【牛客編程題】Python機器學習(入門例題5題)
做題鏈接:https://www.nowcoder.com/exam/oj?page=1&tab=Python篇&topicId=329
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.naive_bayes import GaussianNB
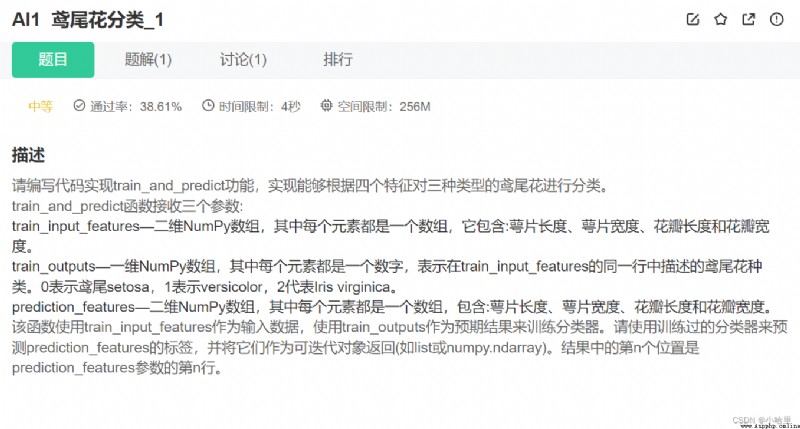
def train_and_predict(train_input_features, train_outputs, prediction_features):
#code start here
clf = GaussianNB();
clf.fit(train_input_features, train_outputs);
y_pred = clf.predict(prediction_features);
return y_pred;
#code end here
iris = datasets.load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target,
test_size=0.3, random_state=0)
y_pred = train_and_predict(X_train, y_train, X_test)
if y_pred is not None:
#code start here
print(metrics.accuracy_score(y_test, y_pred))
#code end here

import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import f1_score, roc_auc_score, accuracy_score
from sklearn.tree import DecisionTreeClassifier
def transform_three2two_cate():
data = datasets.load_iris()
# 其中data特征數據的key為data,標簽數據的key為target
# 需要取出原來的特征數據和標簽數據,移除標簽為2的label和特征數據,返回值new_feat為numpy.ndarray格式特征數據,new_label為對應的numpy.ndarray格式label數據
# 需要注意特征和標簽的順序一致性,否則數據集將混亂
# code start here
index2 = np.where(np.array(data.target)==2)
new_feat = np.delete(data.data, index2, axis = 0)
new_label = np.delete(data.target, index2)
# code end here
return new_feat, new_label
def train_and_evaluate():
data_X, data_Y = transform_three2two_cate()
train_x, test_x, train_y, test_y = train_test_split(data_X, data_Y, test_size=0.2)
# 已經劃分好訓練集和測試集,接下來請實現對數據的訓練
# code start here
dtc = DecisionTreeClassifier(max_depth=3) # 建立決策樹模型
dtc.fit(train_x, train_y) # 訓練模型
y_predict = dtc.predict(test_x) # 預測結果
# code end here
# 注意模型預測的label需要定義為 y_predict,格式為list或numpy.ndarray
print(accuracy_score(y_predict, test_y))
if __name__ == "__main__":
train_and_evaluate()
# 要求執行train_and_evaluate()後輸出為:
# 1、{0,1},代表數據label為0和1
# 2、測試集上的准確率分數,要求>0.95

# -*- coding: UTF-8 -*-
from math import log
import pandas as pd
dataSet = pd.read_csv('dataSet.csv', header=None).values.tolist()
def calcInfoEnt(dataSet):
numEntres = len(dataSet) # 數據集樣本數量
#code start here
labelCounts = {
} # 字典:每一類的樣本數量
for featVec in dataSet:
currentLabel = featVec[-1] # 獲取分類標簽
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1 # 每個類中數據個數統計
infoEnt = 0
for key in labelCounts:
prob = float(labelCounts[key])/numEntres
infoEnt -= prob*log(prob, 2)
return infoEnt
#code end here
#返回值 infoEnt 為數據集的信息熵,表示為 float 類型
if __name__ == '__main__':
print(calcInfoEnt(dataSet))
#輸出為當前數據集的信息熵

# -*- coding: UTF-8 -*-
from math import log
import pandas as pd
dataSet = pd.read_csv('dataSet.csv', header=None).values.tolist()
#給定一個數據集,calcInfoEnt可以用於計算一個數據集的信息熵,可直接調用
#也可不使用,通過自己的方式計算信息增益
def calcInfoEnt(data):
numEntres = len(data)
labelcnt = {
} #用於統計正負樣本的個數
for item in data:
if item[-1] not in labelcnt:
labelcnt[item[-1]] = 0
labelcnt[item[-1]] += 1
infoEnt = 0.0
for item in labelcnt: #根據信息熵的公式計算信息熵
curr_info_entr = float(labelcnt[item]) / numEntres
infoEnt = infoEnt - curr_info_entr * log(curr_info_entr,2)
return infoEnt
#返回值 infoEnt 為數據集的信息熵
#給定一個數據集,用於切分一個子集,可直接用於計算某一特征的信息增益
#也可不使用,通過自己的方式計算信息增益
#dataSet是要劃分的數據集,i 代表第i個特征的索引index
#value對應該特征的某一取值
def create_sub_dataset(dataSet, i, value):
res = []
for item in dataSet:
if item[i] == value:
curr_data = item[:i] + item[i+1:]
res.append(curr_data)
return res
def calc_max_info_gain(dataSet):#計算所有特征的最大信息增益,dataSet為給定的數據集
n = len(dataSet[0])-1 # n 是特征的數量,-1 的原因是最後一列是分類標簽
total_entropy = calcInfoEnt(dataSet)#整體數據集的信息熵
max_info_gain = [0,0]#返回值初始化
#code start here
for i in range(n): # 遍歷特征, 計算特征i的信息增益
featList = [feat[i] for feat in dataSet]
featValues = set(featList)# 獲得所有該特征的數據
newEntropy = 0.0 #計算經驗條件熵
for value in featValues:
subDataset = create_sub_dataset(dataSet,i,value)
prob = len(subDataset)/len(dataSet)
newEntropy += prob*calcInfoEnt(subDataset)
infoGain = total_entropy-newEntropy # 信息增益=信息熵-經驗條件熵
if(infoGain > max_info_gain[1]): # 信息增益取最大
max_info_gain[1] = infoGain
max_info_gain[0] = i
#code end here
return max_info_gain
if __name__ == '__main__':
info_res = calc_max_info_gain(dataSet)
print("信息增益最大的特征索引為:{0},對應的信息增益為{1}".format(info_res[0],info_res[1]))

import numpy as np
import pandas as pd
def generate_data():
datasets = pd.read_csv('dataSet.csv', header=None).values.tolist()
labels = pd.read_csv('labels.csv', header=None).values.tolist()
return datasets, labels
def sigmoid(X):
#補全 sigmoid 函數功能
#code start here
return 1/(1+np.exp(-X)) # h(x)函數,直接計算並返回即可
#code end here
def gradientDescent(dataMatIn, classLabels): # 輸入 datasets,labels
alpha = 0.001 # 學習率,也就是題目描述中的 α
iteration_nums = 100 # 迭代次數,也就是for循環的次數
dataMatrix = np.mat(dataMatIn)
labelMat = np.mat(classLabels).transpose()
m, n = np.shape(dataMatrix) # 返回dataMatrix的大小。m為行數,n為列數。
weight_mat = np.ones((n, 1)) #初始化權重矩陣
#iteration_nums 即為循環的迭代次數
#請在代碼完善部分注意矩陣乘法的維度,使用梯度下降矢量化公式
#code start here
for i in range(iteration_nums):
hx = sigmoid(dataMatrix*weight_mat)
weight_mat = weight_mat-alpha*dataMatrix.transpose()*(hx-labelMat)
return weight_mat
#code end here
if __name__ == '__main__':
dataMat, labelMat = generate_data()
print(gradientDescent(dataMat, labelMat))