使用python多進程處理一個數據集,處理函數是 對每張圖片進行加噪並保存
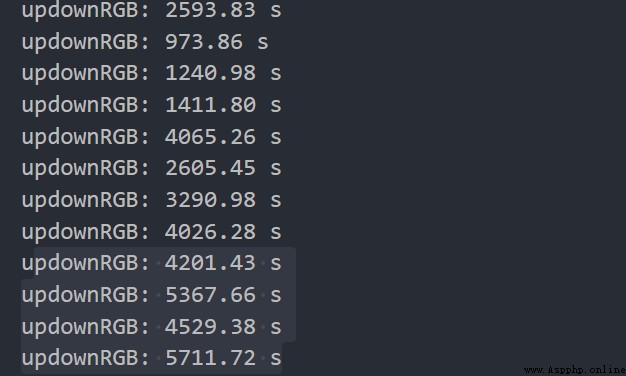
img_paths = get_file_path(path1, path2) print("all:", len(img_paths)) # 1.pool.map avi_cpu = os.cpu_count()-30 print('there is {} cpu'.format(avi_cpu)) pool = Pool(avi_cpu) # 當前可用cpu數量 # pool.map_async(process_image, img_paths) res = [] for img in img_paths: r = [pool.apply_async(process_image, (img,))] res.append(r) #2.該情況處理時處理圖片的子進程會直接跳過 # pool = Pool(100) # cpus = os.cpu_count() # print('there is {} cpu'.format(cpus)) # 任務切分 # splits = list(divide(cpus, img_paths)) # for split in splits: # pool.apply_async(process_image, args=(split,)) pool.close() pool.join() end = time.time() print("deal data cost:", end - start)正常情況下一個進程處理一張圖片在幾百秒以內,但使用上述1代碼時在處理快結束的時候,最後幾個處理進程會變得很慢,單個進程的用時會達到幾千甚至上萬秒。搞笑的是,我之前用同樣的代碼處理另一個數據集的時候完全正常,兩個數據集的圖片數不同,圖片大小也存在差異
pool.map
pool.map_async
pool.apply_async
還有chunksize的設置,我試過設為 文件總數/cpu數,開始效果就變的更慢一些
在使用2代碼時,只會有主進程運行,跳過處理函數
正常處理數據集,不會在最後幾個進程停頓住