requests包是python使用最多的第三方URL獲取資源的包,可以輕松實現get/post訪問、接口測試等。
requests安裝這裡就不多贅述了,直接pip安裝就可。
pip install requests
使用前引入requests包import requests,調用get()方法執行get請求,具體代碼如下:
import requests
# 獲取豆瓣電影首頁標簽
url = 'https://movie.douban.com/j/search_tags?type=movie&source=index'
r = requests.get(url)
r.encoding = 'utf-8'
data = r.json()
print(data)
當在執行這段代碼時會發現報錯,信息如下。這是因為豆瓣的訪問需要在請求頭中添加浏覽器信息User-Agent,代表是通過浏覽器訪問。
...
raise RequestsJSONDecodeError(e.msg, e.doc, e.pos)
requests.exceptions.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
如何獲取浏覽器User-Agent信息?
打開浏覽器,按F12或者點擊設置,打開開發者工具。然後選擇Network,找一個連接查看Headers信息,復制出User-Agent的value值即可。
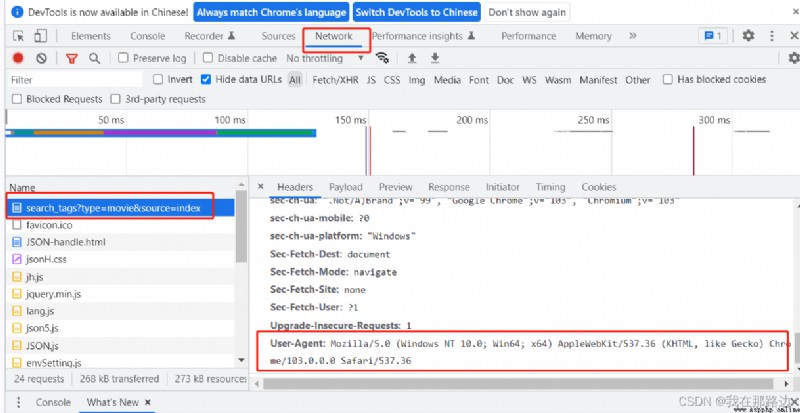
修改後代碼如下:
import requests
# 請求頭中添加浏覽器信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.134 Safari/537.36 Edg/103.0.1264.71'
}
# 獲取豆瓣電影首頁標簽
url = 'https://movie.douban.com/j/search_tags?type=movie&source=index'
r = requests.get(url, headers=headers)
r.encoding = 'utf-8'
data = r.json()
print(data)
執行後輸出信息如下:
{
'tags': ['熱門', '最新', '豆瓣高分', '冷門佳片', '華語', '歐美', '韓國', '日本']}
到這裡requests包的基本使用介紹就結束了,在浏覽器開發者工具中我們能看到上述url的Headers信息,一般在獲取url資源時都會先分析對應的請求頭來寫代碼。
General(基本信息),Request Method: GET得知是get請求,所以調用requests.get()方法。
Responsese Headers(響應頭信息),Content-Type: application/json; charset=utf-8代表返回的內容是json格式,所以解析數據用r.encoding = 'utf-8'編碼,data = r.json()獲取json信息。
Request Headers(請求頭信息),這裡主要的是Cookie/User-Agent/token等。Cookie一般存儲浏覽器認證信息,比如用戶標識等,一般相同的cookie代表是同一用戶訪問,但是也有將認證信息用token的傳遞的。
本節介紹了requests包調用get請求的基礎使用方法,同時介紹了浏覽器頭信息的獲取方法和對應基本參數的含義,希望對你有幫助。