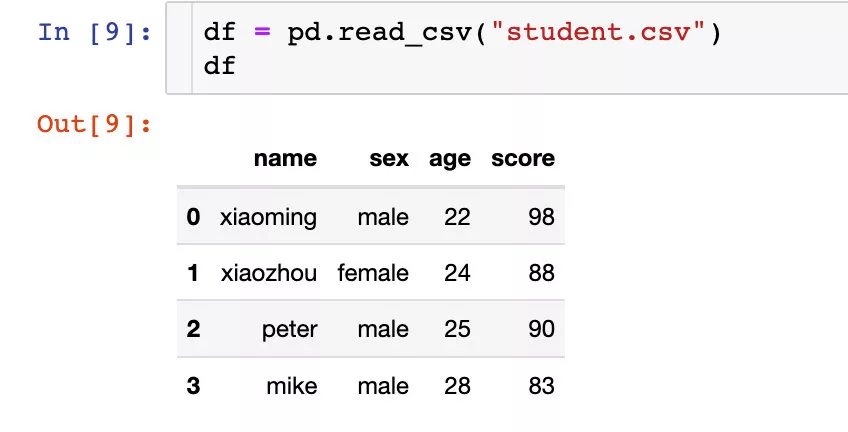
The most basic file operation .
Tips : The following is the main body of this article , The following cases can be used for reference
The files in a folder are divided into train and val data .
'''train:val=1.5:8.5'''
import os ,random,shutil # File operation module
import glob
def moveFile(all_img_dir,val_img_dir,all_txt_dir,val_txt_dir):
pathdir=os.listdir(all_img_dir)
filenumber=len(pathdir)
ratio=0.15 # Distribution ratio
picknumber=int(filenumber*ratio) # Number of files extracted int type
sample=random.sample(pathdir,picknumber) # Random sampling
for name in sample:
txtName=name[:-3]+"txt"
shutil.move(os.path.join(all_img_dir,name),os.path.join(val_img_dir,name)) # from A Move to B
shutil.move(os.path.join(all_txt_dir, txtName), os.path.join(val_txt_dir, txtName)) # from A Move to B
return
if __name__ == '__main__':
all_img_dir=r"./data/text_recog/zyx_data/submit_data/recog/low_score_v3p1/*.png"
val_img_dir=r"./data/text_recog/txt4val/img_gt1"
all_txt_dir=r"./data/text_recog/zyx_data/submit_data/recog/low_score_v3p1/*.txt"
val_txt_dir=r"./data/text_recog/txt4val/label1"
moveFile(all_img_dir,val_img_dir,all_txt_dir,val_txt_dir)
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import os
import random
import glob
import shutil
from shutil import copy2
trainpath = r"/data2/enducation/paper_recog_total/train-paper-recog/Recognization/deep-text-recognition-SHENG/data/text_recog/zyx_data/submit_data/recog/low_score_v3p1" #??????????????????txt?????
trainfiles_img=glob.glob(os.path.join(trainpath,"*.png"))
num_train = len(trainfiles_img)
print( "num_train: " + str(num_train) )
index_list = list(range(num_train))
print(index_list)
random.shuffle(index_list)
num = 0
trainDir_img = r'/data/text_recog/txt4train/img_gt2'#?????????7??????????
validDir_img = r'/data/text_recog/txt4val/img_gt2'#?????????3??????????
trainDir_txt=r'/data/text_recog/txt4train/label2'
validDir_txt=r'/data/text_recog/txt4val/label2'
for i in index_list:
filepPath=trainfiles_img[i]
files,fileName=os.path.split(filepPath)
txtname=fileName[:-3]+"txt"
txtpath=os.path.join(trainpath,txtname)
if num < num_train*0.85:
copy2(filepPath, trainDir_img)
copy2(txtpath,trainDir_txt)
print(f"train: {str(fileName)} -------> {str(txtname)}")
else:
copy2(filepPath, validDir_img)
copy2(txtpath, validDir_txt)
print(f"val: {str(fileName)} -------> {str(txtname)}")
num += 1
print(f"f{num} move success!")
among 10 A folder `.
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import os
import random
import glob
import shutil
from shutil import copy2
trainpath = r"/data2/datas/ocr/text_recog/ocr_data_2021.6.30/train"
trainfiles_img=glob.glob(os.path.join(trainpath,"*.png"))
num_train = len(trainfiles_img)
print( "num_train: " + str(num_train) )
index_list = list(range(num_train))
# print(index_list)
random.shuffle(index_list)
num = 0
trainDir_img = r'/data2/datas/ocr/text_recog/ocr_data_2021.6.30/all_train'
for i in index_list:
filepPath=trainfiles_img[i]
files,fileName=os.path.split(filepPath)
txtname=fileName[:-3]+"txt"
txtpath=os.path.join(trainpath,txtname)
# print(os.path.join(trainDir_img,"0"))
if num < num_train*0.10:
copy2(filepPath, os.path.join(trainDir_img,"0"))
copy2(txtpath,os.path.join(trainDir_img,"0"))
print(f"0: {str(fileName)} -------> {str(txtname)}")
elif num_train*0.10<=num < num_train*0.20:
copy2(filepPath, os.path.join(trainDir_img, "1"))
copy2(txtpath, os.path.join(trainDir_img, "1"))
print(f"1: {str(fileName)} -------> {str(txtname)}")
elif num_train*0.20<=num < num_train*0.30:
copy2(filepPath, os.path.join(trainDir_img, "2"))
copy2(txtpath, os.path.join(trainDir_img, "2"))
print(f"2: {str(fileName)} -------> {str(txtname)}")
elif num_train*0.30<=num < num_train*0.40:
copy2(filepPath, os.path.join(trainDir_img, "3"))
copy2(txtpath, os.path.join(trainDir_img, "3"))
print(f"3: {str(fileName)} -------> {str(txtname)}")
elif num_train*0.40<=num < num_train*0.50:
copy2(filepPath, os.path.join(trainDir_img, "4"))
copy2(txtpath, os.path.join(trainDir_img, "4"))
print(f"4: {str(fileName)} -------> {str(txtname)}")
elif num_train*0.50<=num < num_train*0.60:
copy2(filepPath, os.path.join(trainDir_img, "5"))
copy2(txtpath, os.path.join(trainDir_img, "5"))
print(f"5: {str(fileName)} -------> {str(txtname)}")
elif num_train*0.60<=num < num_train*0.70:
copy2(filepPath, os.path.join(trainDir_img, "6"))
copy2(txtpath, os.path.join(trainDir_img, "6"))
print(f"6: {str(fileName)} -------> {str(txtname)}")
elif num_train*0.70<=num < num_train*0.80:
copy2(filepPath, os.path.join(trainDir_img, "7"))
copy2(txtpath, os.path.join(trainDir_img, "7"))
print(f"7: {str(fileName)} -------> {str(txtname)}")
elif num_train*0.80<=num < num_train*0.90:
copy2(filepPath, os.path.join(trainDir_img, "8"))
copy2(txtpath, os.path.join(trainDir_img, "8"))
print(f"8: {str(fileName)} -------> {str(txtname)}")
else:
copy2(filepPath, os.path.join(trainDir_img, "9"))
copy2(txtpath, os.path.join(trainDir_img, "9"))
print(f"9: {str(fileName)} -------> {str(txtname)}")
num += 1
print(f"f{num} move success!")
import os
def Combine_txt():
dirpath_label = r"./data/text_recog/txt4train/label"
dirpath_img = r"/data/text_recog/txt4train/img_gt"
files = os.listdir(dirpath_label)
res = ""
for file in files:
if file.endswith(".txt"):
name = file[:-3] + "png"
img_path = os.path.join(dirpath_img, name)
txtpath = os.path.join(dirpath_label, file)
with open(txtpath, "r", encoding="utf-8") as file:
content = file.read()
text = img_path + "\t" + content
file.close()
input = "%s\n" % (text)
res += input
outpath = r"./data/text_recog/txt4train/img_gt/gt.txt"
with open(outpath, "w", encoding="utf-8") as outfile:
outfile.write(res)
outfile.close()
print(len(res))
if __name__ == '__main__':
Combine_txt()
import cv2
import os
image_path=r'.\data2'
# image_savepath=r'./compress_img'
# Value range :0~9, The smaller the numerical , The lower the compression ratio .
def Compress_img(proportion):
i = 0
for num in os.listdir(image_path):
for img_name in os.listdir(os.path.join(image_path,num)):
image_file=os.path.join(image_path,num,img_name)
image=cv2.imread(image_file)
# cv2.imwrite(f'./compress_jpg_img/{proportion}/{i}.jpg',image,params=[cv2.IMWRITE_JPEG_QUALITY, proportion])
'''[cv2.IMWRITE_JPEG_QUAITY,50] Can achieve image compression .
Its value is [0,100].0 The image can be greatly compressed , But the quality of the image will be greatly reduced .'''
cv2.imwrite(f'./compress_jpg_img/{proportion}/{i}.jpg', image,params=[cv2.IMWRITE_PNG_COMPRESSION, proportion])
'''[cv2.IMWRITE_PNG_COMPRESSION,0] It's adjustment PNG Image compression ratio .
by 0 when , The compression ratio is the smallest , The quality of the image is the best . Its compression range is [0,9]'''
print(f'{proportion}---{num}---{img_name}Saved successfully!')
i+=1
if __name__ == '__main__':
# Compression range 4-9 PNG Value range :0~9, The smaller the numerical , The lower the compression ratio .
# Compression range 40-100 JPG Value range :0~100, The smaller the numerical , Higher compression ratio , The more serious the loss of image quality .
list=[45,50,55,60,65,70,75,80,85,90]
for proportions in list:
if not os.path.exists(rf'./compress_jpg_img/{proportions}'):
os.makedirs(rf'./compress_jpg_img/{proportions}')
Compress_img(proportions)
Before turning :
# !/usr/bin/python
# -*- codding: cp936 -*-
from openpyxl import load_workbook
from openpyxl.drawing.image import Image
import os
excel_address = r"E:\enducate\practice\movefile\txt2excel\train.xlsx"
img_path=r"E:\enducate\practice\movefile\val\img_gt"
txtfile = r'E:\enducate\practice\movefile\val\label'
wb = load_workbook(excel_address)
sht = wb.worksheets[0]
for i,img_name in enumerate( os.listdir(img_path)):
num=img_name[:-3]
txtname=num+"txt"
sht.cell(i + 1, 1, num)
with open(os.path.join(txtfile,txtname),"r", encoding='utf-8') as f:
for line in f.readlines():
# strip ??????????
line = line.strip('\n')
# ?','???'\t',????????????????????????
line = line.replace("\t",",")
line = line.split(',')
# ??7???
for index in range(len(line)):
sht.cell(i+1, 2, line[index])
# ????
img_address_1 = os.path.join(img_path,img_name)
img = Image(img_address_1)
#??????
# img.width = 19.0
# img.height = 39.0
sht.add_image(img, f'C{i+1}')
sht.column_dimensions['A'].width = 60.0
sht.column_dimensions['B'].width = 60.0
sht.column_dimensions['C'].width = 60.0
sht.row_dimensions[i+1].height = 60.0
wb.save(excel_address)
After the turn :