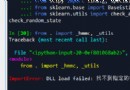
最近在學爬蟲爬小說,遇到個網頁裡面有一個亂碼。它網頁是gb2312編碼,我用gb2312、gbk、utf-8都試了一遍識別不了。因為我是在整頁整頁的爬文字,一報錯就是一章內容沒下,就很難受。
想問問大家,有沒有辦法直接不管那個無法編碼的字符,直接將提取的內容寫入?
下載代碼如下
#下載async def download(url, name): async with semaphore: async with aiohttp.ClientSession() as session: async with session.get(url) as reques: reques.encoding = 'gbk' page = bs4.BeautifulSoup(await reques.text(), 'html.parser') div = page.find('div', class_="read_chapterDetail") p = div.find_all('p') # 打開文件,打開方式,數據為二進制 with open(f'{name}.txt', mode='wb') as f: for i in p: text = i.text + '\n' f.write(text.encode('utf-8')) print(f'{name}下載完成!')