Use python Multiple processes process a data set , The processing function is Add noise to each picture and save
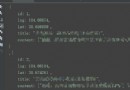
img_paths = get_file_path(path1, path2) print("all:", len(img_paths)) # 1.pool.map avi_cpu = os.cpu_count()-30 print('there is {} cpu'.format(avi_cpu)) pool = Pool(avi_cpu) # Currently available cpu Number # pool.map_async(process_image, img_paths) res = [] for img in img_paths: r = [pool.apply_async(process_image, (img,))] res.append(r) #2. In this case, the sub process processing the picture will directly skip # pool = Pool(100) # cpus = os.cpu_count() # print('there is {} cpu'.format(cpus)) # Task segmentation # splits = list(divide(cpus, img_paths)) # for split in splits: # pool.apply_async(process_image, args=(split,)) pool.close() pool.join() end = time.time() print("deal data cost:", end - start)Under normal circumstances, a process can process an image within a few hundred seconds , But use the above 1 The code is at the end of processing , The last few processes will become very slow , The time of a single process can reach thousands or even tens of thousands of seconds . The funny thing is , When I used the same code to process another data set, it was completely normal , The number of pictures in the two data sets is different , There are also differences in image size
pool.map
pool.map_async
pool.apply_async
also chunksize Set up , I tried to set it as Total number of files /cpu Count , The effect becomes slower at the beginning
In the use of 2 Code , Only the main process will run , Skip handler
Process data sets normally , Will not stop in the last few processes