From image processing to data analysis ... Hard work , As a kind of experience for yourself .
Demand is introduced :
There are many missing values in the read data table , Because of the amount of data , There is no need to fill the missing values with median 、 Mean filling , Just delete it . Every piece of data has many characteristics ...
like this :x1,x2,x3,x4,nan,x6,x7,y
x Represents the characteristic value ,y Label indicating this piece of data ,nan Indicates null value
I don't say much nonsense , Go straight to the code :
Guide pack 、 Build virtual datasets
import numpy as np
import pandas as pd
n = 7
DataList = [[str(n-i) for j in range(n-i)]+[np.nan for j in range(i)] for i in range(n)]
df = pd.DataFrame(DataList)
df as follows :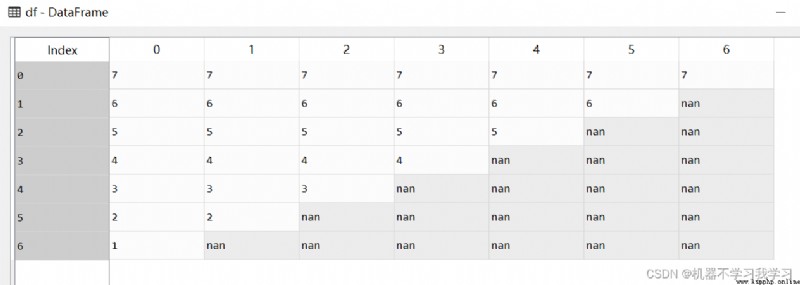
1. Default parameters
df.dropna()

2.axis
df.dropna(axis=1)
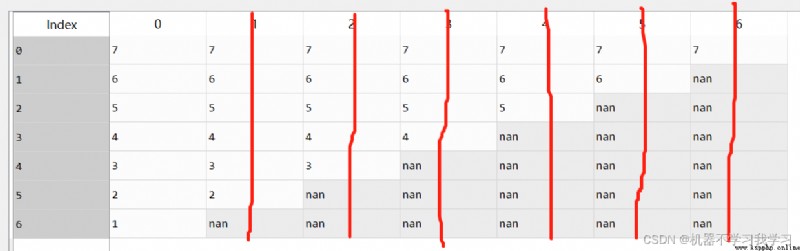
3.how
df.dropna(how="all") # Delete all rows with null values
There are no rows with null values in this column , The data doesn't move 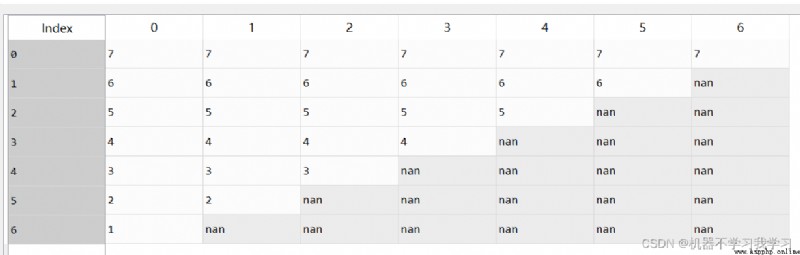
df.dropna(how="any") # Delete this line as long as there is more than one null value
4.thresh
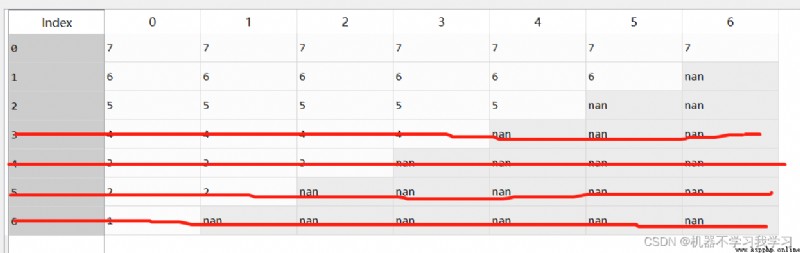
Delete according to the set threshold .
df.dropna(thresh=3) # The number of deleted null values is greater than or equal to 3 The line of
5.subset
Delete according to the set subset .
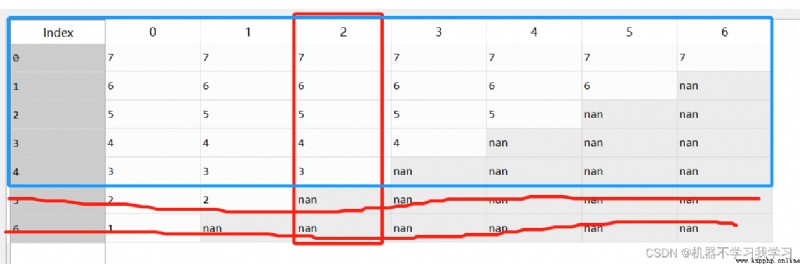
df.dropna(subset=[2],axis=1) # Delete index as 2 Row in , Column with null value
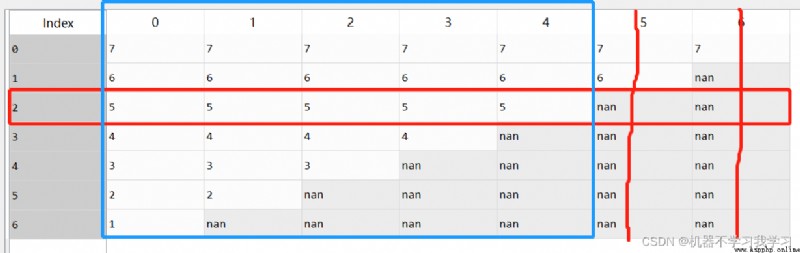
df.dropna(subset=[2],axis=0) # Delete index as 2 In the column of , Rows with null values