這是我參與2022首次更文挑戰的第8天,活動詳情查看:2022首次更文挑戰
Python 一直以來被大家所诟病的一點就是執行速度慢,但不可否認的是 Python 依然是我們學習和工作中的一大利器。因此,我們對 Python 呢是“又愛又恨”。
本文總結了一些小 tips 有助於提升 Python 執行速度、優化性能。以下所有技巧都經過我的驗證,可放心食用。
先上結論:
map()進行函數映射set()求交集sort()或sorted()排序collections.Counter()計數join()連接字符串x, y = y, x交換變量while 1取代while True.)的使用for循環取代while循環Numba.jit加速計算Numpy矢量化數組in檢查列表成員itertools庫迭代關於 Python 如何精確地測量程序的執行時間,這個問題看起來簡單其實很復雜,因為程序的執行時間受到很多因素的影響,例如操作系統、Python 版本以及相關硬件(CPU 性能、內存讀寫速度)等。在同一台電腦上運行相同版本的語言時,上述因素就是確定的了,但是程序的睡眠時間依然是變化的,且電腦上正在運行的其他程序也會對實驗有干擾,因此嚴格來說這就是《實驗不可重復》。
我了解到的關於計時比較有代表性的兩個庫就是time和timeit。
其中,time庫中有time()、perf_counter()以及process_time()三個函數可用來計時(以秒為單位),加後綴_ns表示以納秒計時(自 Python3.7 始)。在此之前還有clock()函數,但是在 Python3.3 之後被移除了。上述三者的區別如下:
time()精度上相對沒有那麼高,而且受系統的影響,適合表示日期時間或者大程序的計時。perf_counter()適合小一點的程序測試,會計算sleep()時間。process_time()適合小一點的程序測試,不計算sleep()時間。與time庫相比,timeit 有兩個優點:
timeit 會根據您的操作系統和 Python 版本選擇最佳計時器。timeit 在計時期間會暫時禁用垃圾回收。timeit.timeit(stmt='pass', setup='pass', timer=<default timer>, number=1000000, globals=None) 參數說明:
stmt='pass':需要計時的語句或者函數。setup='pass':執行stmt之前要運行的代碼。通常,它用於導入一些模塊或聲明一些必要的變量。timer=<default timer>:計時器函數,默認為time.perf_counter()。number=1000000:執行計時語句的次數,默認為一百萬次。globals=None:指定執行代碼的命名空間。本文所有的計時均采用timeit方法,且采用默認的執行次數一百萬次。
為什麼要執行一百萬次呢?因為我們的測試程序很短,如果不執行這麼多次的話,根本看不出差距。
map()進行函數映射Exp1:將字符串數組中的小寫字母轉為大寫字母。
測試數組為 oldlist = ['life', 'is', 'short', 'i', 'choose', 'python']。
newlist = []
for word in oldlist:
newlist.append(word.upper())
復制代碼list(map(str.upper, oldlist))
復制代碼方法一耗時 0.5267724000000005s,方法二耗時 0.41462569999999843s,性能提升 21.29%
set()求交集 Exp2:求兩個list的交集。
測試數組:a = [1,2,3,4,5],b = [2,4,6,8,10]。
overlaps = []
for x in a:
for y in b:
if x == y:
overlaps.append(x)
復制代碼list(set(a) & set(b))
復制代碼方法一耗時 0.9507264000000006s,方法二耗時 0.6148200999999993s,性能提升 35.33%
關於set()的語法:|、&、-分別表示求並集、交集、差集。
sort()或sorted()排序我們可以通過多種方式對序列進行排序,但其實自己編寫排序算法的方法有些得不償失。因為內置的 sort()或 sorted() 方法已經足夠優秀了,且利用參數key可以實現不同的功能,非常靈活。二者的區別是sort()方法僅被定義在list中,而sorted()是全局方法對所有的可迭代序列都有效。
Exp3:分別使用快排和sort()方法對同一列表排序。
測試數組:lists = [2,1,4,3,0]。
def quick_sort(lists,i,j):
if i >= j:
return list
pivot = lists[i]
low = i
high = j
while i < j:
while i < j and lists[j] >= pivot:
j -= 1
lists[i]=lists[j]
while i < j and lists[i] <=pivot:
i += 1
lists[j]=lists[i]
lists[j] = pivot
quick_sort(lists,low,i-1)
quick_sort(lists,i+1,high)
return lists
復制代碼lists.sort()
復制代碼方法一耗時 2.4796975000000003s,方法二耗時 0.05551999999999424s,性能提升 97.76%
順帶一提,sorted()方法耗時 0.1339823999987857s。
可以看出,sort()作為list專屬的排序方法還是很強的,sorted()雖然比前者慢一點,但是勝在它“不挑食”,它對所有的可迭代序列都有效。
擴展:如何定義sort()或sorted()方法的key
lambda定義#學生:(姓名,成績,年齡)
students = [('john', 'A', 15),('jane', 'B', 12),('dave', 'B', 10)]
students.sort(key = lambda student: student[0]) #根據姓名排序
sorted(students, key = lambda student: student[0])
復制代碼operator定義import operator
students = [('john', 'A', 15),('jane', 'B', 12),('dave', 'B', 10)]
students.sort(key=operator.itemgetter(0))
sorted(students, key = operator.itemgetter(1, 0)) #先對成績排序,再對姓名排序
復制代碼
operator的itemgetter()適用於普通數組排序,attrgetter()適用於對象數組排序
cmp_to_key()定義,最為靈活import functools
def cmp(a,b):
if a[1] != b[1]:
return -1 if a[1] < b[1] else 1 #先按照成績升序排序
elif a[0] != b[0]:
return -1 if a[0] < b[0] else 1 #成績相同,按照姓名升序排序
else:
return -1 if a[2] > b[2] else 1 #成績姓名都相同,按照年齡降序排序
students = [('john', 'A', 15),('john', 'A', 14),('jane', 'B', 12),('dave', 'B', 10)]
sorted(students, key = functools.cmp_to_key(cmp))
復制代碼collections.Counter()計數Exp4:統計字符串中每個字符出現的次數。
測試數組:sentence='life is short, i choose python'。
counts = {}
for char in sentence:
counts[char] = counts.get(char, 0) + 1
復制代碼from collections import Counter
Counter(sentence)
復制代碼方法一耗時 2.8105250000000055s,方法二耗時 1.6317423000000062s,性能提升 41.94%
列表推導(list comprehension)短小精悍。在小代碼片段中,可能沒有太大的區別。但是在大型開發中,它可以節省一些時間。
Exp5:對列表中的奇數求平方,偶數不變。
測試數組:oldlist = range(10)。
newlist = []
for x in oldlist:
if x % 2 == 1:
newlist.append(x**2)
復制代碼[x**2 for x in oldlist if x%2 == 1]
復制代碼方法一耗時 1.5342976000000021s,方法二耗時 1.4181957999999923s,性能提升 7.57%
join() 連接字符串大多數人都習慣使用+來連接字符串。但其實,這種方法非常低效。因為,+操作在每一步中都會創建一個新字符串並復制舊字符串。更好的方法是用 join() 來連接字符串。關於字符串的其他操作,也盡量使用內置函數,如isalpha()、isdigit()、startswith()、endswith()等。
Exp6:將字符串列表中的元素連接起來。
測試數組:oldlist = ['life', 'is', 'short', 'i', 'choose', 'python']。
sentence = ""
for word in oldlist:
sentence += word
復制代碼"".join(oldlist)
復制代碼方法一耗時 0.27489080000000854s,方法二耗時 0.08166570000000206s,性能提升 70.29%
join還有一個非常舒服的點,就是它可以指定連接的分隔符,舉個例子
oldlist = ['life', 'is', 'short', 'i', 'choose', 'python']
sentence = "//".join(oldlist)
print(sentence)
復制代碼life//is//short//i//choose//python
x, y = y, x交換變量Exp6:交換x,y的值。
測試數據:x, y = 100, 200。
temp = x
x = y
y = temp
復制代碼x, y = y, x
復制代碼方法一耗時 0.027853900000010867s,方法二耗時 0.02398730000000171s,性能提升 13.88%
while 1取代while True在不知道確切的循環次數時,常規方法是使用while True進行無限循環,在代碼塊中判斷是否滿足循環終止條件。雖然這樣做沒有任何問題,但while 1的執行速度比while True更快。因為它是一種數值轉換,可以更快地生成輸出。
Exp8:分別用while 1和while True循環 100 次。
i = 0
while True:
i += 1
if i > 100:
break
復制代碼i = 0
while 1:
i += 1
if i > 100:
break
復制代碼方法一耗時 3.679268300000004s,方法二耗時 3.607847499999991s,性能提升1.94%
將文件存儲在高速緩存中有助於快速恢復功能。Python 支持裝飾器緩存,該緩存在內存中維護特定類型的緩存,以實現最佳軟件驅動速度。我們使用lru_cache裝飾器來為斐波那契函數提供緩存功能,在使用fibonacci遞歸函數時,存在大量的重復計算,例如fibonacci(1)、fibonacci(2)就運行了很多次。而在使用了lru_cache後,所有的重復計算只會執行一次,從而大大提高程序的執行效率。
Exp9:求斐波那契數列。
測試數據:fibonacci(7)。
def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
return fibonacci(n - 1) + fibonacci(n-2)
復制代碼import functools
@functools.lru_cache(maxsize=128)
def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
return fibonacci(n - 1) + fibonacci(n-2)
復制代碼方法一耗時 3.955014900000009s,方法二耗時 0.05077979999998661s,性能提升 98.72%
注意事項:
lru_cache裝飾的函數只會執行一次。list不能作為被lru_cache裝飾的函數的參數。import functools
@functools.lru_cache(maxsize=100)
def demo(a, b):
print('我被執行了')
return a + b
if __name__ == '__main__':
demo(1, 2)
demo(1, 2)
復制代碼我被執行了(執行了兩次
demo(1, 2),卻只輸出一次)
from functools import lru_cache
@lru_cache(maxsize=100)
def list_sum(nums: list):
return sum(nums)
if __name__ == '__main__':
list_sum([1, 2, 3, 4, 5])
復制代碼TypeError: unhashable type: 'list'
functools.lru_cache(maxsize=128, typed=False)的兩個可選參數:
maxsize代表緩存的內存占用值,超過這個值之後,就的結果就會被釋放,然後將新的計算結果進行緩存,其值應當設為 2 的冪。typed若為True,則會把不同的參數類型得到的結果分開保存。.)的使用點運算符(.)用來訪問對象的屬性或方法,這會引起程序使用__getattribute__()和__getattr__()進行字典查找,從而帶來不必要的開銷。尤其注意,在循環當中,更要減少點運算符的使用,應該將它移到循環外處理。
這啟發我們應該盡量使用from ... import ...這種方式來導包,而不是在需要使用某方法時通過點運算符來獲取。其實不光是點運算符,其他很多不必要的運算我們都盡量移到循環外處理。
Exp10:將字符串數組中的小寫字母轉為大寫字母。
測試數組為 oldlist = ['life', 'is', 'short', 'i', 'choose', 'python']。
newlist = []
for word in oldlist:
newlist.append(str.upper(word))
復制代碼newlist = []
upper = str.upper
for word in oldlist:
newlist.append(upper(word))
復制代碼方法一耗時 0.7235491999999795s,方法二耗時 0.5475435999999831s,性能提升 24.33%
for循環取代while循環當我們知道具體要循環多少次時,使用for循環比使用while循環更好。
Exp12:使用for和while分別循環 100 次。
i = 0
while i < 100:
i += 1
復制代碼for _ in range(100):
pass
復制代碼方法一耗時 3.894683299999997s,方法二耗時 1.0198077999999953s,性能提升73.82%
Numba.jit加速計算Numba 可以將 Python 函數編譯碼為機器碼執行,大大提高代碼執行速度,甚至可以接近 C 或 FORTRAN 的速度。它能和 Numpy 配合使用,在 for 循環中或存在大量計算時能顯著地提高執行效率。
Exp12:求從 1 加到 100 的和。
def my_sum(n):
x = 0
for i in range(1, n+1):
x += i
return x
復制代碼from numba import jit
@jit(nopython=True)
def numba_sum(n):
x = 0
for i in range(1, n+1):
x += i
return x
復制代碼方法一耗時 3.7199997000000167s,方法二耗時 0.23769430000001535s,性能提升 93.61%
Numpy矢量化數組矢量化是 NumPy 中的一種強大功能,可以將操作表達為在整個數組上而不是在各個元素上發生。這種用數組表達式替換顯式循環的做法通常稱為矢量化。
在 Python 中循環數組或任何數據結構時,會涉及很多開銷。NumPy 中的向量化操作將內部循環委托給高度優化的 C 和 Fortran 函數,從而使 Python 代碼更加快速。
Exp13:兩個長度相同的序列逐元素相乘。
測試數組:a = [1,2,3,4,5], b = [2,4,6,8,10]
[a[i]*b[i] for i in range(len(a))]
復制代碼import numpy as np
a = np.array([1,2,3,4,5])
b = np.array([2,4,6,8,10])
a*b
復制代碼方法一耗時 0.6706845000000214s,方法二耗時 0.3070132000000001s,性能提升 54.22%
in檢查列表成員若要檢查列表中是否包含某成員,通常使用in關鍵字更快。
Exp14:檢查列表中是否包含某成員。
測試數組:lists = ['life', 'is', 'short', 'i', 'choose', 'python']
def check_member(target, lists):
for member in lists:
if member == target:
return True
return False
復制代碼if target in lists:
pass
復制代碼方法一耗時 0.16038449999999216s,方法二耗時 0.04139250000000061s,性能提升 74.19%
itertools庫迭代itertools是用來操作迭代器的一個模塊,其函數主要可以分為三類:無限迭代器、有限迭代器、組合迭代器。
Exp15:返回列表的全排列。
測試數組:["Alice", "Bob", "Carol"]
def permutations(lst):
if len(lst) == 1 or len(lst) == 0:
return [lst]
result = []
for i in lst:
temp_lst = lst[:]
temp_lst.remove(i)
temp = permutations(temp_lst)
for j in temp:
j.insert(0, i)
result.append(j)
return result
復制代碼import itertools
itertools.permutations(["Alice", "Bob", "Carol"])
復制代碼方法一耗時 3.867292899999484s,方法二耗時 0.3875405000007959s,性能提升 89.98%
擴展:itertools庫詳解:點擊此鏈接
根據上面的測試數據,我繪制了下面這張實驗結果圖,可以更加直觀的看出不同方法帶來的性能差異。
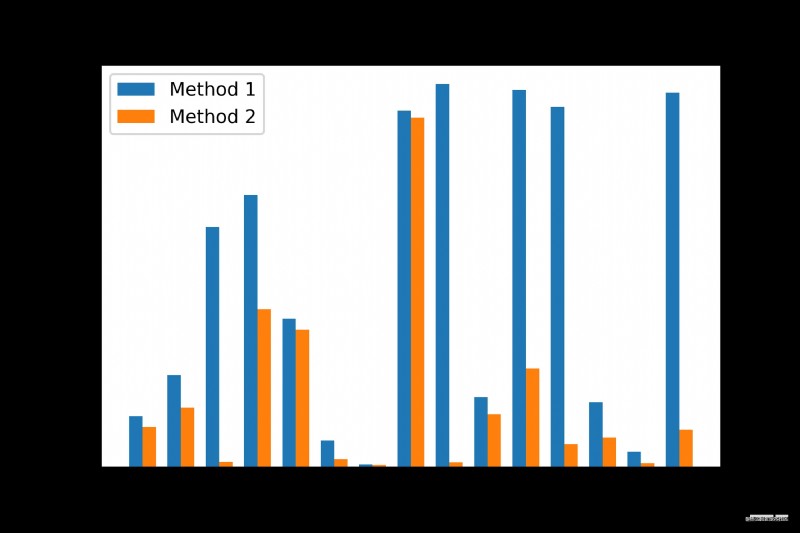
從圖中可以看出,大部分的技巧所帶來的性能增幅還是比較可觀的,但也有少部分技巧的增幅較小(例如編號5、7、8,其中,第 8 條的兩種方法幾乎沒有差異)。
總結下來,我覺得其實就是下面這兩條原則:
內置庫函數由專業的開發人員編寫並經過了多次測試,很多庫函數的底層是用C語言開發的。因此,這些函數總體來說是非常高效的(比如sort()、join()等),自己編寫的方法很難超越它們,還不如省省功夫,不要重復造輪子了,何況你造的輪子可能更差。所以,如果函數庫中已經存在該函數,就直接拿來用。
有很多優秀的第三方庫,它們的底層可能是用 C 和 Fortran 來實現的,像這樣的庫用起來絕對不會吃虧,比如前文提到的 Numpy 和 Numba,它們帶來的提升都是非常驚人的。類似這樣的庫還有很多,比如Cython、PyPy等,這裡我只是拋磚引玉。
其實加快 Python 代碼執行速度的方法還有很多,比如避免使用全局變量、使用最新版本、使用合適的數據結構、利用if條件的惰性等等,我這裡就不一一例舉了。這些方法都需要我們親身去實踐才會有深刻的感受和理解,但最根本的方法就是保持我們對編程的熱情和對最佳實踐的追求,這才是我們能不斷突破自我、勇攀高峰的不竭動力源泉!
感謝大家能看到這裡,如果你覺得這篇內容對你有幫助的話:
點贊支持下吧,讓更多的人也能看到這篇內容。
歡迎在留言區與我分享你的想法,也歡迎你在留言區記錄你的思考過程。
感興趣的話也可以閱讀我之前的一些文章:
 How Python can quickly save pictures in wechat official account articles
How Python can quickly save pictures in wechat official account articles
Python How to quickly save pic
 Problems and solutions of Django cooperating with Python to make requests
Problems and solutions of Django cooperating with Python to make requests
Catalog Django coordination py