Gensim中的主題模型包括三種,分別是LDA (Latent Dirichlet Allocation) 主題模型、加入了作者因素的作者主題模型 (Author-Topic Model, ATM) 和加入了時間因素的動態主題模型 (Dynamic Topic Models, DTM) 。
作者主題模型(ATM)的輸入除了分詞後的文章內容,還包括作者和文章的對應關系;模型的輸出為每位作者對於每個主題(主題數n可以自己設定)的傾向度。
LDA主題模型在許多研究中都已廣泛應用,在網上也有相當多的程序資料,但ATM模型的相關代碼資料卻不甚完整,在前段時間比賽查找資料的過程中也遇到了一些困擾,後來看了英文的官方文檔才得以解決。因此本文介紹Gensim包中ATM模型完整實現的過程,完整代碼附在最後。
目錄
1. ATM模型原理
2. Author-Topic Model的英文文檔
3. Python調用Gensim的實現過程
3.1 導入相關包
3.2 准備數據
3.3 文本向量化
3.4 模型訓練
3.5 模型結果輸出
3.6 模型保存和載入
4. 完整實現
Author Topic Model解析_chinaliping的博客-CSDN博客 https://blog.csdn.net/chinaliping/article/details/9299953
https://blog.csdn.net/chinaliping/article/details/9299953
Author Topic Model[ATM理解及公式推導]_HFUT_qianyang的博客-CSDN博客參考論文Modeling documents with topicsModeling authors with wordsThe author-topic modelGibbs sampling algorithms詳細經典LDA模型目標分布及參數Author Model目標分布及參數Author-topic model目標分布及參數本文作者:合肥工業大學 管理學院 錢洋 email: https://qianyang-hfut.blog.csdn.net/article/details/54407099
https://qianyang-hfut.blog.csdn.net/article/details/54407099
models.atmodel – Author-topic models — gensim (radimrehurek.com)https://radimrehurek.com/gensim/models/atmodel.html
from gensim.corpora import Dictionary
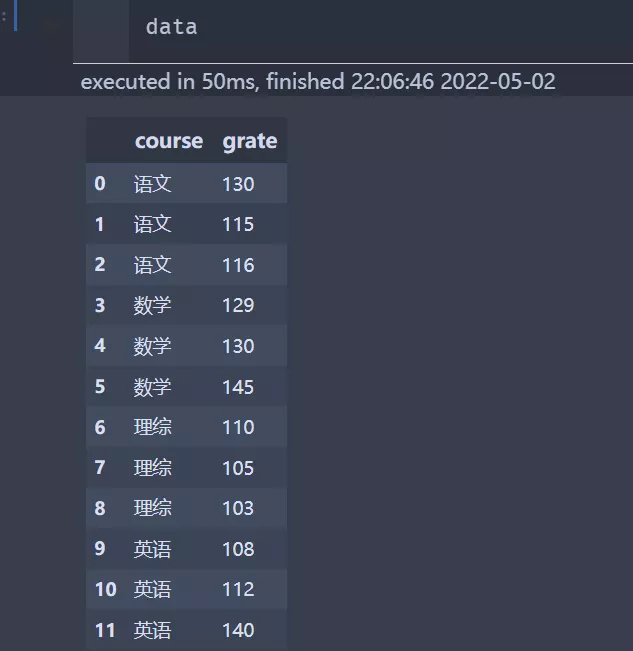
from gensim.models import AuthorTopicModelATM模型需要的數據主要包括:
# 這裡是使用pandas的DataFrame來讀取csv表格中的數據,其中包含分詞、作者等信息。
import pandas as pd
df = pd.read_csv('data.csv')
# 數據中的“分詞”列是用空格分隔的詞語,如果數據沒有分詞,還需要使用jieba等分詞工具進行分詞
df['分詞'] = df['分詞'].map(lambda x: x.split()) # 用split還原成列表
data = df['分詞'].values.tolist() # 每篇文章的分詞列表,每個內層列表包含一篇文章的內容
# 示例:[['我', '喜歡', '貓'], ['他', '喜歡', '狗'], ['我們', '喜歡', '動物']]
author = df['作者'].values.tolist() # 每篇文章的作者列表
# 示例:['作者1', '作者2', '作者1']
# 將作者和文章的對應關系轉換為模型需要的格式
author2doc = {}
for idx, au in enumerate(author):
if au in author2doc.keys():
author2doc[au].append(idx)
else:
author2doc[au] = [idx]
# 轉換後示例:{'作者1': [0, 2], '作者2': [1]}這裡采用的是詞袋模型,將每一篇文章轉換為BOW (Bag of words) 向量,可以用filter_n_most_frequent()過濾高頻詞。
dictionary = Dictionary(data)
dictionary.filter_n_most_frequent(50) # 過濾最高頻的50個詞
corpus = [dictionary.doc2bow(text) for text in data]訓練ATM模型,如果數據量較大可能需要比較久的時間,其中num_topics參數可以設定目標的主題個數,這裡為10。
atm = AuthorTopicModel(corpus, num_topics=10, author2doc=author2doc, id2word=dictionary)獲取每個主題的主題詞及其權重,其中num_words參數可以控制每個主題輸出的主題詞數量。
atm.print_topics(num_words=20)獲取某位作者的主題分布
atm.get_author_topics('作者1')每位作者的主題分布
author_topics = {au: atm.get_author_topics(au) for au in set(author)}保存模型訓練結果,需要注意的是模型文件不止一個,載入時也需要保持完整,不可刪除。
atm.save('atm.model')載入模型
atm = AuthorTopicModel.load('atm.model')from gensim.corpora import Dictionary
from gensim.models import AuthorTopicModel
import pandas as pd
df = pd.read_csv('data.csv')
# 數據中的“分詞”列是用空格分隔的詞語,如果數據沒有分詞,還需要使用jieba等分詞工具進行分詞
df['分詞'] = df['分詞'].map(lambda x: x.split()) # 用split還原成列表
data = df['分詞'].values.tolist() # 每篇文章的分詞列表
author = df['作者'].values.tolist() # 每篇文章的作者列表
# 將作者和文章的對應關系轉換為模型需要的格式
author2doc = {}
for idx, au in enumerate(author):
if au in author2doc.keys():
author2doc[au].append(idx)
else:
author2doc[au] = [idx]
# 文本向量化
dictionary = Dictionary(data)
dictionary.filter_n_most_frequent(50) # 過濾最高頻的50個詞
corpus = [dictionary.doc2bow(text) for text in data]
atm = AuthorTopicModel(corpus, num_topics=10, author2doc=author2doc, id2word=dictionary)
atm.print_topics(num_words=20) # 打印每個主題前20個主題詞
author_topics = {au: atm.get_author_topics(au) for au in set(author)} # 作者主題分布
atm.save('atm.model') # 保存模型