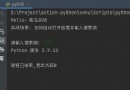
1,直接在html代碼中添加“charset="text/html;utf-8”。
這個方法,會直接讓浏覽器使用gbk編碼模式。這雖然可以解決網頁亂碼的問題,但不能根本解決編碼問題。如果你後面確定不使用含有中文的一些函數操作,那麼你可以使用這個方法,否則不推薦使用。

這裡舉例說明一下,如下所示:
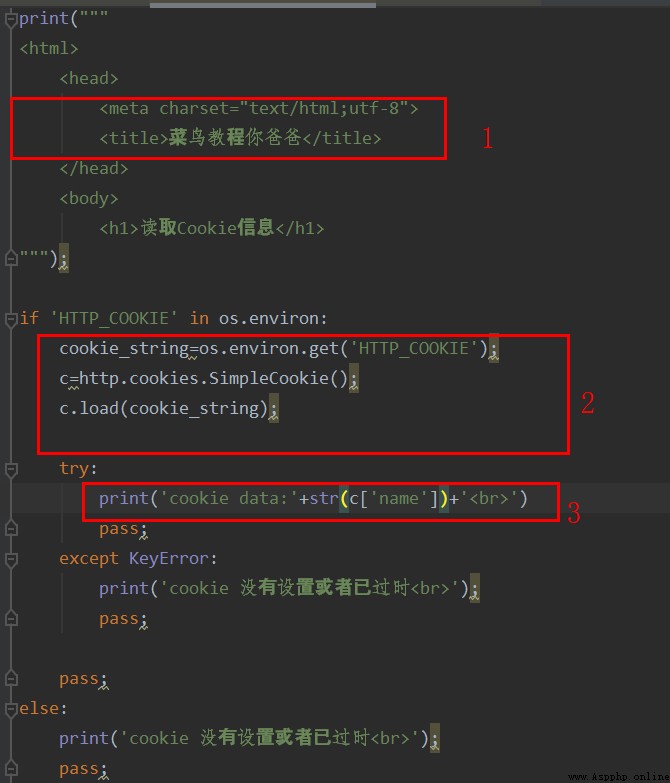
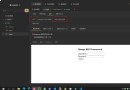
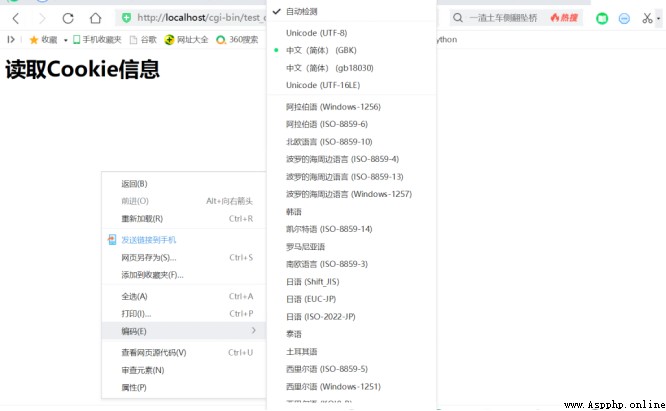
標號1位置的代碼,表面浏覽器會采用gbk的編碼模式,事實也確實如此。運行後如圖所示:
標記2、3位置的代碼,就是用獲取之前網頁設置的cookie。這時候浏覽器運行這段腳本的時候就出錯了。打開apache24中的log文件,在erro中我們可以看到錯誤日志,如下圖所示:

通過這四個紅色框,我們就發現了腳本運行出錯的根本原因,最後一個紅色框裡已經說明了:
AH01215: UnicodeEncodeError: 'gbk' codec can't encode character '\\x8f'
這個錯誤,說直白一點,就是編碼出問題了,網頁代碼用的是gbk編碼,而python腳本用的是utf-8編碼,所以在使用print打印時,apache報錯了或者直接亂碼顯示。
那麼為了避免這些問題,我推薦大家使用第二個解決網頁編碼、亂碼的方法。
2,python文件中,指明控制台的編碼的方式,即添加:
import sys
sys.stdout=codecs.getwriter('utf-8')(sys.stdout.buffer);
這兩句代碼,類似於java中的輸出流套接方法,getwriter(“utf-8”)返回一個streamwritter(‘parameter’)函數,而sys.stdout.buffer就作為參數,供streamwritter(‘parameter’)使用。這樣就指明了sys.stdout標准輸出流的編碼方式為utf。
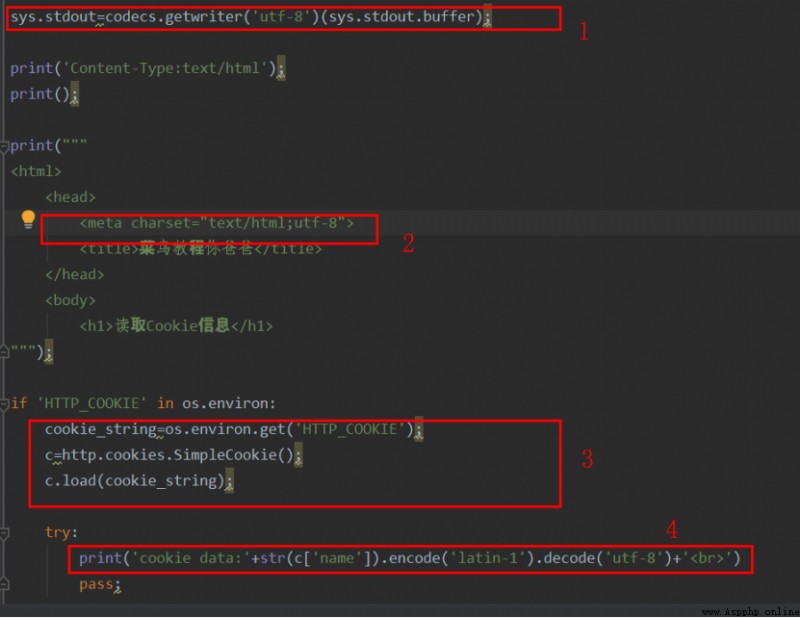
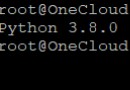
如此一來,整個網頁的編碼方式就是’utf’了。如上圖所示,添加標記1的代碼後,整個網頁的編碼都是utf-8了,如下圖運行所示:

解決了整個網頁編碼的問題,最後我們還要解決python函數調用cookie時出現的亂碼問題。如圖標記4所示,我們需要對從cookie中獲取的字段值進行編碼,最終輸出utf-8編碼的內容,即采用這段代碼:
‘your getting str’.encode(‘latin-1’).decode(‘utf-8’)
這裡需要注意一個點:cookie采用latin-1的編碼模式,所以我們要用encode將cookie的字段內容按latin-1來解碼,最後再utf-8編碼成字符串。最終,這個腳本運行結果就正確了!如上面最後一張圖所示,這個python文件正確讀出了cookie的字段值。

我是科學財子,一個正在學習python的新人程序員,立志從事測試、游戲開發、大數據、AI方向!關注我,不定時為你分享python編程干貨!每天進步一小點,每天成長一大步!