《Python Quick start ( The first 3 edition )》 Naomi · Sead
4.3 Variables and assignments
Python The variable in is not a container , It's pointing to Python The label of the object , Object is in the namespace of the interpreter . Any number of labels ( Or variable ) Can point to the same object . When objects change , The values of all variables pointing to it will change .
The new assignment operation will overwrite all previous assignments ,del Statement will delete the variable . If you try to output the contents of a variable after deleting it , It will lead to mistakes , The effect is as if the variable had never been created :
>>> x = 5
>>> print(x)
5
>>> del x
>>> print(x)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'x' is not defined
>>>
4.7 None value
testing None Whether there exists is very simple , Because in the whole Python There's only... In the system 1 individual None Example , All right None All references point to the same object ,None Only equivalent to itself .
4.8 Get user input
utilize input() Function can get the user's input .input() Function can take a string argument , As a prompt message displayed to the user .
User input is obtained as a string , So if you want to use it as a number , Must use int() or float() Function transformation .
4.10 Basic Python Encoding style
A.3.2 Code layout
1. Indent
Each level of indentation adopts 4 A space
3. The biggest President
All lines should be limited to 79 Within characters .
For continuous large paragraphs ( Document string or comment ), It is suggested to limit the president to 72 Within characters .
The preferred solution for line breaking in long lines , It's using Python Implicit row join feature , In parentheses 、 Break lines inside square brackets and braces . If necessary, you can add a pair of parentheses outside the expression , But sometimes it's better to use a backslash . Make sure to indent the following lines appropriately . The preferred position for breaking binary operators is after the operator .
4. Blank line
Between top-level functions and class definitions , Please separate with two blank lines .
Between the method definitions inside the class , Please use 1 Separate by blank lines .
5.
Import statements should usually be on separate lines , for example
import os
import sysBut there is no problem with the following writing :
from subprocess import Popen, PIPE Import statements should be grouped in the following order .
(1) Import of standard library .
(2) Import of related third-party libraries .
(3) Local application / library —— Import of specific libraries .
Please add 1 Empty rows .
Any corresponding __all__ Declarations should be after the import statement .
Using relative Import syntax for importing internal packages is highly deprecated . Always use absolute package paths for all imports .
6. Whitespace in expressions and statements
Redundant white space characters should be avoided in the following situations .
Close to parentheses 、 Inside brackets or braces .
Next to the comma 、 Before semicolon or colon .
7. Other suggestions
Always place on both sides of the following binary operators 1 A space : assignment (=)、 Incremental assignment (+=,-= etc. )、 Compare (==、<、>、!=、<>、<=、>=、in、not、in、is、is not)、 Boolean (and、or、not).>> Place spaces on both sides of mathematical operators .
i = i + 1
submitted += 1
x = x * 2-1
hypot2 = x * x + y * y
c = (a + b) * (a - b)When used to specify keyword parameters or default parameter values , Do not stay = Use spaces on both sides .
def complex(real, imag=0.0):
return magic(r=real, i=imag)
Compound statements are generally discouraged , That is, put multiple statements on the same line .
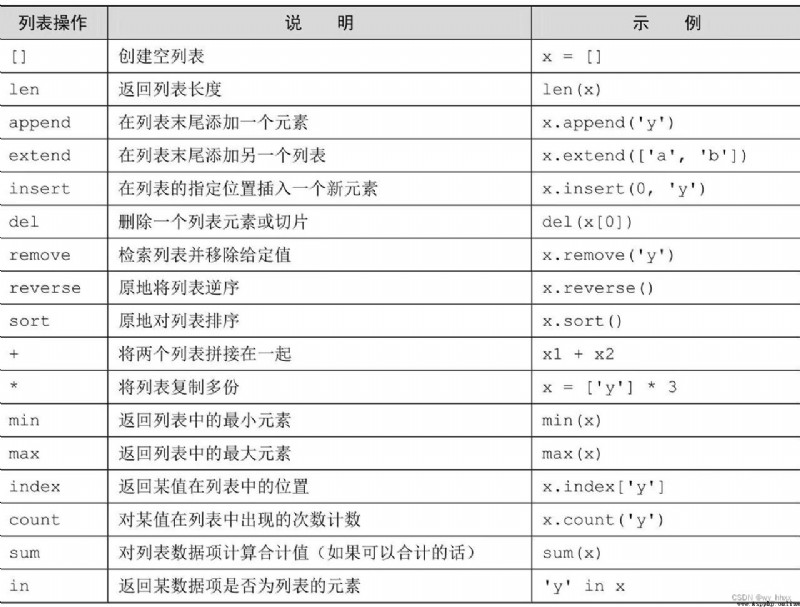
5.2 Indexing mechanism of list
If the second index gives a position before the first index , Will return an empty list ; Provide steps of -1 Can be intercepted in reverse order
>>> x = ["first","second","third","fourth"]
>>> x[-1:2]
[]
>>> x[-1:2:-1]
['fourth']
>>>If both indexes are omitted , List replication can be realized . Modifying the copy of this list will not affect the original list
>>> x
['first', 'second', 'third', 'fourth']
>>>
>>> y = x[:]
>>> y[0] = '1st'
>>> y
['1st', 'second', 'third', 'fourth']
>>> x
['first', 'second', 'third', 'fourth']
>>>5.3 Modify the list
Slicing syntax can also be used in this way . similar lista[index1:index2]=listb Writing , It can lead to lista stay index1 and index2 All elements between are listb Replace the element of .listb The number of elements can be more or less lista Number of elements removed in , At this time lista The length of will be adjusted automatically .
Using slice assignment , Many functions can be realized , for example
(1) Append the list at the end of the list
>>> x = [1, 2, 3, 4]
>>> x[len(x):] = [5, 6, 7]
>>> x
[1, 2, 3, 4, 5, 6, 7]
>>>(2) Insert a list at the beginning of the list
>>> x[:0] = [-1, 0]
>>> x
[-1, 0, 1, 2, 3, 4, 5, 6, 7]
>>>(3) Remove list elements
>>> x[2:-2] = []
>>> x
[-1, 0, 6, 7]
>>>extend Methods and append The method is similar to , But it can append a list to another list
>>> y
['1st', 'second', 'third', 'fourth']
>>> x.extend(y)
>>> x
[-1, 0, 6, 7, '1st', 'second', 'third', 'fourth']
>>>The following attempts were made
x.extend(1) --> Will report a mistake , need iterable Data type of
x.extend('1') --> OK
x.extend([1]) --> OK
x.append('1') --> OK
x.append(1) --> OK
>>> x.extend(1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'int' object is not iterable
>>> Most of the time , Can be list.insert(n, elem) It is simply understood as , At the end of the list n Insert... Before elements elem.
When n When it is non negative ,list.insert(n, elem) And list[n:n] = [elem] The effect is the same .
The recommended way to delete a list item or slice is to use del sentence .
Usually ,del list[n] With the function of list[n:n+1] = [] It's the same , and del list[m:n] Its function is similar to list[m:n] = [] identical .
remove Will first find the first instance of the given value in the list , Then delete the value from the list ;
If remove Cannot find value to delete , Will cause an error .
List reverse Method is a more professional list modification method , You can efficiently reverse the list
Hands on questions : End the list 3 Data items moved from the end of the list to the beginning , And keep the order unchanged
>>> x
[-1, 0, 6, 7, '1st', 'second', 'third', 'fourth']
>>>
>>> x[:0] = x[-3:]
>>> x
['second', 'third', 'fourth', -1, 0, 6, 7, '1st', 'second', 'third', 'fourth']
>>> x[-3:] = []
>>> x
['second', 'third', 'fourth', -1, 0, 6, 7, '1st']
>>>5.4 Sort the list
sort Method will modify the list in order . If you don't want to modify the original list when sorting , There are two ways :
One is to use built-in sorted() function ; The other is to create a copy of the list first , Then sort the copies
>>> x = [2, 4, 1, 3]
>>> y = x[:]
>>> y.sort()
>>> y
[1, 2, 3, 4]
>>> x
[2, 4, 1, 3]
>>> sorted(x)
[1, 2, 3, 4]
>>> x
[2, 4, 1, 3]
>>>sort Methods can have optional reverse Parameters , When reverse=True Can achieve reverse sorting
>>> y.sort(reverse=True)
>>> y
[4, 3, 2, 1]
>>>sort Method can also use custom key functions to determine the order of list elements
>>> def compare_num_of_chars(string1):
... return len(string1)
...
>>> word_list = ['Python', 'Java', 'PHP', 'Go', 'C++']
>>> word_list.sort()
>>> word_list
['C++', 'Go', 'Java', 'PHP', 'Python']
>>> word_list.sort(key=compare_num_of_chars)
>>> word_list
['Go', 'C++', 'PHP', 'Java', 'Python']
>>>Hands on questions : List sorting assumes that the elements of a list are also lists :[[1, 2, 3], [2, 1, 3], [4, 0, 1]]. If you want to sort the list by the second element of each sub list , The result should be [[4, 0, 1], [2, 1, 3], [1, 2, 3]], So how to sort() Methodical key Parameter writing function ?
>>> def compare_2nd_ele(list1):
... return list1[1]
...
>>> testlist = [[1, 2, 3],[2, 1, 3],[4, 0, 11]]
>>> testlist.sort(key=compare_2nd_ele)
>>> testlist
[[4, 0, 11], [2, 1, 3], [1, 2, 3]]
>>>5.5 Other commonly used list operations
use * Operator initialization list
>>> z = [None] * 4
>>> z
[None, None, None, None]
>>>use index Method search list ; Calling index Before method , use in Test the list .
>>> x
[2, 4, 1, 3]
>>>
>>> x.index(4)
1
>>> x.index(5)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: 5 is not in list
>>>
>>> 5 in x
False
>>> 4 in x
True
>>>
use count Method to count the matches
count It will also traverse the list and find the given value , But it returns the number of times the value is found in the list
5.6 Nested list and deep copy
By full sectioning ( namely x[:]) You can get a copy of the list , use + or * The operator ( Such as x+[] or x*1) You can also get a copy of the list . But their efficiency is slightly lower than that of slicing . this 3 Both methods create so-called shallow copies (shallow copy)
If there are nested lists in the list , Then you may need a deep copy (deep copy). Deep copies can be accessed through copy Modular deepcopy Function to get , The deep copy is completely independent of the original variable , Its change has no effect on the original list .
>>> original = [[0],1]
>>> shallow = original[:]
>>>
>>> import copy
>>> deep = copy.deepcopy(original)
>>>
>>> shallow[1] = 2
>>> shallow
[[0], 2]
>>>
>>> original
[[0], 1]
>>> shallow[0][0] = 'zero'
>>> original
[['zero'], 1]
>>>
>>> deep[0][0] = 5
>>> deep
[[5], 1]
>>>
>>> original
[['zero'], 1]
>>>5.7 Tuples
How to create tuple copies , Exactly the same as the list :
Exchange the values of two variables
var1, var2 = var2, var1
>>> a = 1
>>> b = 2
>>> a, b = b, a
>>> a
2
>>> b
1
>>>Conversion between lists and tuples
>>> x
[2, 4, 1, 3]
>>> y
[1, 2, 3, 4]
>>>
>>>
>>> x
[2, 4, 1, 3]
>>> tuple(x)
(2, 4, 1, 3)
>>>
>>> x
[2, 4, 1, 3]
>>> y=tuple(x)
>>>
>>> list(y)
[2, 4, 1, 3]
>>>
use list, It's easy to split a string into characters
>>> list('Kubernetes')
['K', 'u', 'b', 'e', 'r', 'n', 'e', 't', 'e', 's']
>>>
5.8 aggregate
Items in the collection must be immutable 、 Hashable . That means , Integers 、 Floating point numbers 、 Strings and tuples can be members of a collection , But the list 、 Dictionaries and collections themselves cannot .
Through the sequence ( As listing ) call set function , You can create collections , Duplicate elements will be removed .
use set After the function creates the collection , It can be used add and remove Modify the elements in the collection .
keyword in It can be used to check whether an object is a member of a collection .
With the operator “|” You can get the union of two sets ;
With the operator “&” Intersection can be obtained ;
With the operator “^” Then the symmetry difference can be obtained (symmetric difference), Symmetry difference refers to , Elements that belong to one but not both sets .
Collection types frozenset, It's immutable 、 Hashable , Therefore, it can be a member of other sets
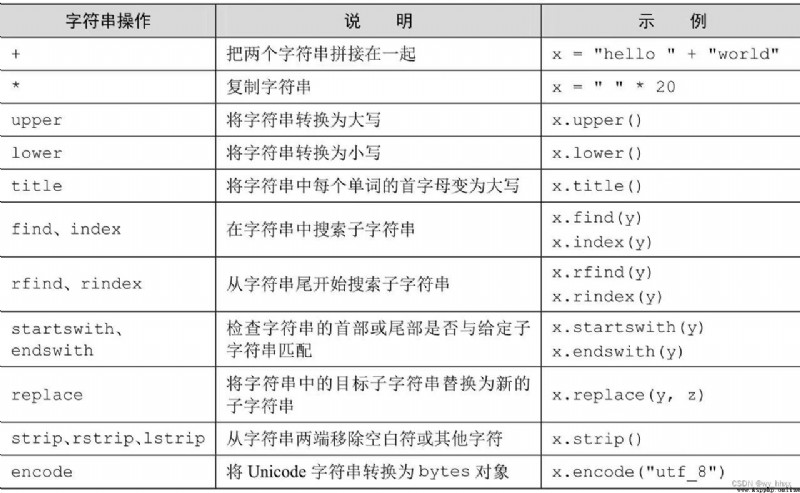
6.4 String method
6.4.1 A string of split and join Method
>>> "::".join(["Separated", "with", "colons"])
'Separated::with::colons'
>>>
>>> 'Separated::with::colons'.split(":")
['Separated', '', 'with', '', 'colons']
>>> 'Separated::with::colons'.split("::")
['Separated', 'with', 'colons']
>>>
>>>
>>> '123 4 5 7 8 /t 999'.split()
['123', '4', '5', '7', '8', '/t', '999']
>>>
>>> '123 4 /n 5 7/n 8/t 999'.split()
['123', '4', '/n', '5', '7/n', '8/t', '999']
>>>You can use an empty string "" To splice the elements of the string list :
>>> "".join(["Separated", "by", "nothing"])
'Separatedbynothing'
>>>By giving split Method passes in the second optional parameter to specify the number of times to split when generating the result . Suppose you specify to split n Time , be split Method will split the input string from scratch , Or execute n Stop splitting after times ( At this time, the generated list contains n+1 Substring )
If you want to use the second parameter , And split it according to the blank character , Please set the first parameter to None.
>>> x
[2, 4, 1, 3]
>>>
>>> x = 'a b c d'
>>> x.split(' ',2)
['a', 'b', 'c d']
>>> x.split(None,2)
['a', 'b', 'c d']
>>>6.4.3 Remove extra white space
>>> x = " Hello, World\t \t "
>>> x
' Hello, World\t \t '
>>> x.strip()
'Hello, World'
>>> x
' Hello, World\t \t '
>>>
>>> x.lstrip()
'Hello, World\t \t '
>>> x.rstrip()
' Hello, World'
>>>strip、rstrip and lstrip Method can also be attached with a parameter , This parameter contains the characters that need to be removed . Is to match and delete from outside to inside , Until the first / The tail no longer contains any specified characters .
>>> x = "asdf Hello, World RRR"
>>> x.strip('R')
'asdf Hello, World '
>>> x.lstrip('sdfaR')
' Hello, World RRR'
>>> x.rstrip('sdfaR ')
'asdf Hello, Worl'
>>>6.4.4 String search
The basic string search methods are 4 individual , namely find、rfind、index and rindex, They're similar .
find Method will return the position of the first character of the first instance of the substring in the calling string object , If no substring is found, return -1
find Methods can also take one or two optional parameters . The first optional parameter ( If there is )start It's an integer. , Will make find Ignore the position in the string when searching for substrings start All the characters before . The second optional parameter ( If there is )end It's also an integer , Will make find Ignore location end after ( contain ) The characters of :
rfind The function and of the method find The method is almost identical , But start searching from the end of the string , Returns the first character position of the substring when it last appears in the string
When index or rindex Method ( Functions are different from find and rfind identical ) When a substring is not found in the string , Will not return -1, It will trigger ValueError.
startswith and endswith Method can search multiple substrings at a time . If the parameter is a string tuple , Then these two methods will detect all strings in tuples , As long as there is a string match, it will return True
>>> x = "Mississippi"
>>> x.startswith('Miss')
True
>>> x.startswith('miss')
False
>>> x.startswith(('miss','Miss'))
True
>>>
6.4.5 String modification
use replace Method can substring in the string ( The first parameter ) Replace all with another string ( The second parameter ).
>>> x.replace('ss','++')
'Mi++i++ippi'
>>>
function string.maketrans and string.translate Can be used together , Convert multiple characters in a string to other characters .
>>> x = "~x ^ (y % z)"
>>> table = x.maketrans("~^()", "!&[]")
>>> x.translate(table)
'!x & [y % z]'
>>>
The second line of code is maketrans A translation comparison table is constructed , The data comes from its two string parameters . The number of characters of these two parameters must be the same . then maketrans The generated cross reference table is passed to translate Method .
Determine whether the string is a number 、 Letters, etc
>>> x = "123"
>>> x.isalpha()
False
>>> x.isdigit()
True
>>>
>>> y = "ZH"
>>> y.islower()
False
>>> y.isupper()
True
>>>
Hands on questions : String operation assumes a list of strings x, There are some strings ( Not necessarily all ) It starts and ends with double quotation marks :x = ['"abc"', 'def', '"ghi"', '"klm"', 'nop'] , What code should I use to traverse all elements and remove only double quotes ?
>>> x
['"abc"', 'def', '"ghi"', '"klm"', 'nop']
>>>
>>>
>>> y = []
>>> for i in x:
... i = i.strip('"')
... y.append(i)
...
>>> y
['abc', 'def', 'ghi', 'klm', 'nop']
>>>How to find "Mississippi" The last letter in p The location of ? How to remove only this letter after finding it ?
Method 1 :
>>> if x.rfind('p') != -1:
... y = list(x)
... y.pop(x.rfind('p'))
... x = "".join(y)
...
'p'
>>> x
'Mississipi'
>>>Method 2 :
>>> x = 'Mississippi'
>>> loc = x.rfind('p')
>>> if loc != -1:
... x = x[:loc] + x[loc+1:]
...
>>> x
'Mississipi'
>>>
Method 3 ( Only the second question was answered ):
>>> x
'Mississippi'
>>>
>>> x_reverse = x[::-1]
>>> x_reverse
'ippississiM'
>>>
>>> x_reverse_list = x_reverse.split('p',1)
>>> x_reverse_list
['i', 'pississiM']
>>>
>>> x = (''.join(x_reverse_list))[::-1]
>>> x
'Mississipi'
>>>
6.5 Convert objects to strings
be used Python Before object-oriented features ,repr and str There is no difference between . In order to maintain a good programming style , Please get used to str instead of repr To create string information for display .
>>> repr(len)
'<built-in function len>'
>>> repr([1,2,3,4])
'[1, 2, 3, 4]'
>>>
>>> str(len)
'<built-in function len>'
>>> str([1,2,3,4])
'[1, 2, 3, 4]'
>>>
6.6 Use format Method
format Method uses two parameters , At the same time, the format string containing the replaced field is given , And the replaced value . The replaced field here uses {} Identification of the . If you want to include characters in the string “{” or “}”, Please use “{ {” or “}}” To express .
6.6.1 format Methods and positional parameters
Use the number of the replaced field , Corresponding to the incoming parameters
>>> "{0} is {1} of {2}".format("Today","28th","June")
'Today is 28th of June'
>>>6.6.2 format Methods and named parameters
>>> "Today is {day} of {month}".format(month="June",day="28th")
'Today is 28th of June'
>>>
It is also allowed to use both positional and named parameters , You can even access attributes and elements in parameters
>>> "{0} is {day} of {month[5]} ({1})".format("Today","Tuesday",day="28th",month=["Jan","Feb","Mar","Apr","May","June","July"])
'Today is 28th of June (Tuesday)'
>>>Be careful : The position parameter should be written in front of the named parameter , Otherwise, an error will be reported
>>> "{0} is {day} of {month[5]} ({1})".format("Today",day="28th",month=["Jan","Feb","Mar","Apr","May","June","July"],"Tuesday")
File "<stdin>", line 1
"{0} is {day} of {month[5]} ({1})".format("Today",day="28th",month=["Jan","Feb","Mar","Apr","May","June","July"],"Tuesday")
^
SyntaxError: positional argument follows keyword argument
>>>
6.6.3 Format descriptor
>>> "{0:10} is {1} of {2}".format("Today","28th","June")
'Today is 28th of June'
>>>
>>> "{0:{3}} is {1} of {2}".format("Today","28th","June",10)
'Today is 28th of June'
>>>
>>> "{0:{width}} is {1} of {2}".format("Today","28th","June",width=10)
'Today is 28th of June'
>>> "{0:>10} is {1} of {2}".format("Today","28th","June")
' Today is 28th of June'
>>> "{0:#>10} is {1} of {2}".format("Today","28th","June")
'#####Today is 28th of June'
>>> "{0:#<10} is {1} of {2}".format("Today","28th","June")
'Today##### is 28th of June'
>>>
The descriptor “:10” Set the width of this field to 10 Characters , Fill in the insufficient part with space .
The descriptor “:{1}” Indicates that the field width is defined by the second parameter .
The descriptor “:>10” Force field right alignment , Fill in the insufficient part with space .
The descriptor “:&>10” Force right alignment , There is no blank space for the insufficient part, but “&” Character padding .
6.7 use % Formatted string
String modulo operator % It's made up of two parts : On the left is the string , On the right is the tuple . The string modulo operator will scan the string on the left , Find a specific formatting sequence (formatting sequence), And replace it with the value on the right in order to generate a new string .
>>> "%s is %s of %s" % ("Today","28th","June")
'Today is 28th of June'
>>>
6.7.1 Use formatting sequence
>>> "Pi is <%-6.2f>" % 3.14159
'Pi is <3.14 >'
>>> "Pi is <%6.2f>" % 3.14159
'Pi is < 3.14>'
>>>
>>> "Pi is <%3.2f>" % 3.14159
'Pi is <3.14>'
>>>
%-6.2f The total number of characters 6, After the decimal point 2 position , Align left
6.7.2 Name parameters and format sequences
>>> num_dict = {'e': 2.718, 'pi': 3.14159}
>>> print("%(pi).2f - %(pi).4f - %(e).2f" % num_dict)
3.14 - 3.1416 - 2.72
>>>
use print Function control output
Control the separator and the end of each line
>>> print("a","b","c",sep=" | ")
a | b | c
>>>
>>> print("a","b","c",end="\n\n")
a b c
>>>
print Function can also output the result to a file
>>> print("a","b","c",file=open("testfile.txt","w"))
>>>
# cat testfile.txt
a b c
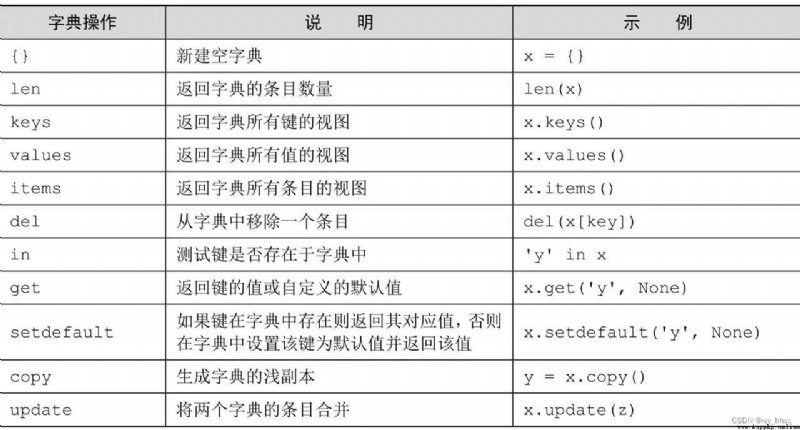
7.2 Other operations of the dictionary
keys Method to get all the keys in the dictionary
values Method to get all the values stored in the dictionary
items Method returns all keys and their associated values as a tuple sequence
>>> english_to_french = {'red': 'rouge', 'blue': 'bleu', 'green': 'vert'}
>>> list(english_to_french.keys())
['red', 'blue', 'green']
>>> list(english_to_french.values())
['rouge', 'bleu', 'vert']
>>> list(english_to_french.items())
[('red', 'rouge'), ('blue', 'bleu'), ('green', 'vert')]
>>>
del Statement can be used to remove entries from the dictionary , That is, key value pairs
>>> del english_to_french['green']
>>> english_to_french
{'red': 'rouge', 'blue': 'bleu'}
>>>
keys、values and items The return result of the method is not a list , It's a view (view).
>>> english_to_french.items()
dict_items([('red', 'rouge'), ('blue', 'bleu')])
>>>
If the key to access does not exist in the dictionary , Will be Python It is regarded as an error . You can use in Keyword first check whether the key exists in the dictionary .
Or you can use get Function to detect .
>>> english_to_french.get('blue', 'No translation')
'bleu'
>>> english_to_french.get('chartreuse', 'No translation')
'No translation'
>>> english_to_french
{'red': 'rouge', 'blue': 'bleu', 'green': 'vert'}
>>>
get and setdefault The difference is , above setdefault After calling , Will generate keys in the dictionary 'chartreuse' And the corresponding values 'No translation'.
>>> english_to_french.setdefault('chartreuse', 'No translation')
'No translation'
>>> english_to_french
{'red': 'rouge', 'blue': 'bleu', 'green': 'vert', 'chartreuse': 'No translation'}
>>>
copy Method generates a shallow copy of the dictionary , In most cases, it should meet the needs . If the dictionary value contains modifiable objects , Such as lists or other dictionaries , Then you may need to use copy.deepcopy Function generates a deep copy .
>>> x = {0: 'zero', 1: 'one'}
>>> y = x.copy()
>>> y
{0: 'zero', 1: 'one'}
>>>
Dictionary update Method will use the second dictionary ( The parameter ) All keys for / Value pairs update the first dictionary ( The caller ).
>>> x
{0: 'zero', 1: 'one'}
>>>
>>> z = {1: 'ONE', 2: 'TWO'}
>>> x.update(z)
>>> x
{0: 'zero', 1: 'ONE', 2: 'TWO'}
>>>
7.3 Word count
>>> sample_string = "To be or not to be"
>>> occurrences = {}
>>> for word in sample_string.split():
... occurrences[word] = occurrences.get(word,0) + 1
...
>>> occurrences
{'To': 1, 'be': 2, 'or': 1, 'not': 1, 'to': 1}
>>>
The above has been standardized as Counter class , Built in collections Module
>>> from collections import Counter
>>> sample_string = "To be or not to be"
>>> count_result = Counter(sample_string.split())
>>> print(count_result)
Counter({'be': 2, 'To': 1, 'or': 1, 'not': 1, 'to': 1})
>>>7.4 Objects that can be used as dictionary keys
The above example uses string as dictionary key . But not just strings , Any immutable (immutable) And hash (hashable) Of Python object , Can be used as a dictionary key .
For tuples , Only tuples that do not contain any mutable nested objects are hashable , Keys that can be used effectively as dictionaries .