Model analysis _chinaliping The blog of -CSDN Blog  https://blog.csdn.net/chinaliping/article/details/9299953
https://blog.csdn.net/chinaliping/article/details/9299953
Author Topic Model[ATM Understanding and formula derivation ]_HFUT_qianyang The blog of -CSDN Blog Reference paper Modeling documents with topicsModeling authors with wordsThe author-topic modelGibbs sampling algorithms Detailed classic LDA Model target distribution and parameters Author Model Target distribution and parameters Author-topic model Target distribution and parameters the author : Hefei University of technology School of Management Qian Yang email: https://qianyang-hfut.blog.csdn.net/article/details/54407099
https://qianyang-hfut.blog.csdn.net/article/details/54407099
models.atmodel – Author-topic models — gensim (radimrehurek.com)https://radimrehurek.com/gensim/models/atmodel.html
from gensim.corpora import Dictionary
from gensim.models import AuthorTopicModelATM The data required by the model mainly includes :
# Here is the use of pandas Of DataFrame To read csv Data in the table , It contains participles 、 Author, etc .
import pandas as pd
df = pd.read_csv('data.csv')
# In the data “ participle ” Columns are words separated by spaces , If the data has no word segmentation , You also need to use jieba Equal word segmentation tool for word segmentation
df[' participle '] = df[' participle '].map(lambda x: x.split()) # use split Restore to list
data = df[' participle '].values.tolist() # Word segmentation list of each article , Each inner list contains the content of an article
# Example :[[' I ', ' like ', ' cat '], [' He ', ' like ', ' Dog '], [' We ', ' like ', ' animal ']]
author = df[' author '].values.tolist() # A list of authors for each article
# Example :[' author 1', ' author 2', ' author 1']
# Transform the correspondence between the author and the article into the format required by the model
author2doc = {}
for idx, au in enumerate(author):
if au in author2doc.keys():
author2doc[au].append(idx)
else:
author2doc[au] = [idx]
# Example after conversion :{' author 1': [0, 2], ' author 2': [1]}The word bag model is used here , Convert each article into BOW (Bag of words) vector , It can be used filter_n_most_frequent() Filter high-frequency words .
dictionary = Dictionary(data)
dictionary.filter_n_most_frequent(50) # Filter the highest frequency 50 Word
corpus = [dictionary.doc2bow(text) for text in data]Training ATM Model , If the amount of data is large, it may take a long time , among num_topics Parameter can set the number of topics of the target , Here for 10.
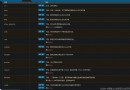
atm = AuthorTopicModel(corpus, num_topics=10, author2doc=author2doc, id2word=dictionary)Get the subject words of each topic and their weights , among num_words Parameter can control the number of subject words output for each topic .
atm.print_topics(num_words=20)Get the topic distribution of an author
atm.get_author_topics(' author 1')The theme distribution of each author
author_topics = {au: atm.get_author_topics(au) for au in set(author)}Save model training results , It should be noted that there is more than one model file , It also needs to be intact when loading , Not delete .
atm.save('atm.model')Load model
atm = AuthorTopicModel.load('atm.model')from gensim.corpora import Dictionary
from gensim.models import AuthorTopicModel
import pandas as pd
df = pd.read_csv('data.csv')
# In the data “ participle ” Columns are words separated by spaces , If the data has no word segmentation , You also need to use jieba Equal word segmentation tool for word segmentation
df[' participle '] = df[' participle '].map(lambda x: x.split()) # use split Restore to list
data = df[' participle '].values.tolist() # Word segmentation list of each article
author = df[' author '].values.tolist() # A list of authors for each article
# Transform the correspondence between the author and the article into the format required by the model
author2doc = {}
for idx, au in enumerate(author):
if au in author2doc.keys():
author2doc[au].append(idx)
else:
author2doc[au] = [idx]
# Text vectorization
dictionary = Dictionary(data)
dictionary.filter_n_most_frequent(50) # Filter the highest frequency 50 Word
corpus = [dictionary.doc2bow(text) for text in data]
atm = AuthorTopicModel(corpus, num_topics=10, author2doc=author2doc, id2word=dictionary)
atm.print_topics(num_words=20) # Before printing each topic 20 A theme word
author_topics = {au: atm.get_author_topics(au) for au in set(author)} # Author theme distribution
atm.save('atm.model') # Save the model