To complete this task , We need to import requests To get the data of the corresponding website , Import re Use regular expressions to intercept the required data ( For example, movie name , Score and the number of people scoring ), Import prettytable To format the output , Import csv The module writes data to csv In file . The specific import module code is as follows :
import requests
import re
import prettytable as pd
import csv
Because we use requests Only one page of leaderboard data can be requested at a time , There are a total of 25 Movie data , And we need to get Top250 The data of , So we need to get 10 Pages of data . Because we need to find the rule of paging , So as to use the loop to automatically obtain the data of each page and write it to the file . Click the link corresponding to the number of pages , You can easily find the rules , The specific URL links of each page are as follows :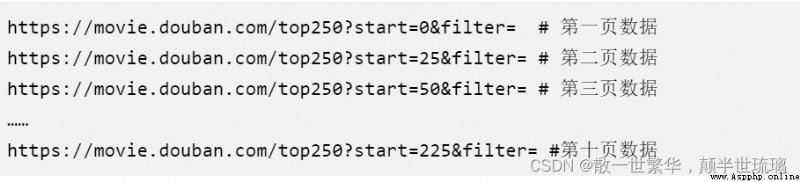
therefore , We can use a for Loop can access the link data of each page in turn , The details are as follows :
for i in range(10):
url = 'https://movie.douban.com/top250?start='+str(25*i)+'&filter='
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Mobile Safari/537.36'
}
response = requests.get(url, headers=headers)
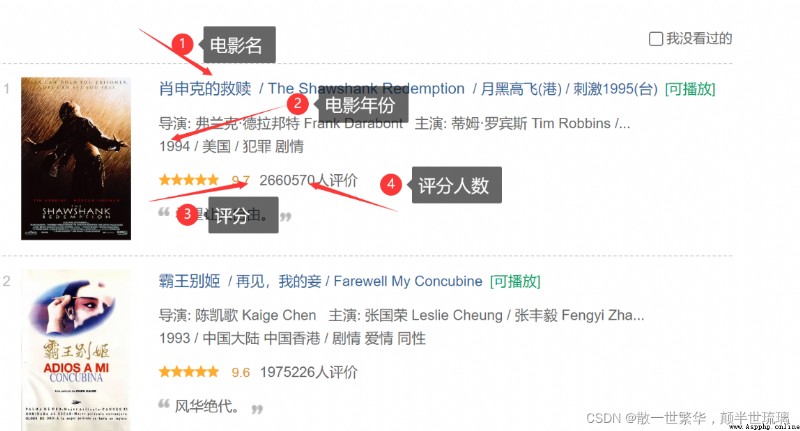
As shown in the figure below , What we need is the movie title , Movie year , Film ratings and the number of film ratings , On the corresponding website page Press down F12 Or right click to check Open developer tools , Select the icon shown in the following figure , Then click the information content to crawl , In this way, we can find the location of the information we need in many redundant codes .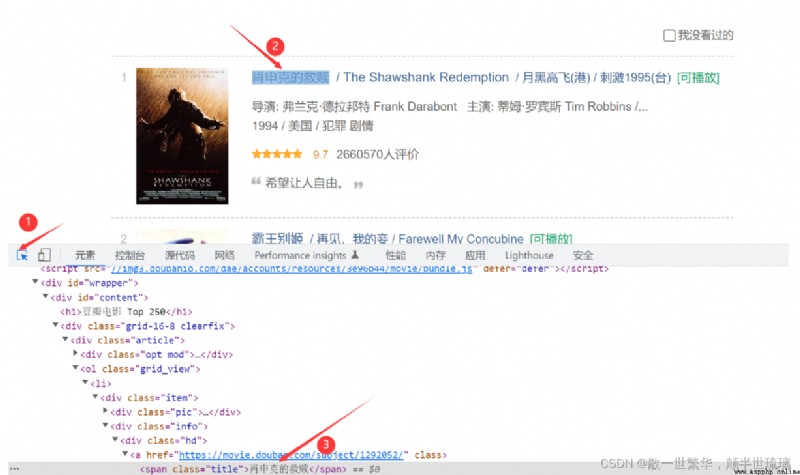
Find the location of the corresponding information , We can write regular expressions according to their hierarchical relationship to obtain the required content . The specific regular expression code is as follows :
p = re.compile(r'<li>.*?<span class="title">(?P<name>.*?)</span>.*?<br>(?P<year>.*?) '
r'.*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>'
r'.*?<span>(?P<num>.*?)</span>', re.S)
for it in p.finditer(response.text):
print(it.group('name'))
print(it.group('year'))
print(it.group('score'))
print(it.group('num'))
Here we need to pay attention to , Writing regular expressions requires attention to case , If you don't want to pay attention to case , We can set re.I Make it insensitive to case ,compile() The second parameter of the function is to set some optional flag modifiers to control the matching pattern , The modifier is specified as an optional flag , Multiple flags can be passed by biting OR(|) To specify the , Such as (re.I)|(re.M) Set to I and M sign . The specific modifiers and descriptions are shown in the following table :
The icing on the cake effect of this part of knowledge , It has no practical effect , It can be used to expand knowledge learning , If you are not interested, you can skip directly ! This part is equivalent to the data intercepted through regular expressions , Use prettytable Format the output , Make the output effect better , The specific operation code is as follows :
# Format output
table = pd.PrettyTable()
# Set the header
table.field_names = [' The movie name ', ' year ', ' score ', ' Number of raters ']
for it in p.finditer(response.text):
# Add table data
table.add_row([it.group('name'), it.group('year').strip(), it.group('score'), it.group('num')])
print(table)
The operation effect is as follows :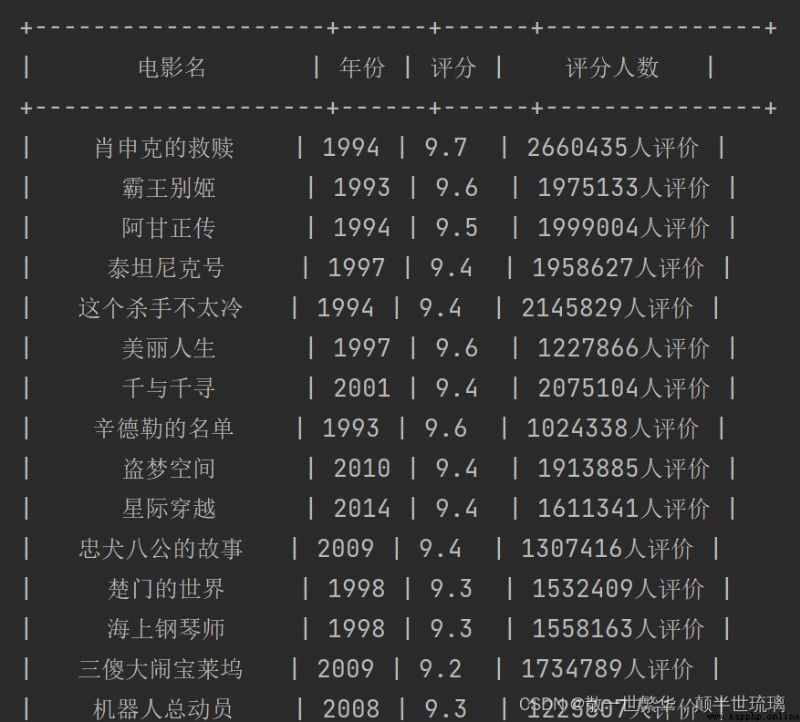
This part of the code is relatively simple , Don't repeat too much , The main thing is to open the file. The code is as follows :
# Open the file object as an append
f = open('data.csv', mode='a')
csv_write = csv.writer(f)
for it in p.finditer(response.text):
# Put the iterator it Convert to dictionary
dic = it.groupdict()
# Key pair is year Remove spaces from the value of
dic['year'] = dic['year'].strip()
# The dictionary values write in data.csv
csv_write.writerow(dic.values())
print(' Write completion ')
Here we need to pay attention to , If written csv The documents are in PyCharm Cannot display normally , We can download one CSV plug-in unit , Here you can PyCharm The data is displayed normally in . The specific operation steps are as follows :
Select the file with the mouse , Click settings below 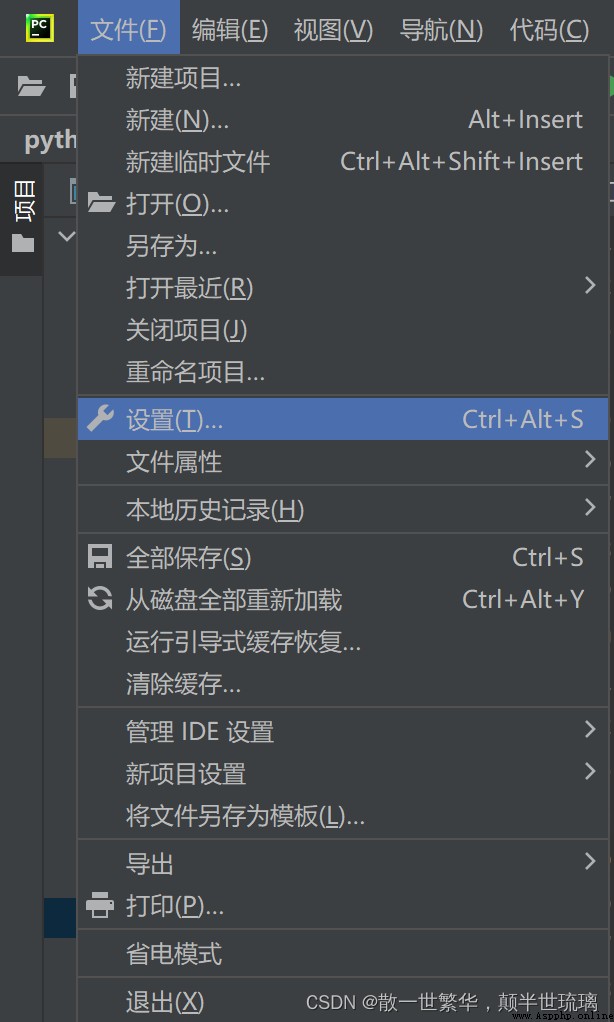
Open Settings , After the following interface appears , Choose plug-ins , Type in the search box CSV, Select the correct plug-in in the following CSV reader , Click Install and then restart .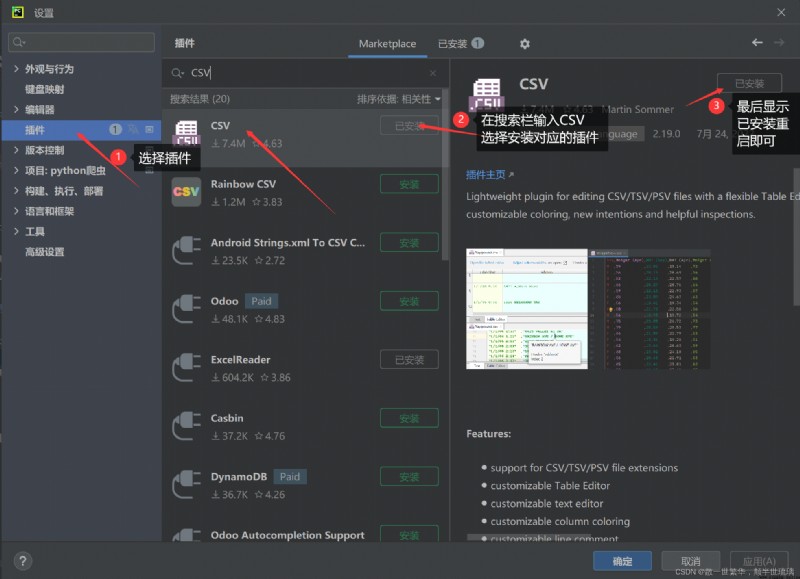
import requests
import re
import prettytable as pd
import csv
for i in range(10):
# The website of the ranking list
url = 'https://movie.douban.com/top250?start='+str(25*i)+'&filter='
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Mobile Safari/537.36'
}
response = requests.get(url, headers=headers)
result = response.text
p = re.compile(r'<li>.*?<span class="title">(?P<name>.*?)</span>.*?<br>(?P<year>.*?) '
r'.*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>'
r'.*?<span>(?P<num>.*?)</span>', re.S)
# Format output
table = pd.PrettyTable()
# Set the header
table.field_names = [' The movie name ', ' year ', ' score ', ' Number of raters ']
for it in p.finditer(result):
# Add table data
table.add_row([it.group('name'), it.group('year').strip(), it.group('score'), it.group('num')])
print(table)
# Open the file as an append
f = open('data.csv', mode='a')
csv_write = csv.writer(f)
for it in p.finditer(result):
# Put the iterator it Convert to dictionary
dic = it.groupdict()
dic['year'] = dic['year'].strip()
csv_write.writerow(dic.values())
print(' Write completion ')