寫這篇文的目的在於記錄一下看到並實踐了的一些內容:今天分享的是基於SODA大賽公開數據集當中,一卡通數據集的簡單清洗,數據的獲取可以直接去SODA官網溜一圈看一下,數據內容如下:
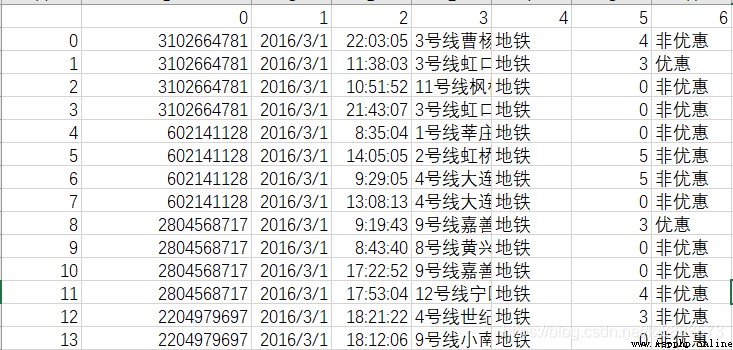
根據數據說明:0代表一卡通卡號,1代表日期,2代表時間,3代表使用卡的地點,4代表交通方式,5代表花費,6代表卡的類型。那麼有力這些信息我們要做什麼呢,首先明確作業目標才能圍繞目標進行清洗策越的制定,對了,得到的數據是csv格式,我人為改了一下,把數字標題替換成了,cardId,date,time,station,way,cost,discount等文字標題並存成了xls格式,其實,不這麼做也不影響接下來的分析工作,因為本文要用的pandas其實已經提供了讀取excel和csv的方法;
好了回到正題,我們的作業內容,其實我們知道一般正常的乘車操作流程應該是:進站->出站,那麼這個過程中是有cardId相同的卡所發出的一組行為,而一組正常的消費行為應該是:進站(cost = 0)->出站(cost > 0),對同對這些行為的判讀我們可以從數據中提取出某一名乘客(一卡通),從哪一站上車到哪一站下車,中途的花費,路程時間等信息。好了,有了作業目標我們應該好好分析下數據,所謂清洗重要的一點就是對髒數據的剔除,其實在眾多數據中,會存在如下的擾亂信息:(1)只有進站或出站信息,缺少進站或出站信息;(2)有進出站信息但是兩次消費結果均為0,或者兩次消費結果均不為0;
針對上面的情況就是我們需要提出的髒數據,因為髒數據的存在會影響我們正常的數據分析行為,當然髒數據也有它的價值,比如我們可以針對髒數據進行一定分析,髒數據的出現因素,針對情況(1)的髒數據其可能出現的情況可能是因為某個乘客逃票,或者漏刷導致的,如果有許多乘客都在某一站點發生信息缺失的情況,那是不是說明該站點的機器存在問題或者是該站點附近存在什麼特殊的組織.....
好了上家伙,錯了,是上代碼,本文主要用到pandas,xlrd,xlwt如果運行過程中報了缺少某個模塊,請自行腦補上,啊不是,是自行安裝上:
import pandas as pd
import xlrd
import xlwt#首先我們要讀取數據:
df=pd.read_excel(excel_Path)#如果是csv就用read_csv#讀取出行方式為地鐵的數據
df = df[df['way'] == '地鐵']
#把時間和日期字段相連,整合為datetime格式
df["date"] = df["date"].apply(lambda x:x.strftime("%Y-%m-%d"))
df["time"] = df["time"].apply(lambda x:x.strftime("%H:%M:%S"))
df["time"] = df['date']+' '+df['time']
df["time"] = pd.to_datetime(df["time"])
#根據卡號和日期進行排序
df = df.sort_values(['cardId','time'])
通過上面的代碼基本可以出現一下效果了:
cardId date time station way cost discount
290 2856179 2016-03-01 2016-03-01 14:59:03 9號線打浦橋 地鐵 0 非優惠
291 2856179 2016-03-01 2016-03-01 15:13:46 9號線桂林路 地鐵 3 優惠
746 2903472 2016-03-01 2016-03-01 17:03:36 7號線長壽路 地鐵 0 非優惠
745 2903472 2016-03-01 2016-03-01 17:20:03 10號線新天地 地鐵 3 非優惠
298 100661308 2016-03-01 2016-03-01 08:01:28 1號線莘莊 地鐵 0 非優惠
go on:
#添加新的列
#shift函數用於將整體的行進行移動,正數代表整體下移,擠掉最後的;負數代表整體上移,擠掉最上的
df['id_latter'] = df['cardId'].shift(-1)
df['id_former'] = df['cardId'].shift(1)
df['total_cost'] = df['cost'].shift(-1)
df['des_station'] = df['station'].shift(-1)
df['des_time'] = df['time'].shift(-1)
到此我們需要的一些准備基本就完成了,那麼現在開始對髒數據進行清理:按照之前我們說的情況可以做出一下的邏輯判斷:
def judge_vaild(df):
if (df['cost'] == 0) & (df['id_latter'] > 0) & (df['cardId'] == df['id_latter']):
vaild = 1
elif (df['cost'] > 0) & (df['total_cost'] == 0) & (df['cardId'] == df['id_former']):
vaild = 1
else:
vaild = -1
return vaild
數據是一條一條進行邏輯篩選,且已經經過了上門的排序。邏輯上就是判斷如果當前的cost等於0那麼理論上你應該是進站點,對應的下一站cost應該大於0,那麼該條記錄應該為有效的數據,如果當前cost大於0,理論上應該為出站點,那麼該條記錄的上一條記錄在cost上應該為0。
然後刪除掉髒數據:
df.drop(index=(df.loc[(df['vaild'] ==-1)].index),inplace=True)
其實至此,數據的清洗就基本完成了,我可以簡單的打印以及輸出excel:
df['cost_time'] = df.apply(lambda x: x['des_time']-x['time'],axis=1)
df.drop(index=(df.loc[(df['cost']!=0)].index),inplace=True)
df.to_excel(out_path)
df = df[['cardId','station','des_station','total_cost','cost_time','way','discount']]
結果如下:
cardId station des_station total_cost cost_time way discount
290 2856179 9號線打浦橋 9號線桂林路 3.0 00:14:43 地鐵 非優惠
746 2903472 7號線長壽路 10號線新天地 3.0 00:16:27 地鐵 非優惠
298 100661308 1號線莘莊 1號線黃陂南路 4.0 00:51:36 地鐵 非優惠
296 100661308 1號線黃陂南路 1號線莘莊 4.0 00:33:13 地鐵 非優惠
其實數據分析結果應該用可視化的圖表之類的進行展示,奈何,暫且還沒get到這項技能,今天的分享也只是看了別人的對象親手實踐了一下。關於本文的具體一些內容及可視化結果可以去 微信公眾號搜索:Yuan的數據分析,當然該公眾號與博主無關,但是是本文的參考對象,本文實踐內容及參考代碼均來自於其分享的某篇文章。
 Python - Matplotlib drawing library use detailed 1 (column chart, line chart, pie chart, scatter chart, box chart)
Python - Matplotlib drawing library use detailed 1 (column chart, line chart, pie chart, scatter chart, box chart)
一、基本介紹 (1) Matplotlib 是 Pytho
 Python implementation of student information management (object-oriented)
Python implementation of student information management (object-oriented)
Catalog The official code is