Don't talk much , Let's see the result first , Satisfied again give the thumbs-up + Focus on + Collection !
This is the user comment of crawling Wuhan Mulan grassland
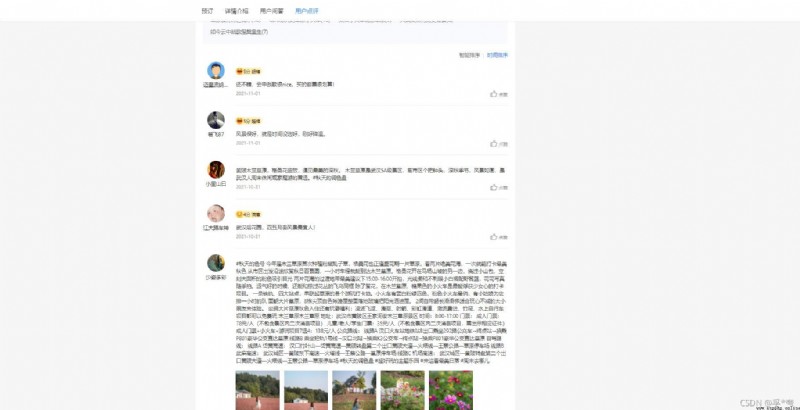
Ctrip Mulan grassland page website
https://you.ctrip.com/sight/wuhan145/50956.html
Crawling
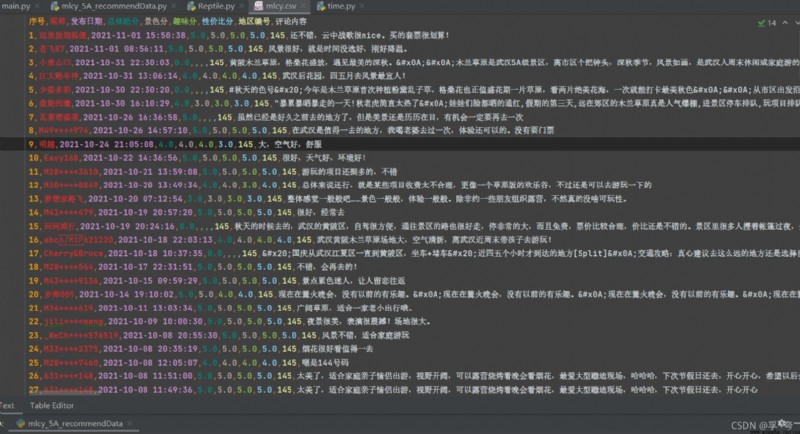
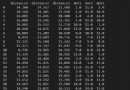
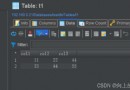
Crawl and save as .CSV file
// An highlighted block
import csv
import json
import time
import requests
class Reptile: # Create a crawler class , It is convenient to call in other files
def __init__(self, postURL, user_agent, poiId, cid, startPageIndex, endPageIndex, file):
self.postURL = postURL
self.user_agent = user_agent
self.poiId = poiId
self.cid = cid
# The above corresponds to the header information in the package
self.startPageIndex = startPageIndex # Start crawling page
self.endPageIndex = endPageIndex # End the page number crawled
self.file = file # Record keeping .csv File name of the file , Be sure to include the suffix , Such as :"****.csv"
self.dataListCSV = [] # Used to temporarily store crawl results , It's a two-dimensional list ,dataListCSV Each element in corresponds to a record , Easy to write CSV file
def get(self):
for i in range(int(self.startPageIndex), int(self.endPageIndex)+1): # Crawling i page
requestParameter = {
'arg': {
'channelType': '2',
'collapseType': '0',
'commentTagId': '0',
'pageIndex': str(i), # Page index of crawled comment page
'pageSize': '10', # Number of comments per page
'poiId': str(self.poiId), # Scenic spot address code
'sortType': '1',
'sourceType': '1',
'starType': '0'},
'head': {
'auth': "",
'cid': self.cid, # Different scenic spots cid Different , Therefore, you need to set it yourself
'ctok': "",
'cver': "1.0",
'extension': [],
'lang': "01",
'sid': "8888",
'syscode': "09",
'xsid': ""}
}
html = requests.post(self.postURL, data=json.dumps(requestParameter)).text
html = json.loads(html) # Get the first i All comment data in the form of a page dictionary
for element in html["result"]["items"]: # Deal with the scenery 、 Interest 、 Cost performance score
if element['scores']:
if element['scores'][0]:
sceneryScore = str(element['scores'][0]["score"])
else:
sceneryScore = ""
if element['scores'][1]:
interestScore = str(element['scores'][2]["score"])
else:
interestScore = ""
if element['scores'][3]:
costScore = str(element['scores'][4]["score"])
else:
costScore = ""
else:
sceneryScore = ""
interestScore = ""
costScore = ""
# Format of processing comment time
publishTime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(int(element["publishTime"][6:16])))
self.dataListCSV.append([len(self.dataListCSV)+1, element["userInfo"]["userNick"], publishTime, element["score"], sceneryScore, interestScore, costScore, element["districtId"], element["content"]])
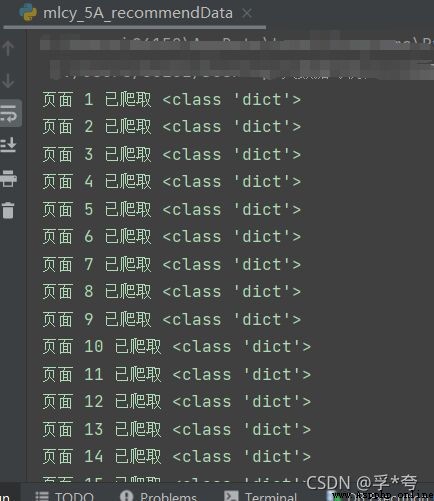
print(f" page {i} Crawled ", type(html))
time.sleep(4)
print(self.dataListCSV)
with open(self.file, "w+", encoding="utf8", newline="") as f: # take dataListCSV Write the contents of the list .csv In file
write = csv.writer(f)
write.writerow([" Serial number "," nickname ", " Release date ", " Overall score ", " The scenery is divided ", " Interesting points ", " Cost performance points ", " Area number ", " Comment content "])
write.writerows(self.dataListCSV)
// An highlighted block
# my Reptile Class is placed in dataProcurement Under bag
from dataProcurement.Reptile import Reptile
postURL = "https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList?_fxpcqlniredt=09031083119044546256"
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.30"
poiId = 83520
cid = "09031083119044546256"
startPageIndex = 1
endPageIndex = 20
reptile = Reptile(postURL, user_agent, poiId, cid, startPageIndex, endPageIndex, "mlcy.csv")
reptile.get()
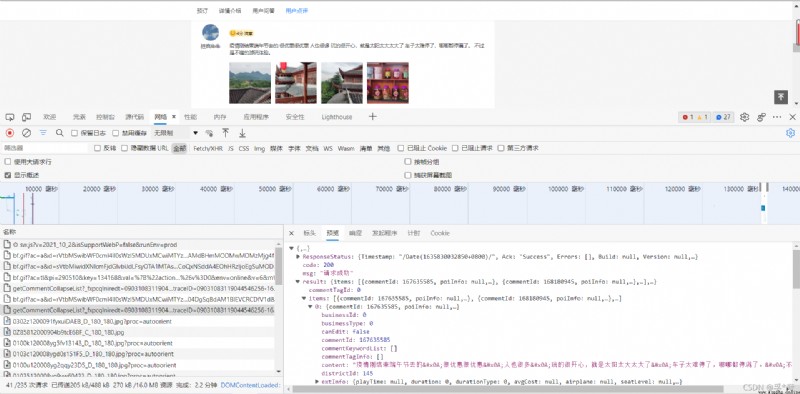
find networks( The Internet ) Medium getCommentCollapseList package ,postURL See the request in the header URL, writes https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList?_fxpcqlniredt=09031083119044546256
that will do , Don't write it all .
poiId and cid See the request load section ,
user_agent There is no need to say more , Friends who can find this article should understand .