【 Niuke programming problem 】Python machine learning ( Introduction examples 5 topic )
Question making link :https://www.nowcoder.com/exam/oj?page=1&tab=Python piece &topicId=329
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.naive_bayes import GaussianNB
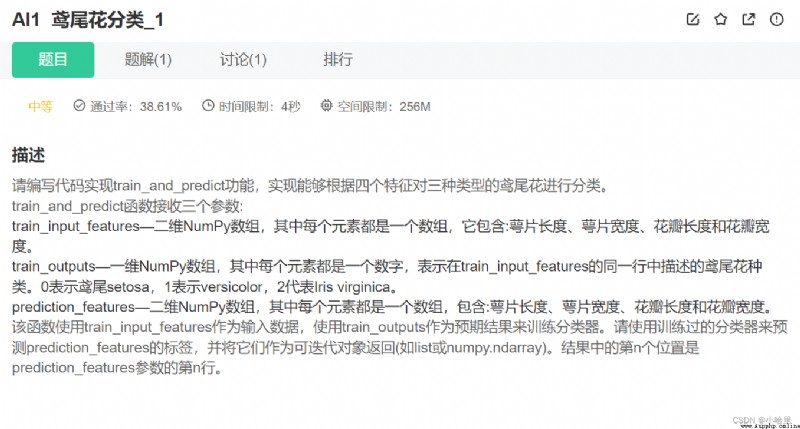
def train_and_predict(train_input_features, train_outputs, prediction_features):
#code start here
clf = GaussianNB();
clf.fit(train_input_features, train_outputs);
y_pred = clf.predict(prediction_features);
return y_pred;
#code end here
iris = datasets.load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target,
test_size=0.3, random_state=0)
y_pred = train_and_predict(X_train, y_train, X_test)
if y_pred is not None:
#code start here
print(metrics.accuracy_score(y_test, y_pred))
#code end here

import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import f1_score, roc_auc_score, accuracy_score
from sklearn.tree import DecisionTreeClassifier
def transform_three2two_cate():
data = datasets.load_iris()
# among data Characteristic data key by data, Label data key by target
# You need to take out the original feature data and label data , Remove the label as 2 Of label And characteristic data , Return value new_feat by numpy.ndarray Format characteristic data ,new_label For the corresponding numpy.ndarray Format label data
# Attention should be paid to the sequence consistency of features and labels , Otherwise, the data set will be confused
# code start here
index2 = np.where(np.array(data.target)==2)
new_feat = np.delete(data.data, index2, axis = 0)
new_label = np.delete(data.target, index2)
# code end here
return new_feat, new_label
def train_and_evaluate():
data_X, data_Y = transform_three2two_cate()
train_x, test_x, train_y, test_y = train_test_split(data_X, data_Y, test_size=0.2)
# The training set and test set have been divided , Next, please realize the training of data
# code start here
dtc = DecisionTreeClassifier(max_depth=3) # Build a decision tree model
dtc.fit(train_x, train_y) # Training models
y_predict = dtc.predict(test_x) # Predicted results
# code end here
# Notice what the model predicts label Need to be defined as y_predict, The format is list or numpy.ndarray
print(accuracy_score(y_predict, test_y))
if __name__ == "__main__":
train_and_evaluate()
# Ask to execute train_and_evaluate() Post output is :
# 1、{0,1}, For data label by 0 and 1
# 2、 Accuracy score on the test set , requirement >0.95

# -*- coding: UTF-8 -*-
from math import log
import pandas as pd
dataSet = pd.read_csv('dataSet.csv', header=None).values.tolist()
def calcInfoEnt(dataSet):
numEntres = len(dataSet) # Number of data set samples
#code start here
labelCounts = {
} # Dictionaries : Number of samples for each category
for featVec in dataSet:
currentLabel = featVec[-1] # Get category labels
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1 # Statistics of the number of data in each class
infoEnt = 0
for key in labelCounts:
prob = float(labelCounts[key])/numEntres
infoEnt -= prob*log(prob, 2)
return infoEnt
#code end here
# Return value infoEnt Is the information entropy of the data set , Expressed as float type
if __name__ == '__main__':
print(calcInfoEnt(dataSet))
# The output is the information entropy of the current data set

# -*- coding: UTF-8 -*-
from math import log
import pandas as pd
dataSet = pd.read_csv('dataSet.csv', header=None).values.tolist()
# Given a dataset ,calcInfoEnt It can be used to calculate the information entropy of a data set , Directly callable
# You may not use , Calculate the information gain in your own way
def calcInfoEnt(data):
numEntres = len(data)
labelcnt = {
} # Used to count the number of positive and negative samples
for item in data:
if item[-1] not in labelcnt:
labelcnt[item[-1]] = 0
labelcnt[item[-1]] += 1
infoEnt = 0.0
for item in labelcnt: # Calculate the information entropy according to the formula of information entropy
curr_info_entr = float(labelcnt[item]) / numEntres
infoEnt = infoEnt - curr_info_entr * log(curr_info_entr,2)
return infoEnt
# Return value infoEnt Is the information entropy of the data set
# Given a dataset , Used to segment a subset , It can be directly used to calculate the information gain of a feature
# You may not use , Calculate the information gain in your own way
#dataSet Is the data set to be divided ,i On behalf of the i An index of features index
#value A value corresponding to a feature
def create_sub_dataset(dataSet, i, value):
res = []
for item in dataSet:
if item[i] == value:
curr_data = item[:i] + item[i+1:]
res.append(curr_data)
return res
def calc_max_info_gain(dataSet):# Calculate the maximum information gain of all features ,dataSet For a given data set
n = len(dataSet[0])-1 # n It's the number of features ,-1 The reason is that the last column is the classification label
total_entropy = calcInfoEnt(dataSet)# Information entropy of the whole data set
max_info_gain = [0,0]# Return value initialization
#code start here
for i in range(n): # Ergodic characteristics , Calculating characteristics i Information gain of
featList = [feat[i] for feat in dataSet]
featValues = set(featList)# Get all the data of this feature
newEntropy = 0.0 # Calculate empirical conditional entropy
for value in featValues:
subDataset = create_sub_dataset(dataSet,i,value)
prob = len(subDataset)/len(dataSet)
newEntropy += prob*calcInfoEnt(subDataset)
infoGain = total_entropy-newEntropy # Information gain = Information entropy - Empirical condition entropy
if(infoGain > max_info_gain[1]): # Maximum information gain
max_info_gain[1] = infoGain
max_info_gain[0] = i
#code end here
return max_info_gain
if __name__ == '__main__':
info_res = calc_max_info_gain(dataSet)
print(" The feature index with the largest information gain is :{0}, The corresponding information gain is {1}".format(info_res[0],info_res[1]))

import numpy as np
import pandas as pd
def generate_data():
datasets = pd.read_csv('dataSet.csv', header=None).values.tolist()
labels = pd.read_csv('labels.csv', header=None).values.tolist()
return datasets, labels
def sigmoid(X):
# completion sigmoid The functionality
#code start here
return 1/(1+np.exp(-X)) # h(x) function , Directly calculate and return
#code end here
def gradientDescent(dataMatIn, classLabels): # Input datasets,labels
alpha = 0.001 # Learning rate , That is, in the Title Description α
iteration_nums = 100 # The number of iterations , That is to say for Number of cycles
dataMatrix = np.mat(dataMatIn)
labelMat = np.mat(classLabels).transpose()
m, n = np.shape(dataMatrix) # return dataMatrix Size .m Is the number of rows ,n Is the number of columns .
weight_mat = np.ones((n, 1)) # Initializes the weight matrix
#iteration_nums That is, the number of iterations of the loop
# Please pay attention to the dimension of matrix multiplication in the code improvement section , Use gradient descent vectorization formula
#code start here
for i in range(iteration_nums):
hx = sigmoid(dataMatrix*weight_mat)
weight_mat = weight_mat-alpha*dataMatrix.transpose()*(hx-labelMat)
return weight_mat
#code end here
if __name__ == '__main__':
dataMat, labelMat = generate_data()
print(gradientDescent(dataMat, labelMat))