When looking for inspiration for topic selection , You usually need to read a lot of papers . Due to the limited level of English , Reading English is not fast enough , So I thought of an auxiliary arrangement WoS The method of recording documents in English papers , from WoS Export title 、 author 、 source 、 Information such as year and abstract , Then combine Google document translation and python-docx Put it in order Word file , For quick browsing of thesis topics 、 Distribution of methods , And quickly locate high-value papers that meet the needs , Finally, download these papers separately and read them carefully .
Catalog
1. WoS export Excel Bibliography
2. Machine translation
3. be based on python-docx Document generation and typesetting
4. Document output and sorting
5. Deficiencies and future prospects
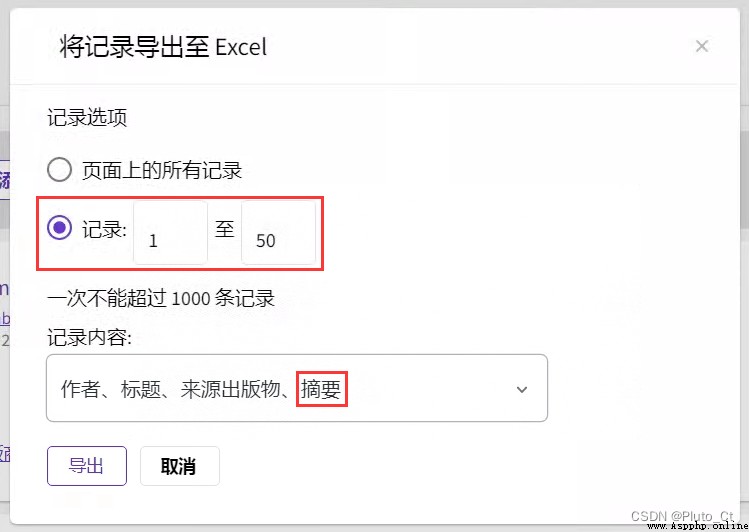
First, in the Web of Science Search literature in , Then select export Excel Format .
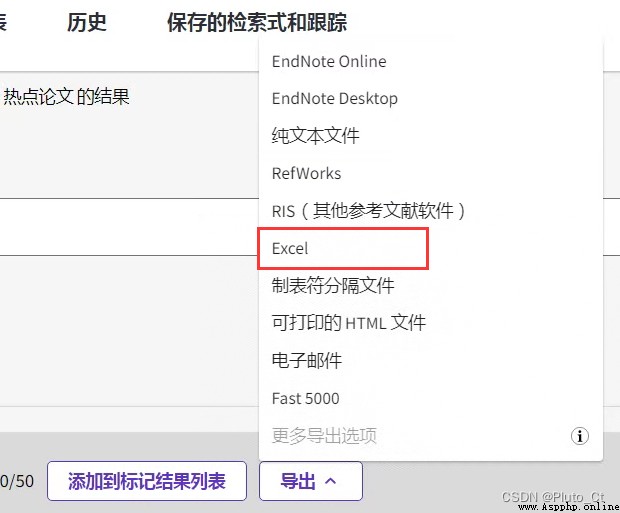
Select records in the pop-up box x To x, If less than 1000 Bars can be exported at one time ; Record content select the option that contains the summary .
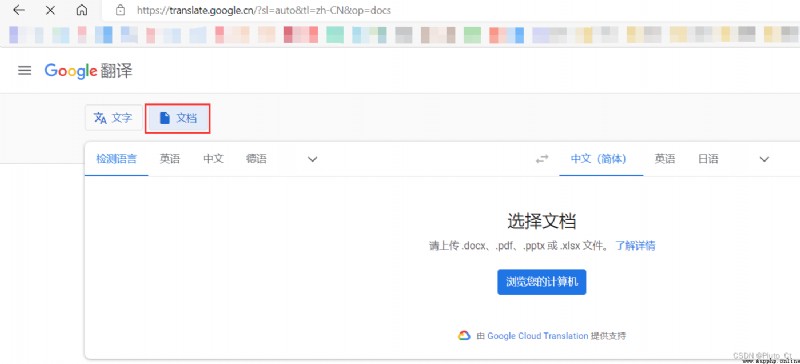
Baidu translation documents need members , youdao 、WPS The document translation of only supports Word、PPT、PDF Equiform , I won't support it Excel form . Google Translate is used here Excel file .
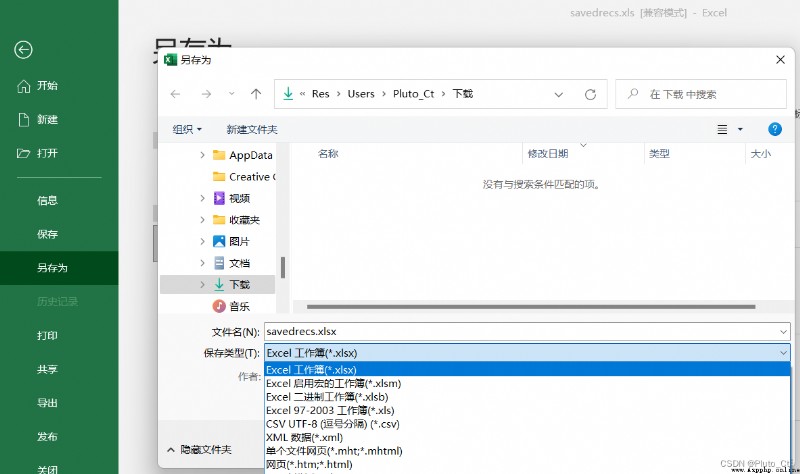
Because Google translate only supports xlsx Format , Need first xls Save it in a new format .
Very fast , A few seconds after uploading, you can download the translation .
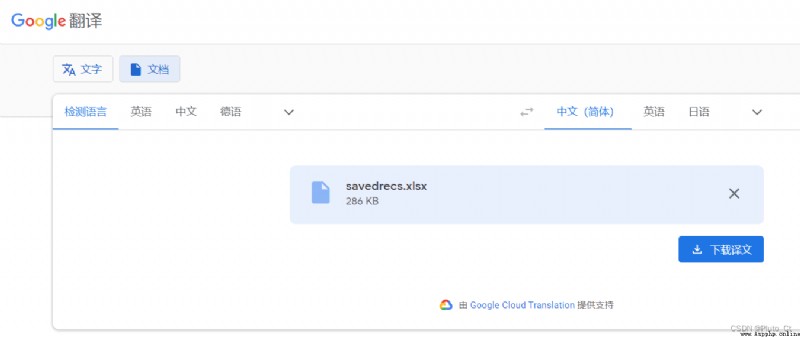
Name the downloaded translation 'savedrecs translation .xlsx', Put it in the same folder as the original document , Use Python The program integrates the two files and generates Word.
# -*- coding: utf-8 -*-
import pandas as pd
from docx import Document
from docx.enum.text import WD_ALIGN_PARAGRAPH
from docx.shared import Pt, RGBColor
from docx.oxml.ns import qn
df = pd.merge(pd.read_excel('savedrecs.xlsx')[['Article Title', 'Authors', 'Source Title', 'Publication Year']], pd.read_excel('savedrecs translation .xlsx')[[' Article title ', ' Source title ', ' In the abstract ']], left_index=True, right_index=True)[['Article Title', ' Article title ', 'Authors', ' Source title ', 'Source Title', 'Publication Year', ' In the abstract ']]
df.dropna(inplace=True)
document = Document()
document.styles['Normal'].font.size = Pt(12) # font size
document.styles['Normal'].font.name = 'Times New Roman' # Western Fonts
document.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), ' Song style ') # Chinese Fonts
document.styles['Normal'].paragraph_format.alignment = WD_ALIGN_PARAGRAPH.JUSTIFY # full-justified
document.styles['Normal'].paragraph_format.line_spacing = 1.15 # row spacing
document.styles['Normal'].paragraph_format.space_before = Pt(3) # Anterior segment
document.styles['Normal'].paragraph_format.space_after = Pt(3) # After amputation
document.styles['Normal'].paragraph_format.first_line_indent = document.styles['Normal'].font.size * 2 # The first line indentation
# Add the title , It may not work to change the style directly due to the version problem , Use here h、r2 Variables to adjust the title format , Namely paragraph and run Format
def add_heading_func(text, level, font_size, font_color=RGBColor(0, 0, 0), font_bold=True, line_spacing=1.15, first_line_indent=0, space_before=6, space_after=6, en_font='Times New Roman', cn_font=' Song style '):
h = document.add_heading(level=level)
r = h.add_run(text)
r.font.size = Pt(font_size) # font size
r.font.color.rgb = font_color # The font color
r.font.bold = font_bold # In bold
r.font.name = en_font # Western Fonts
r._element.rPr.rFonts.set(qn('w:eastAsia'), cn_font) # Chinese Fonts
if level == 0: # If it's a headline , In the middle , Western Fonts are the same as Chinese fonts
h.paragraph_format.alignment = WD_ALIGN_PARAGRAPH.CENTER
r.font.name = cn_font
else: # Other titles are aligned at both ends
h.paragraph_format.alignment = WD_ALIGN_PARAGRAPH.JUSTIFY
h.paragraph_format.first_line_indent = r.font.size * first_line_indent # The first line indentation
h.paragraph_format.line_spacing = line_spacing # row spacing
h.paragraph_format.space_before = Pt(space_before) # Anterior segment
h.paragraph_format.space_after = Pt(space_after) # After paragraph
add_heading_func(' Collation of thesis titles ', 0, 16, cn_font=' Microsoft YaHei ')
add_heading_func(' One 、 Category title 1', 1, 12, cn_font=' Microsoft YaHei ', en_font=' Microsoft YaHei ', font_bold=False)
add_heading_func('( One ) Category title 2', 2, 12)
for i in df.values: # Loop through the title table
add_heading_func(i[1] + '('+ i[0] + ')(' + str(i[5]) + ')', 3, 12, font_color=RGBColor(0x4f, 0x81, 0xbd))
document.add_paragraph(' source :' + i[4] + '('+ i[3] + ')')
document.add_paragraph(' author :' + i[2])
document.add_paragraph(i[6])
document.add_paragraph()
document.save(' Collation of thesis titles .docx') # Save the file
Python Generated Word The documents are as follows .
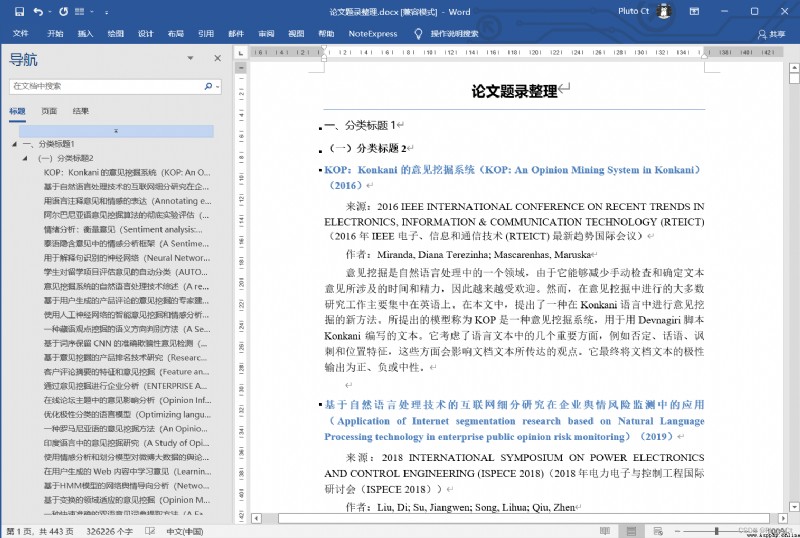
You can replace the title format into the style , It is convenient for further classification and typesetting .
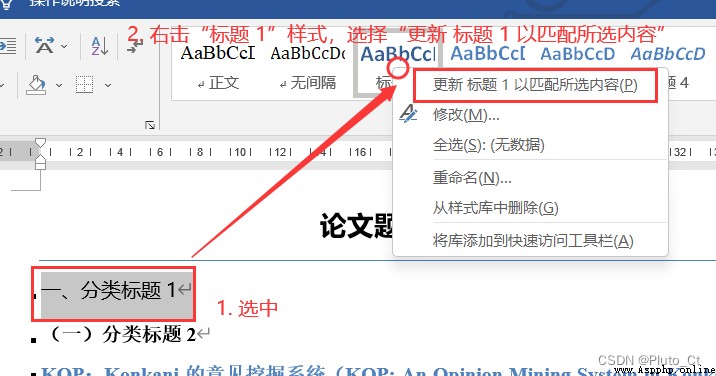
1. There are a few cells in Google Translate documents that have not been translated , Unknown cause , It is also necessary to manually check and correct the translated documents ; In the future, consider automatically identifying untranslated content , Supplement and translate ;
2. Maybe because of the version, the title style cannot be set directly , Modify to styles['Heading 1'] The style in does not work , A small amount of manual operation is still needed ;
3. Classification and sorting are all manual at present , In the future, we can consider combining TextRank、LDA And other algorithms to assist classification .
 Wuding taste sweetness is Jane, Python3 concurrent scenarios (CPU intensive/IO intensive) task of concurrent way scene choices (multiprocessing multi-thread threading/process/coroutines asyncio)
Wuding taste sweetness is Jane, Python3 concurrent scenarios (CPU intensive/IO intensive) task of concurrent way scene choices (multiprocessing multi-thread threading/process/coroutines asyncio)
原文轉載自「劉悅的技術博客」https://v3u.cn/a
 Python description leetcode 82 Delete duplicate Element II in the sorting linked list
Python description leetcode 82 Delete duplicate Element II in the sorting linked list
Python describe LeetCode 82. D