This is a apriori Part of the algorithm code . We want to start with only 1 The frequent itemsets of items are included 2 Frequent itemsets of items . The code is as follows :
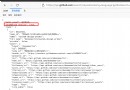
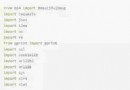
from collections import defaultdict\n", "\n", "def find_frequent_itemsets(favorable_reviews_by_users, k_1_itemsets, min_support):\n", " counts = defaultdict(int)\n", " for user, reviews in favorable_reviews_by_users.items():\n", " for itemset in k_1_itemsets:\n", " if itemset.issubset(reviews):\n", " for other_reviewed_movie in reviews - itemset:\n", " current_superset = itemset | frozenset((other_reviewed_movie,))\n", " counts[current_superset] += 1\n", " return dict([(itemset, frequency) for itemset, frequency in counts.items() if frequency >= min_support])"
I think the frequent itemsets here are recalculated . for example : For users 1 Come on , aggregate {A,B} and {B,A} It's the same , But according to the code :
for itemset in k_1_itemsets:\n", " if itemset.issubset(reviews):\n", " for other_reviewed_movie in reviews - itemset:\n", " current_superset = itemset | frozenset((other_reviewed_movie,))\n", " counts[current_superset] += 1\n",
When itemset==A, We are right. {A,B} Count once ,
When itemset==B, We are right. {B,A} Count again ,
So here is not repeated counting ? If it is , How to modify the program ?