從圖像處理到數據分析。。。硬接活啊,就當做對自己的一種歷練了。
需求介紹:
讀入的數據表格中有很多缺失值,由於數據量很大,不需要對缺失值進行中值填充、均值填充,直接刪除即可。每一條數據都有很多特征。。。
像這樣:x1,x2,x3,x4,nan,x6,x7,y
x表示特征值,y表示該條數據的標簽,nan表示空值
廢話不多說,直接上代碼:
導包、構建虛擬的數據集
import numpy as np
import pandas as pd
n = 7
DataList = [[str(n-i) for j in range(n-i)]+[np.nan for j in range(i)] for i in range(n)]
df = pd.DataFrame(DataList)
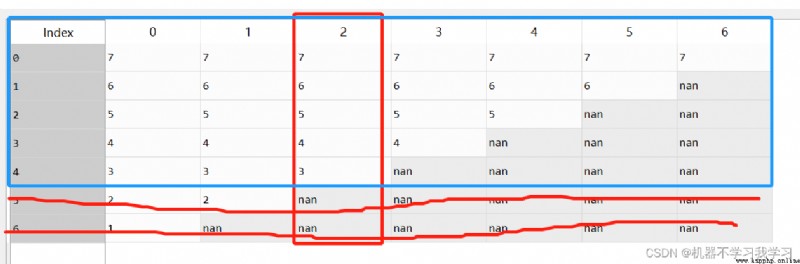
df 如下: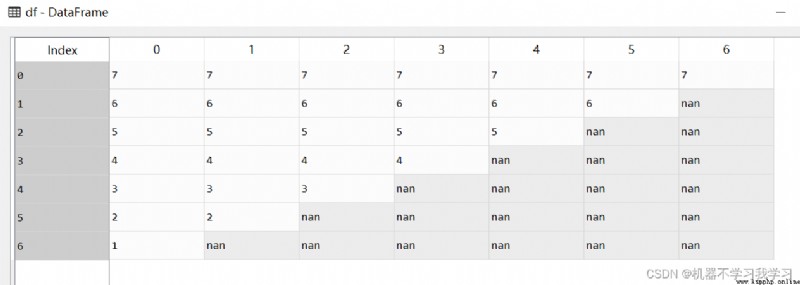
1.默認參數
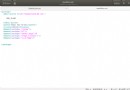
df.dropna()
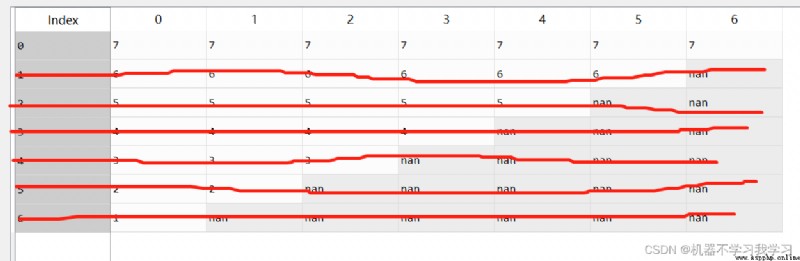
2.axis
df.dropna(axis=1)
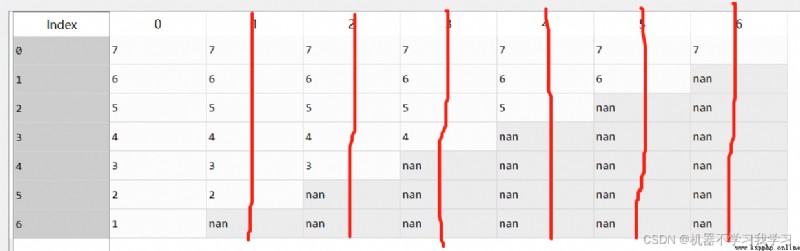
3.how
df.dropna(how="all") # 刪除全部為空值的行
本立中沒有全部為空值的行,數據不動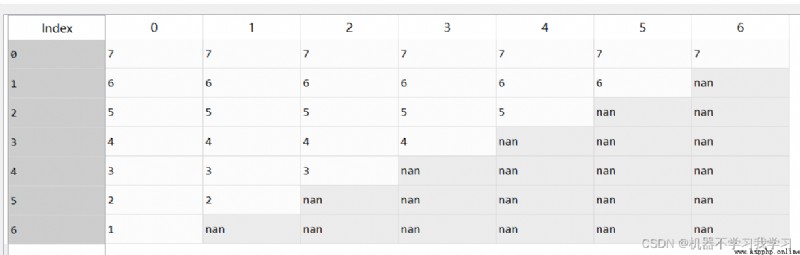
df.dropna(how="any") # 刪除該行只要有一個以上的空值
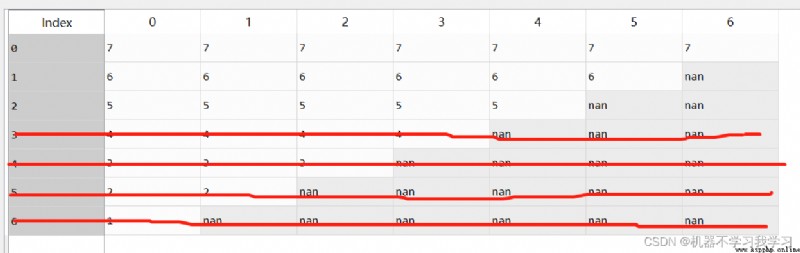
4.thresh
根據設定的阈值進行刪除。
df.dropna(thresh=3) # 刪除空值數量大於等於3的行
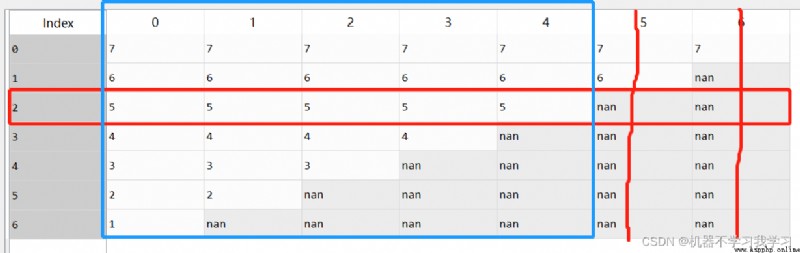
5.subset
根據設定的子集進行刪除。
df.dropna(subset=[2],axis=1) # 刪除索引為2的行中,存在空值的列
df.dropna(subset=[2],axis=0) # 刪除索引為2的列中,存在空值的行