這一篇我們來學習如何對多頁的網絡進行信息爬取。在平時網頁浏覽時不少看見許多網頁是有多頁的,像這樣:
竟然,上一篇我們學會了單頁網絡信息的爬取,那麼對於多頁網絡........這當然也不是問題(罒ω罒)。
首先第一步還是得學會分析,怎麼分析,首先我們需要分析網頁換頁發生了說明改變,這裡主要從URL和請求信息兩個方面進行研究,我們仍以上一篇文章中的網站作為示例:
當我們不斷換頁時,我們會發現什麼呢?沒錯,“看破真相的是一個外表看似小孩,智慧卻過於常人的.........”:

https://cn.tripadvisor.com/Attraction_Products-g60763-a_sort.-d1687489-The_National_9_11_Memorial_Museum-New_York_City_New_York.html?o=a60#ATTRACTION_LIST(第三頁)
https://cn.tripadvisor.com/Attraction_Products-g60763-a_sort.-d1687489-The_National_9_11_Memorial_Museum-New_York_City_New_York.html?o=a90#ATTRACTION_LIST(第四頁)
https://cn.tripadvisor.com/Attraction_Products-g60763-a_sort.-d1687489-The_National_9_11_Memorial_Museum-New_York_City_New_York.html?o=a120#ATTRACTION_LIST (第五頁)
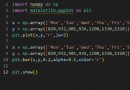
可以發現“?”後面的“o=a{}”發生了改變,且該改變是有跡可循的每一次a後的值都會有規律的增加,那麼抓住這個特征我們就可以開始構建爬蟲了(*^▽^*),我們以上一篇的程序為基礎,將它封裝成函數,然後在進行循環調用。
def get_info(url,data = None):
wb_data = requests.get(url)#網址請求,返回response
#解析網頁
#.text將網頁資料變得可讀
soup = BeautifulSoup(wb_data.text,'lxml')
titles = soup.select('div.listing_title > a')
images = soup.select('div.photo_booking > a > span > img')
description = soup.select('div.listing_description > span')
duration = soup.select('div.product_duration')
price = soup.select('div.product_price_info > div.price_test > div.from > span')for title,image,des,time,money in zip(titles,images,description,duration,price):
data = {
'title' : title.get_text(),
'image' : image.get('src'),
'description' : des.get_text(),
'duration' : time.get_text(),
'price' : money.get_text()
}
print(data)for i in range(30,150,30):
url = 'https://cn.tripadvisor.com/Attraction_Products-g60763-a_sort.-d1687489-The_National_9_11_Memorial_Museum-New_York_City_New_York.html?o=a{}#ATTRACTION_LIST'.format(str(i))
get_info(url)