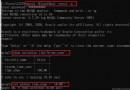
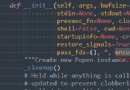
This is an example of an asynchronous crawler .
Create your own crawler class , Inherit Crawler class , rewrite parse Method , call run The method is crawling .
from urllib.parse import urlparse
import asyncio
import aiohttp
def save(content: any, filename: str, mode='a', encoding='utf-8', end='\n'):
with open(filename, mode=mode, encoding=encoding) as file:
if type(content) == str:
file.write(content + end)
else:
file.write(content)
print(f'The file is saved "{
filename}" successfully!')
class Crawler(object):
""" Reptilia , All reptiles should inherit this """
def __init__(self, start_url: list[str]) -> None:
""" initialization :param start_url: Crawler start list :param start_url: Crawler start list :param domain: domain name """
self.items = None
self.name = 'myspider'
self.start_url = start_url
self.domain = '{uri.scheme}://{uri.netloc}'.format(uri=urlparse(self.start_url[0]))
async def parse(self, response):
""" from response Resolve all directories in URL link """
raise NotImplementedError
async def request(self, url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
response = await self.parse(await resp.text())
url_object = urlparse(url)
return dict(response=response, url=url) # There is a return value
async def run(self):
tasks = [asyncio.ensure_future(self.request(i)) for i in self.start_url]
await asyncio.wait(tasks)
results = await asyncio.gather(*tasks) # Get the return value
self.handle(results)
print(" Task to complete ...")
def handle(self, items):
for item in items:
save(item.text(), "test.txt")
raise NotImplementedError