Now I will introduce you to use Scrapy Crawler acquisition NetEase cloud music Popular song list information for .
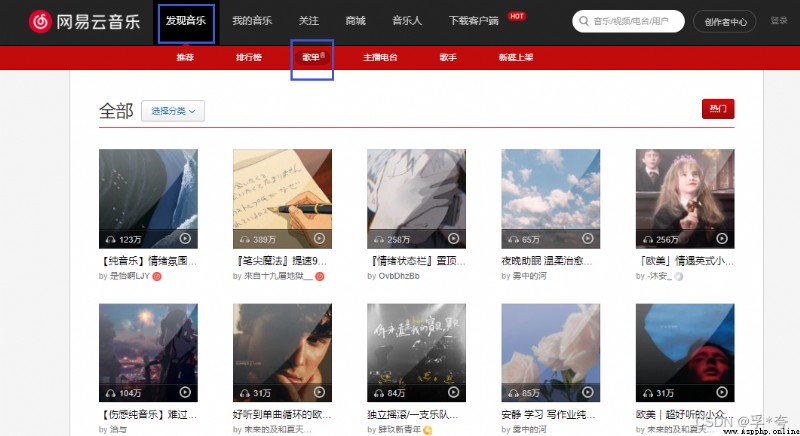
Here is the song list page of Netease cloud music , You can see that the song list information is very structured , It is very suitable for reptiles to crawl .
URL: All song lists - song sheet - NetEase cloud music (163.com)
Crawl result preview ( Crawling time is about a week earlier than writing this article , So the information part of the song list has changed ):

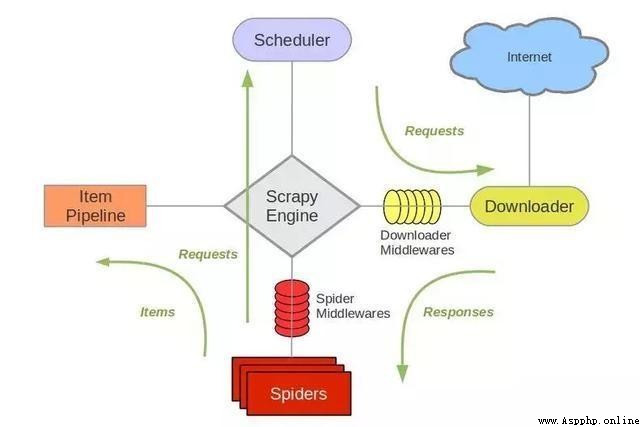
Scrapy The frame is mainly composed of five components , They are the scheduler (Scheduler)、 Downloader (Downloader)、 Reptiles (Spider) And physical pipes (Item Pipeline)、Scrapy engine (Scrapy Engine). Let's introduce the functions of each component .
(1)、 Scheduler (Scheduler):
Scheduler , To put it bluntly, assume it's a URL( Grab the web address or link ) Priority queue for , It decides that the next URL to grab is what , Remove duplicate URLs at the same time ( Don't do useless work ). Users can customize the scheduler according to their own requirements .
(2)、 Downloader (Downloader):
Downloader , It's the most burdensome of all the components , It's used to download resources on the Internet at high speed .Scrapy The downloader code is not too complicated , But it's efficient , The main reason is Scrapy The Downloader is built on twisted On this efficient asynchronous model ( In fact, the whole framework is based on this model ).
(3)、 Reptiles (Spider):
Reptiles , Is the most concerned part of the user . Users customize their own crawler ( By customizing syntax such as regular expressions ), Used to extract the information you need from a specific web page , The so-called entity (Item). Users can also extract links from it , Give Way Scrapy Continue to grab next page .
(4)、 Physical pipeline (Item Pipeline):
Physical pipeline , Used to deal with reptiles (spider) Extracted entities . The main function is to persist entities 、 Verify the validity of the entity 、 Clear unwanted information .
(5)、Scrapy engine (Scrapy Engine):
Scrapy The engine is at the heart of the whole framework . It's used to control the debugger 、 Downloader 、 Reptiles . actually , The engine is the equivalent of a computer CPU, It controls the whole process .
a key : One Scrapy The file directory structure of the project is as follows :
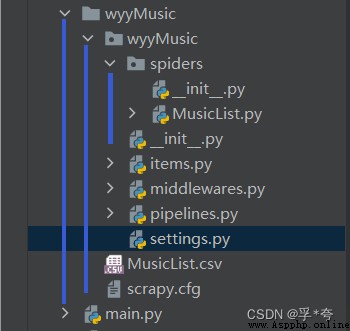
We usually need to edit only spiders 、items.py、 pipeline.py、settings.py
Create a new project folder on the desktop , And then use pycharm open , At terminal (Terminal) Input in :
scrapy startproject Crawler project name # Create a Scrapy Reptile project
cd my Crawler project name # Enter this project
As this article is :
scrapy startproject wyyMusic
cd wyyMusic
Such a Netease cloud music crawler project is created .
1. Set up settings.py
stay settings.py Write the code in :( It is used to set some global configuration information of the crawler )
# Remove other descriptive information from the log , Only output the information we need
LOG_LEVEL = "WARNING"
USER_AGENT = ' Own browser user agent'
# The default is True, Change to False, That is, not observing the gentleman's agreement
ROBOTSTXT_OBEY = False
# Download delay , It can be set to pause every download 2 second , In case the download is too fast and access is forbidden
DOWNLOAD_DELAY = 2
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en', # Don't use this code
}
2. Set up items.py:( Define the fields that need to be crawled )
import scrapy
class MusicListItem(scrapy.Item):
SongsListID = scrapy.Field() # song sheet id Number
SongListName = scrapy.Field() # Song single name
AmountOfPlay = scrapy.Field() # Play volume
Labels = scrapy.Field() # Tag name
Url = scrapy.Field() # Song list domain name , Reserve a backup for the next detailed crawl
Collection = scrapy.Field() # The amount of songs collected
Forwarding = scrapy.Field() # Forwarding volume
Comment = scrapy.Field() # Comment quantity
NumberOfSongs = scrapy.Field() # Number of songs
CreationDate = scrapy.Field() # Song list creation date
AuthorID = scrapy.Field() # author id3. Create song list crawler MusicList.py:
stay spiders Create a new one under the package MusicList.py, The directory structure after creation is as follows
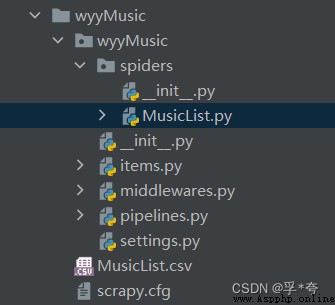
stay MusicList.py Get song list information in
import scrapy # Import scrapy package
# Use relative paths from what we just wrote items.py Import MusicListItem class
from ..items import MusicListItem
# Import deep copy package , Used to save to when crawling multiple pages pipeline The order of song list information in will not be disordered , Prevent repetition , It's critical
from copy import deepcopy
class MusicListSpider(scrapy.Spider):
name = "MusicList" # Must write name attribute , stay pipeline.py Will be used in
allowed_domains = ["music.163.com"] # Set the crawling range of the crawler
start_urls = ["https://music.163.com/discover/playlist"] # Start crawling page , That is, the first side of the song list
offset = 0 # A pointer set by yourself , Used to record the currently crawled page number
def parse(self, response):
# Use .xpath Grammar comes from HTML The information needed for parsing in the page
# Get all the song lists in one page , Save to liList in
liList = response.xpath("//div[@id='m-disc-pl-c']/div/ul[@id='m-pl-container']/li")
# Yes liList Song list in , One by one , Get the information of the detailed page of the song list
for li in liList:
itemML = MusicListItem()
a_href = li.xpath("./div/a[@class = 'msk']/@href").extract_first()
itemML["SongsListID"]= a_href[13:]
# Get the detailed page of the song list Url Address
Url = "https://music.163.com" + a_href
itemML["Url"] = Url
# call SongsListPageParse To get the information of the detailed page of the song list
yield scrapy.Request(Url, callback=self.SongsListPageParse, meta={"itemML" : deepcopy(itemML)})
# Climb to the next page
if self.offset < 37:
self.offset += 1
# Get... On the next page Url Address
nextpage_a_url="https://music.163.com/discover/playlist/?order=hot&cat=%E5%85%A8%E9%83%A8&limit=35&offset=" + str(self.offset*35)
print(self.offset ,nextpage_a_url)
yield scrapy.Request(nextpage_a_url, callback=self.parse)
print(" Start climbing to the next page ")
# Used to crawl the detailed page information in each song list
def SongsListPageParse(self, response):
cntc = response.xpath("//div[@class='cntc']")
itemML = response.meta["itemML"]
SongListName = cntc.xpath("./div[@class='hd f-cb']/div/h2//text()").extract_first()
itemML["SongListName"] = SongListName # Get the song title
user_url = cntc.xpath("./div[@class='user f-cb']/span[@class='name']/a/@href").extract_first()
user_id = user_url[14:]
itemML["AuthorID"] = user_id # Get the song list creator id Number
time = cntc.xpath("./div[@class='user f-cb']/span[@class='time s-fc4']/text()").extract_first()
itemML["CreationDate"] = time[0:10] # Get the song list creation date
aList = cntc.xpath("./div[@id='content-operation']/a")
Collection = aList[2].xpath("./@data-count").extract_first()
itemML["Collection"] = Collection # Get collection
Forwarding = aList[3].xpath("./@data-count").extract_first()
itemML["Forwarding"] = Forwarding # Get forwarding volume
Comment = aList[5].xpath("./i/span[@id='cnt_comment_count']/text()").extract_first()
itemML["Comment"] = Comment # Get the number of comments
tags = ""
tagList = cntc.xpath("./div[@class='tags f-cb']/a")
for a in tagList:
tags = tags + a.xpath("./i/text()").extract_first() + " "
itemML["Labels"] = tags
songtbList = response.xpath("//div[@class='n-songtb']/div")
NumberOfSongs = songtbList[0].xpath("./span[@class='sub s-fc3']/span[@id='playlist-track-count']/text()").extract_first()
itemML["NumberOfSongs"] = NumberOfSongs
AmountOfPlay = songtbList[0].xpath("./div[@class='more s-fc3']/strong[@id='play-count']/text()").extract_first()
itemML["AmountOfPlay"] = AmountOfPlay
yield itemML # Pass the crawled information to pipelines.py
Every song list on every page , They all correspond to one li label ,li In the tag a The tag is the address of the detailed page of the song list
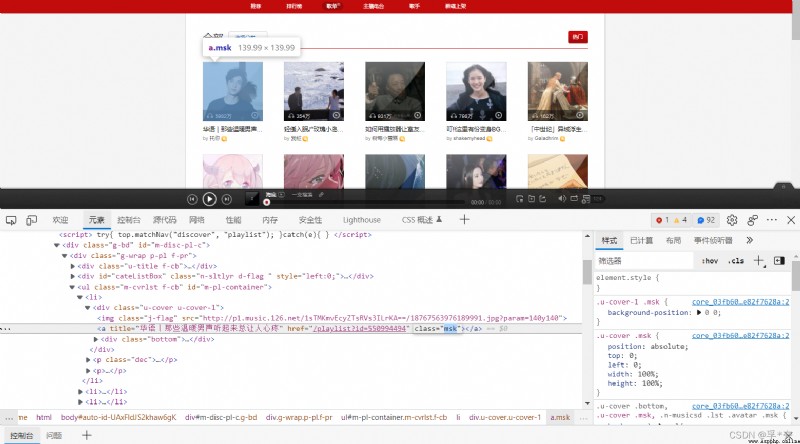
Go to the detailed information page of a song list :
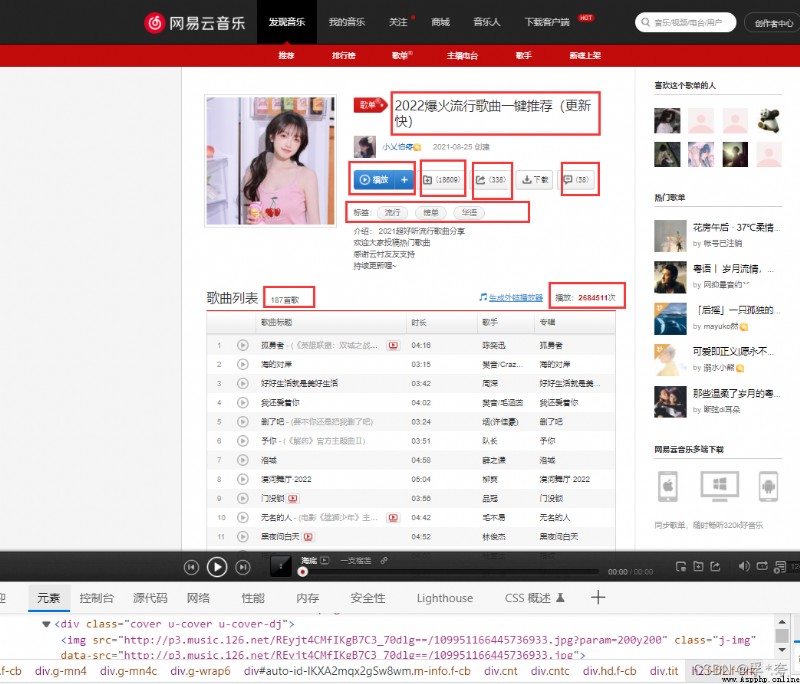
The information we crawl is where the red box is drawn in the above figure , Their corresponding fields are named :
SongsListID = scrapy.Field() # song sheet id Number SongListName = scrapy.Field() # Song single name AmountOfPlay = scrapy.Field() # Play volume Labels = scrapy.Field() # Tag name Url = scrapy.Field() # Song list domain name , Reserve a backup for the next detailed crawl Collection = scrapy.Field() # The amount of songs collected Forwarding = scrapy.Field() # Forwarding volume Comment = scrapy.Field() # Comment quantity NumberOfSongs = scrapy.Field() # Number of songs CreationDate = scrapy.Field() # Song list creation date AuthorID = scrapy.Field() # author id
They are all in SongsListPageParse Function , Get by parsing the detailed information page of the song list .
Climb to the next page :
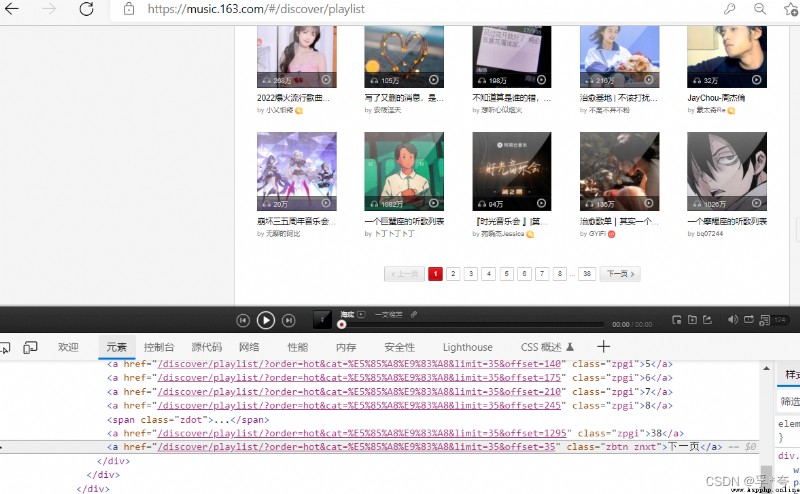
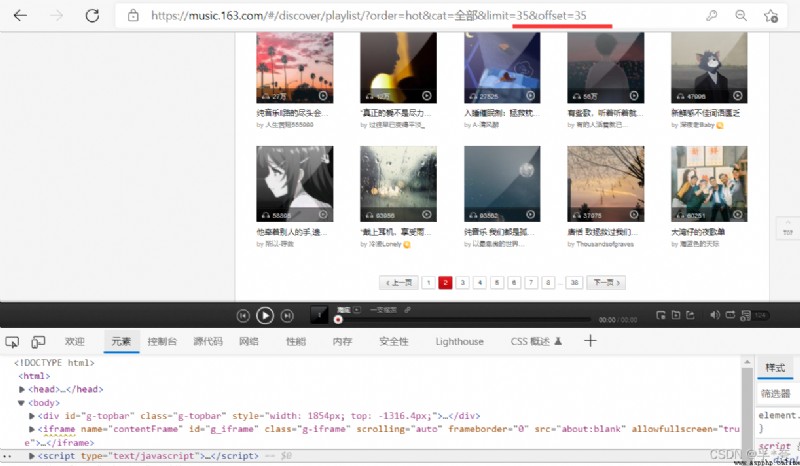
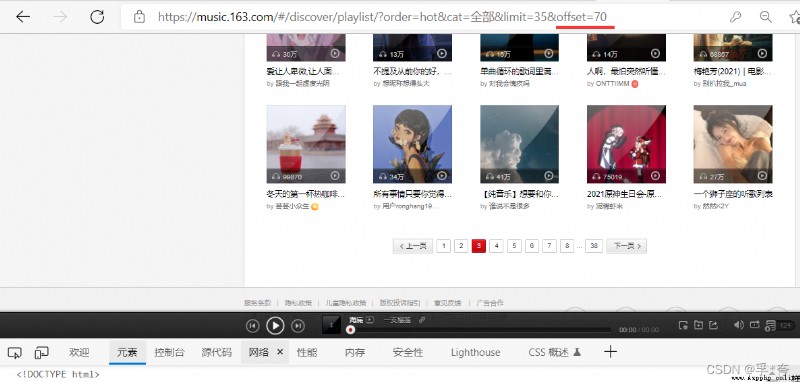
There are two ways to get the next page :
One is from Per page “ The next page ” a Tab for the next page url Address
Two is According to the law of turning pages , Per page url Medium offset Parameter difference 35( That is, each page has 35 A song list ), So just order offset+= 35 You can crawl to the next page by cycling , until offset <= 35 * 37 until ,37 Yes, there is 37 page .
In fact, every time , So it's useless to crawl to the next page for , And just use if To judge offset
yield scrapy.Request(nextpage_a_url, callback=self.parse)
It's actually a recursion , call parse Function itself .
Because the second method is simpler , So the second method used here is to crawl to the next page
4. Set up pipelines.py To save the obtained information ( namely item)
from scrapy.exporters import CsvItemExporter
class WyymusicPipeline:
def __init__(self):
self.MusicListFile = open("MusicList.csv", "wb+") # Save as csv Format
self.MusicListExporter = CsvItemExporter(self.MusicListFile, encoding='utf8')
self.MusicListExporter.start_exporting()
def process_item(self, item, spider):
if spider.name == 'MusicList':
self.MusicListExporter.export_item(item)
return item5. Finally came the exciting moment !—— Start the crawler
At terminal (Terminal) Input in :
scrapy crawl MusicList
( Be careful : Before that, make sure you are wyyMusic Crawler directory , If not , You can use the cd wyyMusic To enter the crawler directory .)
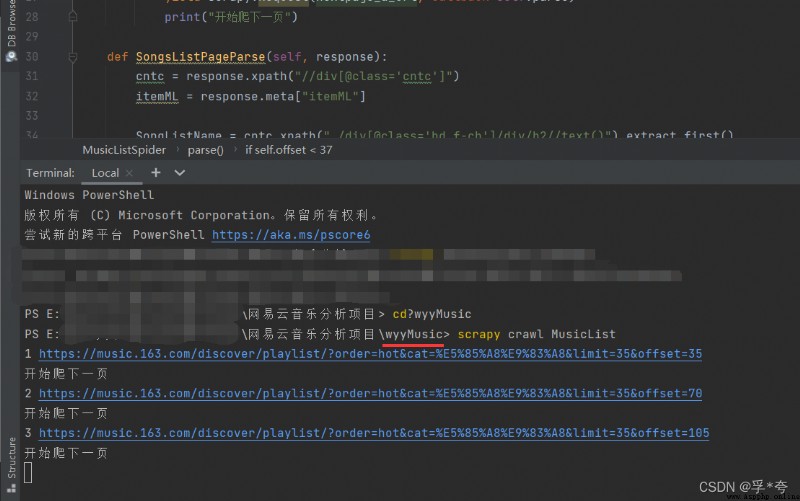
Already starting to crawl ! It will automatically be in wyyMusic Generate under package MusicList.csv file , What is stored in it is all the popular song list information crawled and sorted .
Finally climbed to 1288 A song list , The effect is as follows :

Last :
The information of some pages in Netease cloud music cannot be used Scrapy To crawl , The content crawled is empty . You need to use python Selenium Reptiles come and crawl , The next article will teach kids to use Selenium Crawler to crawl Netease cloud music user page details , Such as user nickname 、 Gender 、vip Grade 、 home 、 brief introduction 、 Collect and create song list songs 、 Fans and other information .
Look forward to the little partner may wish to pay more attention 、 Point a praise , It's not easy to create