今天來看一下一些爬蟲過程的小技巧或者說是一些注意或者是坑的地方,因為博主也是剛入門,所以也是把一些學到的對象進行分享,那麼第一個坑:在浏覽網頁的時候我們經常會看到這樣的東西:
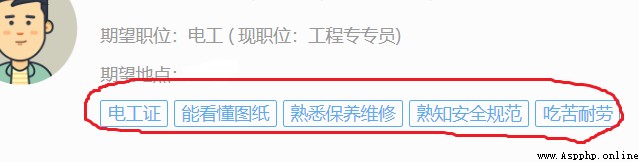
也就是所謂的多標簽,我們再來看看它對應的HTML結構,打開F12(如果你按了F12什麼也沒發生,可以去看看博主第一篇文章)
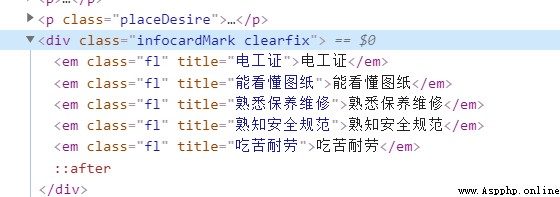
可以發現,這些信息都是嵌套於某一HTML下的,圖中信息是位於 <div class = "infocardMark clearfix"></div>標簽中,那麼我們怎麼去獲取這些信息呢,這時我們可以在獲取數據的時候只分析到 div.infocardMark.clearfix 這一層(用浏覽器的 Copy selector方法可以獲取),對了這裡說一下,博主用的是Google浏覽器,當然,你們也可以使用火狐浏覽器什麼的,都有對應的F12界面,然後使用stripped_strings方法,其說明是這樣的:
stripped_strings:用來獲取目標路徑下所有的子孫非標簽字符串,會自動去掉空白字符串,返回的是一個生成器
然後針對該案例具體的使用可以是這樣的:
date = soup.select('div.infocardMark.clearfix')
for info in zip(date):
print(list(info.stripped_strings))
如果遇到:AttributeError: 'tuple' object has no attribute 'stripped_strings',需要先分析元組的結構,然後取到具體的元素上在使用
stripped_strings方法,比如上述代碼中發生所說的錯誤就可以嘗試用list(info[0].stripped_strings)來一試,當然這是在分析了錯誤和數據的基礎上進行的代碼修改。
那麼第二個要說的問題是,有時候我們會因為種種原因,比如:網頁的數據是通過js控制傳遞的,那麼這個時候要去分析js是相對麻煩的,那麼我們就可以嘗試下谷歌浏覽器的黑科技(p≧w≦q),在F12之後我們可以模擬手機的方式進行網頁查看,因為適配的原因,有時候采取手機頁面的方式進行信息獲取是一種相對簡單的方法,具體怎麼做呢?這裡首先要簡單講一下,發起請求的一些東西(其實博主也不是很懂,但會粗暴的講一下),在我們發起服務請求的時候處理URL之外,其實還應該在加上一些報文頭(請求頭)的信息,可是我們之前都沒加上報文頭都能正常訪問網絡啊,具體的你們可以自己下去查一下資料,這裡簡單說一下報文頭應該如何去查看,並且應該怎麼用。首先,肯定得F12了:然後切換到Network,選擇XHR,選擇第一個請求項,點擊Headers,然後傳送信息的報文頭就在request Headers中,額...好吧就是下面這些東西:

那麼知道了這些信息有什麼用呢,嘿嘿,兩個方面,比如說你的登錄信息就可以靠這裡Request Headers中的信息進行獲取,然後放到鏈接中,這樣你的請求就是具有身份信息的,嗯....怎麼說呢,就是說我們之前的請求都只是以游客的形式進行的,那如果我們想以自己已經登錄的狀態去發起請求的話,就可以從Request Headers中去找尋蛛絲馬跡,好吧,如果其實重要的是Headers中的Cookie(具體資料下去查詢),它就是記錄我們身份的對象..........好了,多的不說還是說會正題吧,我們該怎麼去模仿手機登錄呢,這時候我就需要去點擊那個手機的圖標,也就是這個:
點擊完畢,就可以切換不同的手機型號進行訪問了,是不是很興奮(p≧w≦q)(好吧其實並不興奮.....):
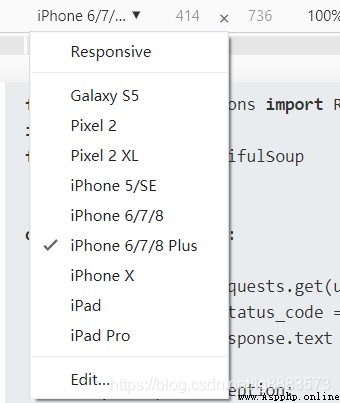
有了這些准備,這時候我們再去F12中重新查看request headers中的信息,
User-Agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36
User-Agent:
Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1
第一條是正常用Windows訪問時的信息,第二條是模擬Iphone訪問時的信息,可以放心發生了改變,有了這些信息我們就可以如下去訪問網址:
在進行request請求前我們先定義header,然後在請求時指定headers即可:
header = {
'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'
}
wb_data = requests.get(url,headers = header )
如果需要加入登錄信息,需要先進行一次登錄,然後在去查看Headers中的Cookie,在header中指定Cookie對應的信息即可。






