pip install pdfplumber
pip install openpyxl
path = r"C:\Users\lenovo\Desktop\論文和面試\以客戶為中心.pdf"
pdf_mt = pdfplumber.open(path)
pdf_mt
# 獲取到數據所在頁 list --> [第一頁的對象,第二頁的對象,...第n頁的對象]
all_pages = pdf_mt.pages
all_pages
- 4.獲取pdf每一頁文本數據(前四十頁的文本數據)
for pdf_pg in all_pages[0:40]:
print(pdf_pg.extract_text())
for pdf_pg in all_pages[0:40]:
print(pdf_pg.extract_tables())
# 創建workbook對象
wb = Workbook()
# 激活工作表
ws = wb.active
for pdf_pg in need_pages:
# print(pdf_pg)
# 獲取每頁的文本內容
# print(pdf_pg.extract_text())
# 獲取表格內容 表格:二維 [[],[]]
# print(pdf_pg.extract_tables())
# 表格有行有列的二維數據,獲取二維的列表
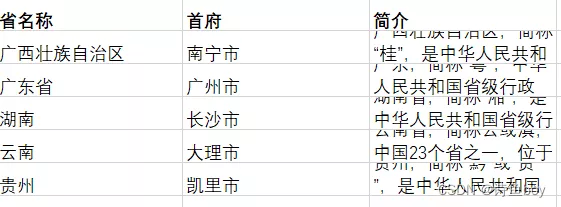
for pdf_tb in pdf_pg.extract_tables():
# print(pdf_tb)
# 將數據一行一行的寫入工作表
for row in pdf_tb:
ws.append(row)
wb.save("demo3.xlsx")