This article talks about the famous support vector machine in the industry , The algorithm is famous , First, there are few model parameters , Adjust slightly , It can be used directly ; Second, it has a solid foundation of mathematical theory ; Third, the effect of the model is good . Therefore, it is favored by all gods , It can be said that before the emergence of deep learning , Is one of the best machine learning methods .
1、 The concept of support vector machine
Support vector machine (support vector machine,SVM), You can take two parts apart , One is support vector , seeing the name of a thing one thinks of its function , Is the vector that supports the construction of classifiers ; Second, machine , It means machine , That is, the meaning of classifier , Understand the meaning and terms involved from a simple example .
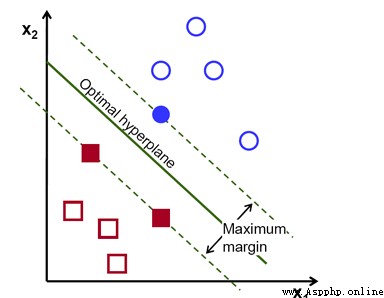
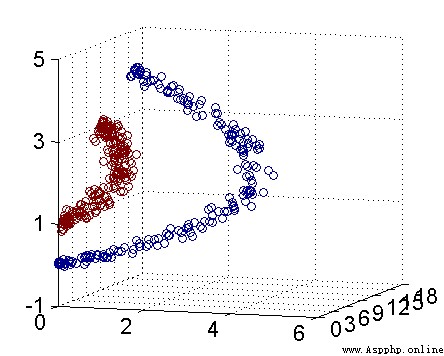
In this diagram , Blue circles and red blocks are two categories to distinguish , The split line in the middle is the classification function , Solid points are support vectors , This is also the origin of the algorithm . And the classification function needs to be found through the model , But there are many classification functions that can distinguish , Therefore, we need to find a most stable and optimal classifier , The classifier can reach the maximum classification boundary , That is, the support vector reaches the maximum of the classifier .
This is a linearly separable case , So what is a linearly separable function ? In one-dimensional space is a point , Two dimensional space is a straight line , Three dimensional space is a plane , And in four dimensions and above , It's beyond imagination , It can be collectively referred to as hyperplane .
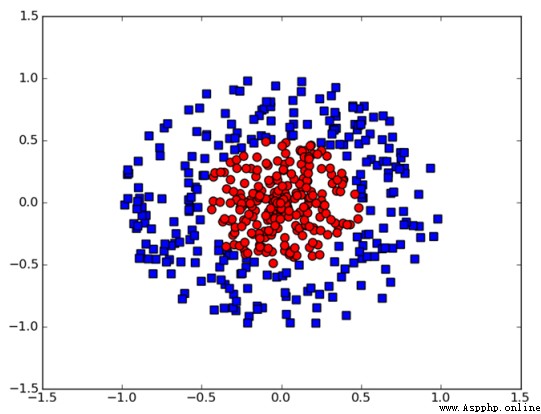
But generally, we will encounter nonlinear situations , therefore SVM The method of mapping low dimensional data to high dimensional space through a kernel function , Thus, the nonlinear problem is transformed into a linear problem . As shown in the figure , Through data mapping , It is obvious that there is a straight line that can distinguish them .
in addition , Although the value of kernel function maps features from low dimensional space to high dimensional space , But the best part of it is through the calculation in low dimensional space , It can realize the classification of high-dimensional space , Thus avoiding dimensional disasters , Therefore, the amount of calculation is reduced .
2、 Characteristics of support vector machine
Here's the picture ,X It's cattle , The point is wolves , How to build a suitable fence between them ? This is also a binary classification problem . The picture below is SVM、 Logistic regression and decision tree construction model results . It can be seen that SVM The classification of is more in line with the actual use , This is the advantage of nonlinear classification .
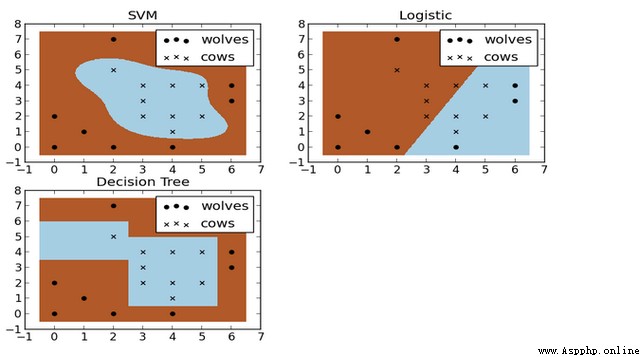
SVM The advantage of is less computation , The effect is good ; But its disadvantage is that it is sensitive to parameter adjustment and kernel function selection .
3、 Derivation of support vector machine
On the derivation of support vector machine , There are many good materials on the Internet , They all spoke clearly and thoroughly , Such as 《 General introduction to support vector machines ( understand SVM Three levels of state )》, There are also videos to watch . So I'm not going to talk too much about it . But there are still some learning experiences for reference only .
(1) The core of support vector machine is to find a classifier that can maximize the interval interval ;
(2) Use Lagrange multiplier method and KKT Conditions , Transform it into an optimization problem with constraints ,
(3) Only support vectors are used to predict unknown samples ;
(4) Map data to high-dimensional space through kernel function , Convert to linear separable ;
(5) You need to set parameters yourself C and K, among C For relaxation variables , To balance the penalty error , The larger the value, the less error ;K Is the parameter of kernel function , Determines the distribution mapped to high-dimensional space .
The following article is collated from the network , For reference only .

4、SMO solve
from SVM Formula derivation of , It can be seen that as long as we find alpha, You can solve w and b, The required hyperplane can be obtained . And ask alpha Methods , At present, it is more popular to use SMO Algorithm , That is, sequence minimum optimization algorithm .
among SMO The principle of the algorithm is : First choose two alpha Optimize , Fix other alpha; Once you find the right one alpha, Then increase one and decrease the other . Because all alpha And for 0.
among SMO The solution steps are ( Pseudo code ):
(1) Initialize alpha, Set it to 0 vector ;
(2) Set the maximum number of iterations ( Outer loop ), When the number of iterations < Maximum number of iterations :
(3) For each data vector in the dataset ( Inner loop )
:(4) If the data vector can be optimized (> Set the minimum error ):
(5) Randomly select another data vector :
(6) Optimize the two vectors selected at the same time :
(7) If neither vector can be optimized , Exit the inner loop
(8) If all vectors are not optimized , Increase the number of iterations , So let's go to the next loop
Because the chosen vector is random , So many iterations are needed , Until alpha Not until optimization .
A simple version of the algorithm Python The code is as follows :
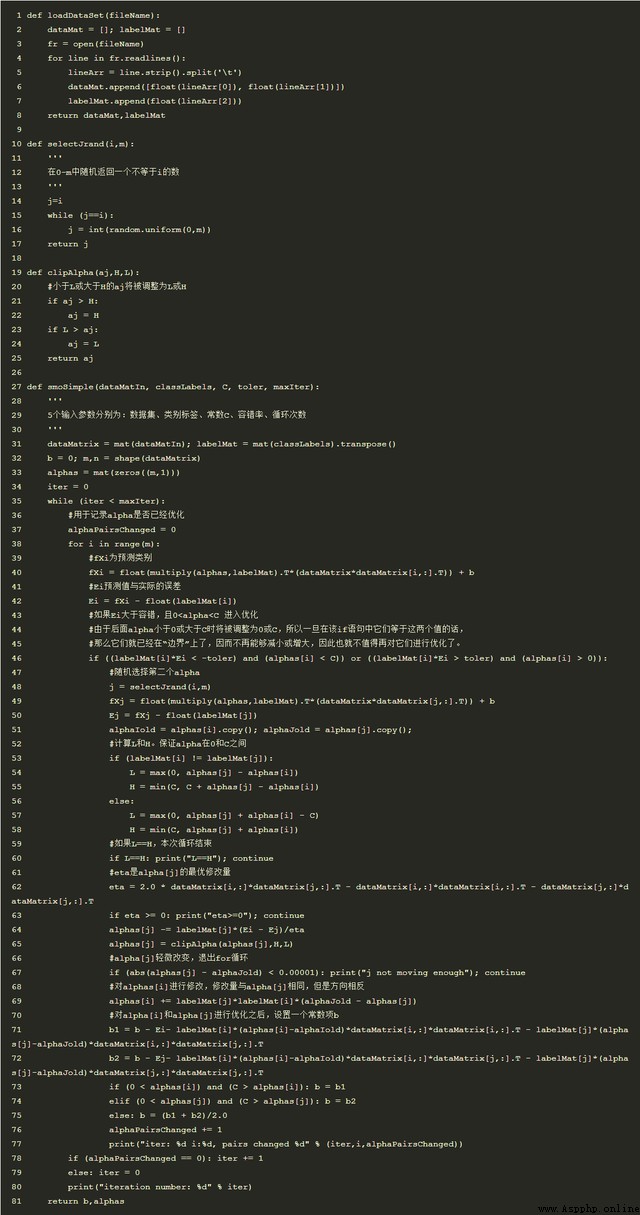
Test results of samples :
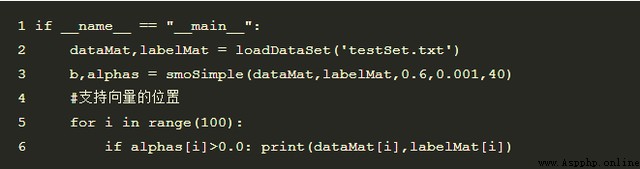
The output is , Indicates that the support vector is 4 individual , Among them, positive samples 1 individual , Negative sample 3:
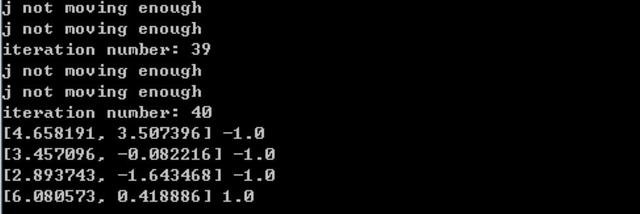
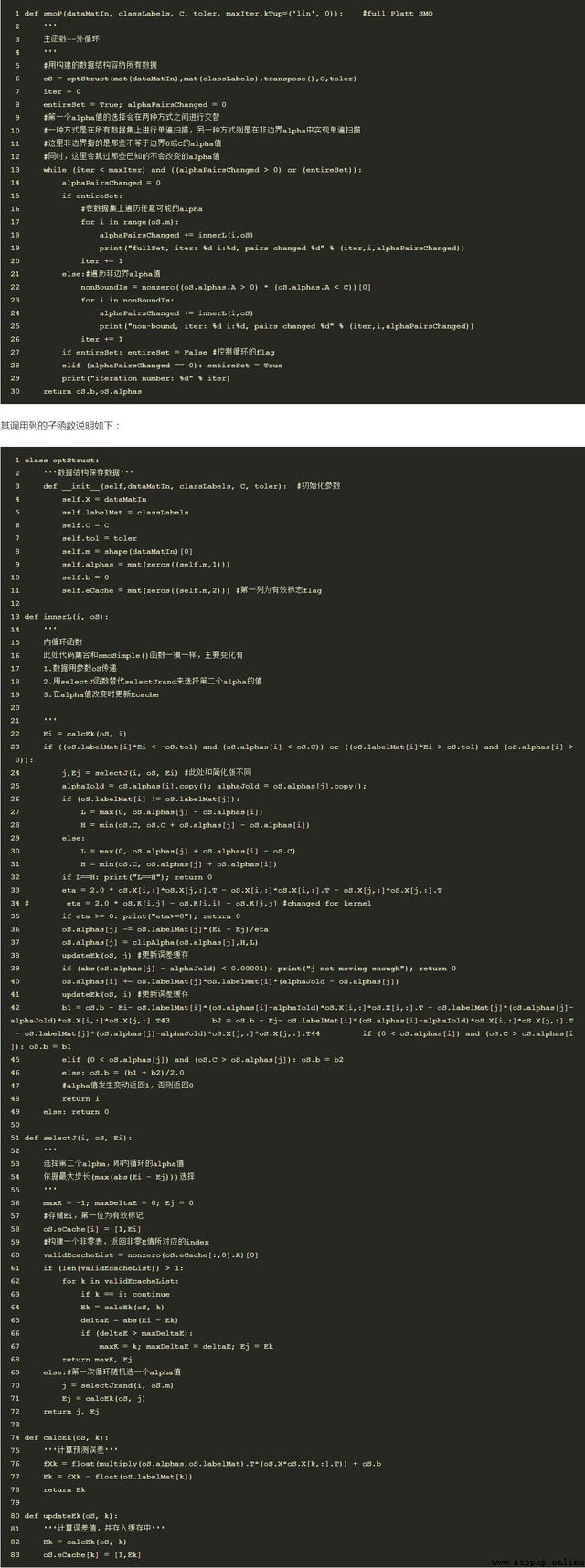
in addition , To speed up the calculation , The simplified version is optimized , The method for
Platt SMO, Select two from the external circulation and the internal circulation alpha value , Fast convergence .
in addition , By calculation alpha, It can be solved w, Therefore, we can solve y=w*x+b To determine the hyperplane ; The specific code is as follows :
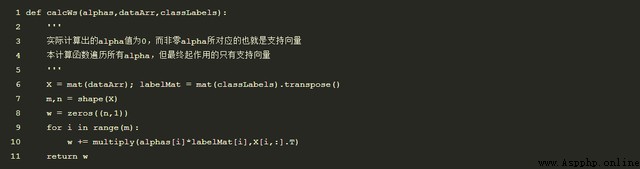
The calculation example is as follows ,>0 Presentation category 1,<0 Presentation category -1:

5、 Kernel function of support vector machine
What I mentioned in the previous section can only solve linear problems , As for the following figure , The effect is not good . At this time, we need to use kernel function . Intuitively speaking, the following figure is two circles , Therefore, if it is mapped to three-dimensional space, it can be distinguished by a plane . If through will (x,y) It maps to (x,y,x^2+y^2)
Gaussian radial basis function is generally used
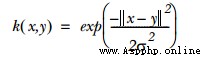
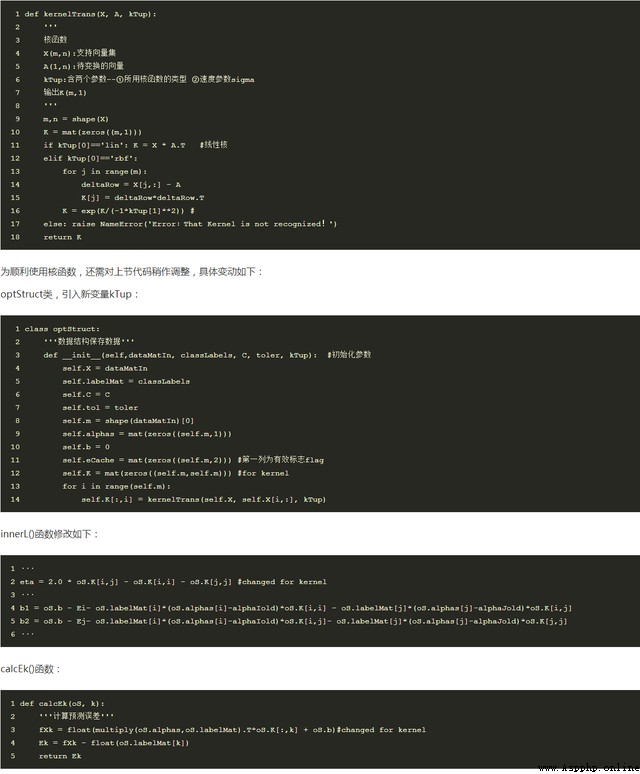
among sigam Is the parameter for calculating the convergence rate , It is also a parameter that needs to be adjusted and optimized . The relevant codes are as follows
KernelTrans(): Functions are used to transform vectors .
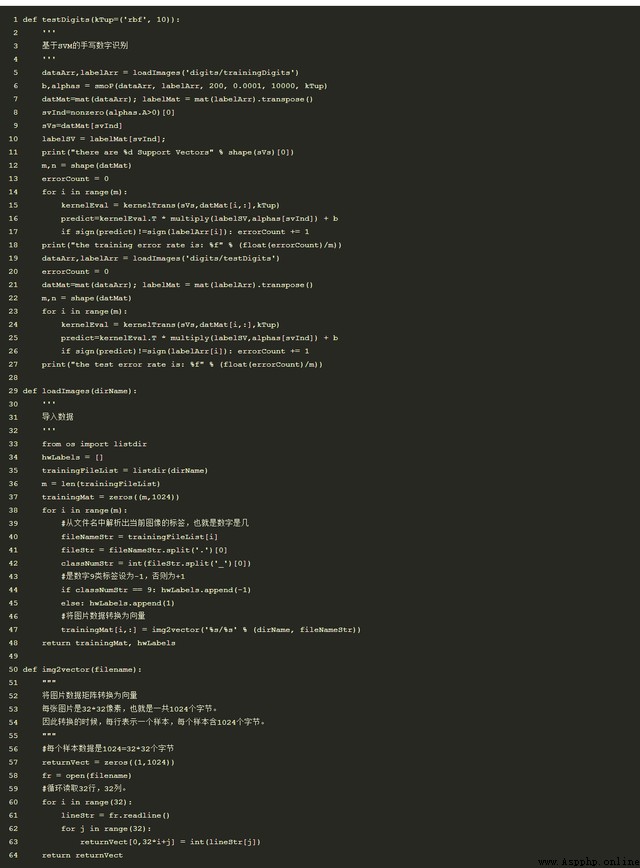
6、Python Implementation example
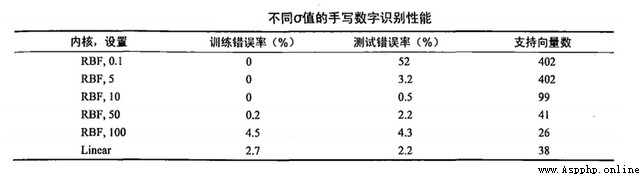
The example used this time is handwriting recognition sample , There are two types of samples , among 0 Set to 1,9 Set to -1. The advantage of this method is that it only needs to save the support vector machine to predict .
give the result as follows , The parameters selected this time are C=200,sigma=10
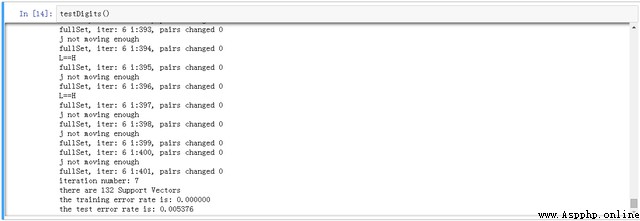
in addition ,C and k Value and other parameters have different values , The resulting prediction results and support vectors are also different , It also shows that this method is sensitive to parameter adjustment . The linear model is also compared , The result of kernel function is better .