So its outsourcing has always been very expensive ,
Some companies even use it for interviews , It can be seen that his difficulty .
It's not worth money !
Don't talk much , Let's code !
There are not so many steps today , Go straight to the code !
import requests
import parsel
url = 'https://www.dianping.com/search/keyword/344/0_%E7%81%AB%E9%94%85/p2'
headers = {
'Cookie': 'fspop=test; cy=344; cye=changsha; _lxsdk_cuid=181f2b8ceedc8-00c68dfc700b1e-c4c7526-384000-181f2b8ceedc8; _lxsdk=181f2b8ceedc8-00c68dfc700b1e-c4c7526-384000-181f2b8ceedc8; _hc.v=fa46cfdd-99f6-80af-c226-f8777fc1f097.1657634607; s_ViewType=10; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; Hm_lvt_602b80cf8079ae6591966cc70a3940e7=1657634608,1657690542; lgtoken=0ecd60582-14f9-4437-87ad-7b55881b56df; WEBDFPID=3x389w8ww1vw5vuzy491zvxxu36989x2818u39v38389795895568429-1657776946569-1657690545731QSUUAWGfd79fef3d01d5e9aadc18ccd4d0c95072230; dper=6cfaf0f82f34d241b584d587fc92a7117ba6c082354d350ed861c0a256d00ba3beb93db7dc5485b4e2e4e4085a92126fa2e5f1dbe1b6eaefd1c814167fce943e; ll=7fd06e815b796be3df069dec7836c3df; Hm_lpvt_602b80cf8079ae6591966cc70a3940e7=1657690573; _lxsdk_s=181f60e4e6c-cad-fea-c91%7C%7C40',
'Host': 'www.dianping.com',
'Referer': 'https://www.dianping.com/search/keyword/344/0_%E7%81%AB%E9%94%85',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
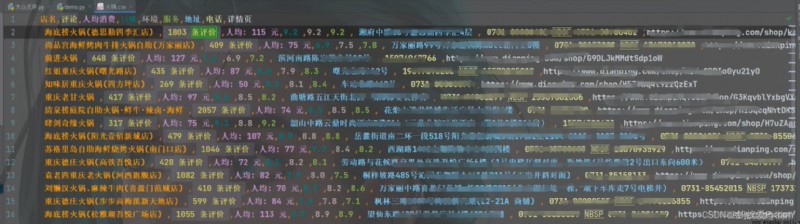
href = selector.css('.shop-list ul li .pic a::attr(href)').getall()
print(href)
for index in href:
html_data = requests.get(url=index, headers=headers).text
selector_1 = parsel.Selector(html_data)
title = selector_1.css('.shop-name::text').get() # Shop name
count = selector_1.css('#reviewCount::text').get() # Comment on
Price = selector_1.css('#avgPriceTitle::text').get() # Per capita consumption
item_list = selector_1.css('#comment_score .item::text').getall() # evaluation
taste = item_list[0].split(': ')[-1] # Taste score
environment = item_list[1].split(': ')[-1] # Environmental score
service = item_list[-1].split(': ')[-1] # Service rating
address = selector_1.css('#address::text').get() # Address
tel = selector_1.css('.tel ::text').getall()[-1] # Telephone
dit = {
' Shop name ': title,
' Comment on ': count,
' Per capita consumption ': Price,
' taste ': taste,
' Environmental Science ': environment,
' service ': service,
' Address ': address,
' Telephone ': tel,
' Details page ': index,
}
print(dit)
I won't comment , A little in a hurry , My girlfriend asked me to have dinner !

 The code in this article only crawls part of the content ,
The code in this article only crawls part of the content ,
The video also explains how to make the data better , Multi page crawling ,
preservation Excel Forms, etc .
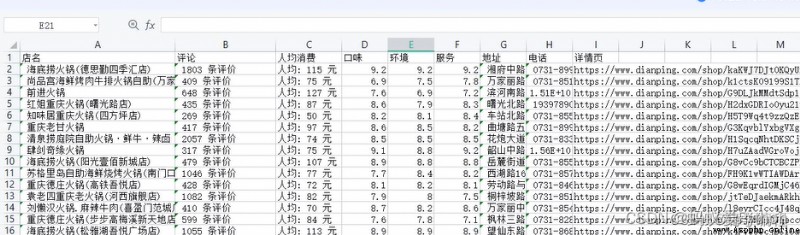
Show you the effect