This article will record bloggers' sharing of learning crawlers , Reptile learning needs python3.+ 、 BeautifulSoup、lxml、requests
stay python Under the environment, you can install the relevant environment through the following commands :
pip install BeautifulSoup4
pip install lxml
pip install requests
After installation, you can start the learning road , This article takes https://cn.tripadvisor.com/Attraction_Products-g60763-a_sort.-d1687489-The_National_9_11_Memorial_Museum-New_York_City_New_York.html?o=a30#ATTRACTION_LIST Take the website as an example for simple crawler learning ;
Before learning crawler, you need to know some knowledge about website response , Study by yourself (#^.^#), Then I need to be able to use F12, Can be used for browsers F12, what , You say press F12 Nothing happened , Then click the website with the mouse to restart F12, what , You said you pressed F12 As a result, the screen is even more dazzling (*.*), Then you should use a notebook , Please press Fn+F12, And then it should be , Probably , Probably ...... The interface will appear :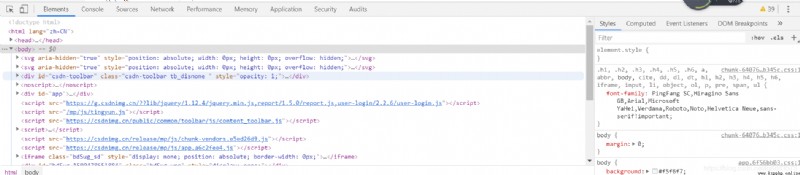
Congratulations , You have learned to view the page elements of the current web page (p≧w≦q), Okay , As for what these elements mean, please study by yourself HTML,CSS.
Return theme , With the above preparations, we can start crawling , The URL of this article is given above , First of all, we need to clarify our target , That is, what information needs to be captured ( Clear objectives ), Open the above website , This article takes title , Introduce , Price , Take playing time as an example to explain :
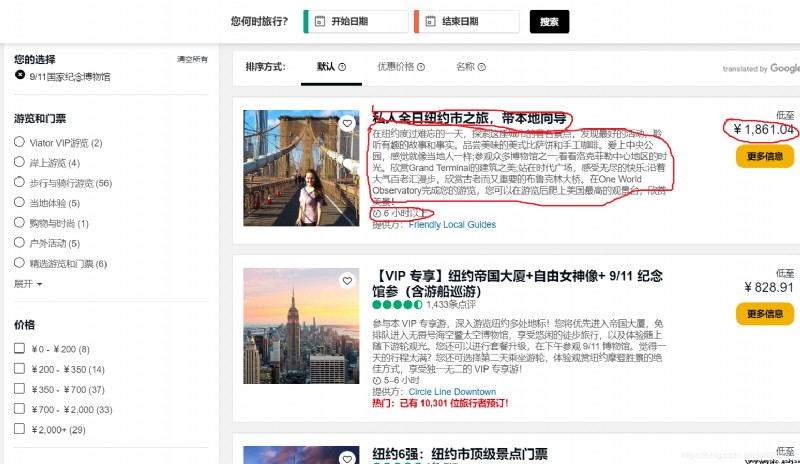 ok , Forgive me for being lazy , The mark is a little anti human , Make do with it , Founder is going to grab the information marked on it , So first of all, we need to pass F12 Meet and locate these information in those HTML Under the label , By checking page elements , Determine the label location of each message as follows :
ok , Forgive me for being lazy , The mark is a little anti human , Make do with it , Founder is going to grab the information marked on it , So first of all, we need to pass F12 Meet and locate these information in those HTML Under the label , By checking page elements , Determine the label location of each message as follows :
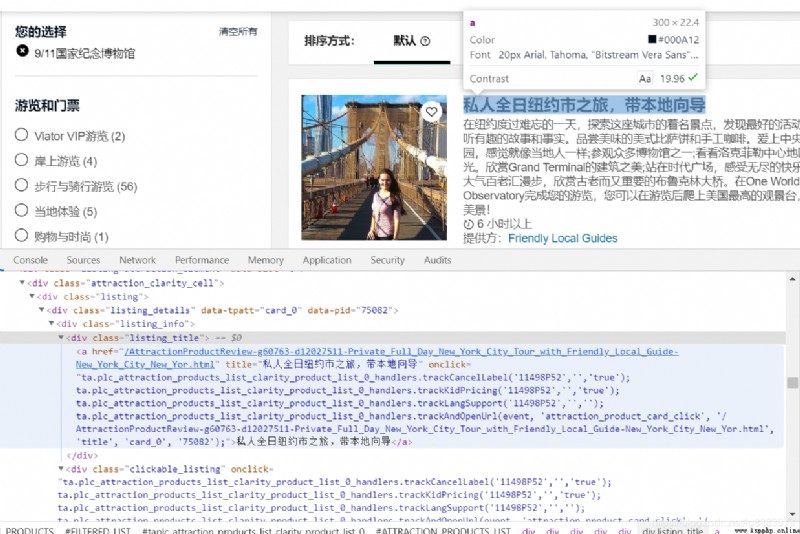
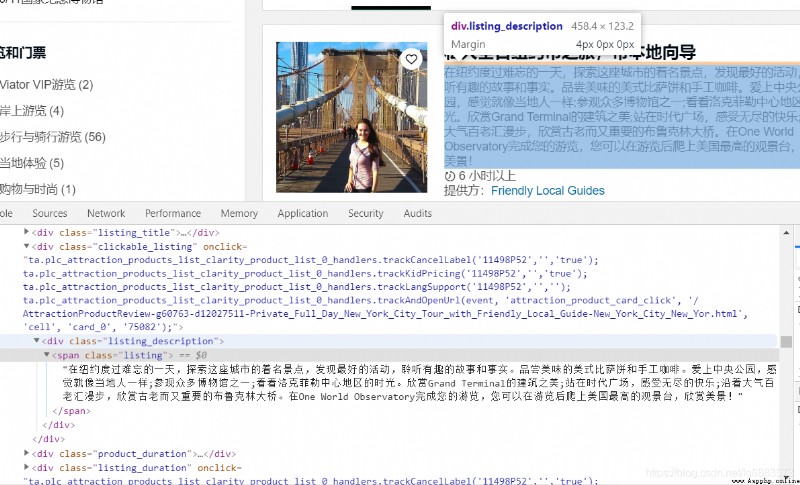
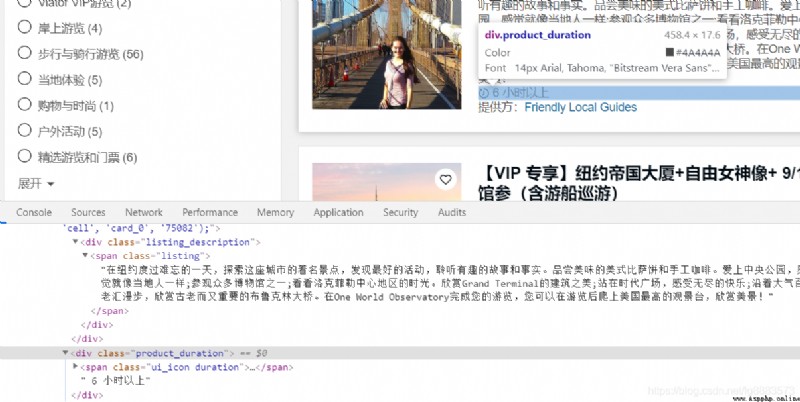

Analysis found , The distribution of the four elements is as follows : The title is at :class by listing_title Of <div> Label under <a> Under the label ; Introductory information is located at class by listing_description Of <div> Label under <span> Under the label ; The price is at class by price_test Of <div> Label under class by from Of <div> Label under <span> Under the label ; The travel time is located in :class by product_duration Of <div> Under the label ;
Well, it seems a little dizzy to read the expression , The main thing is that we need to find out where the information is , In fact! , Of course, there are simple ways to mark these positions [○・`Д´・ ○]( There are simple things to say ), The method is as follows :
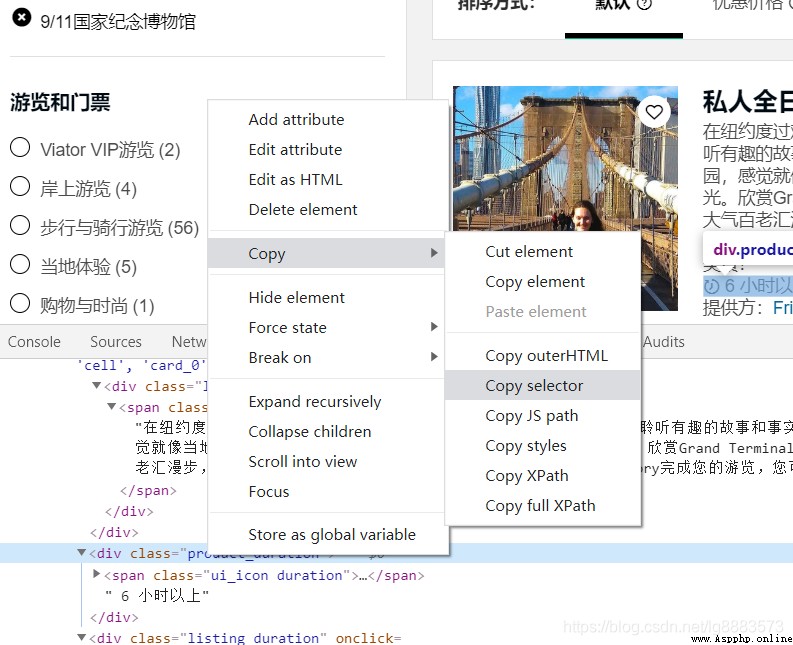
selector The path structure of the current tag will be copied , It can be used for waiting BeautifulSoup analysis .
Okay , Through a meal , We can finally get down to business and start writing about our reptiles (p≧w≦q):
from bs4 import BeautifulSoup
import requests
url = 'https://cn.tripadvisor.com/Attraction_Products-g60763-a_sort.-d1687489-The_National_9_11_Memorial_Museum-New_York_City_New_York.html?o=a30#ATTRACTION_LIST'
# Request the URL and accept the returned information
wb_data = requests.get(url)
# adopt .text Method , Parse the URL information into readable text , And formulate ‘lxml’ For the parser
soup = BeautifulSoup(wb_data.text,'lxml')
# Specify the path where the title information is located
titles = soup.select('div.listing_title > a')
# Specify the path where the introduction information is located
introduction = soup.select('div.clickable_listing > div > span')
# Specify the path where the price information is located
prices = soup.select('div.product_price_info > div.price_test > div > span')
# Specify the path where the travel time information is located
duration = soup.select('div.listing_info > div.product_duration')for title,description,spend,time in zip(titles,introduction,prices,duration):
# Parsing information :.get_text() Method is used to get the text content under the current tag
data = {
'title' :title.get_text(),
'introduction' : description.get_text(),
'prices' : spend.get_text(),
'duration' : time.get_text()
}
print(data)
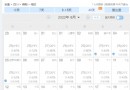
The operation results are as follows :
 Python automation series: using Python docx to manipulate word documents
Python automation series: using Python docx to manipulate word documents
It is often used in daily offi
 Relationships and functions of coroutines, tasks, and future waiting objects in Python asyncio
Relationships and functions of coroutines, tasks, and future waiting objects in Python asyncio
Catalog Preface 1.Asyncio Ent