參考書目:《深入淺出Pandas:利用Python進行數據處理與分析》
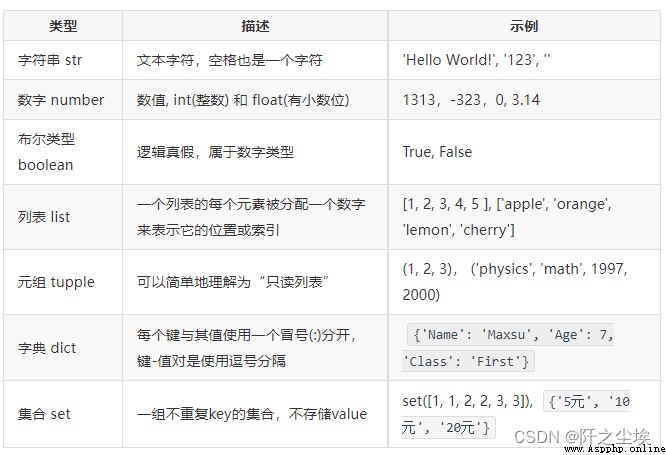
學習pandas之前,我們要了解一下Python的基礎數據結構,還有pandas的底層庫numpy的數據結構(數組矩陣之類的),然後才是pandas的兩種基礎數據結構,Series和DataFrame。
# 用科學計數法賦值
n = 1e4
n # 10000.0
m = 2e-2
m # 0.02
a = 10
b = 21
# 數值計算
a + b # 31
a - b # -11
a * b # 210
b / a # 2.1
a ** b # 表示 10 的 21 次冪
b % a # 1 (取余)
# 地板除 - 操作數的除法,其結果是刪除小數點後的商數
# 但如果其中一個操作數為負數,則結果將被保留,即從零(向負無窮大)捨去
9//2 # 4
9.0//2.0 # 4.0
-11//3 # -4
-11.0//3 # -4.0可以用來判斷變量的類型
isinstance(123,int)
isinstance([123],list)切片
#切片
var = 'Hello World!'
# 按索引取部分內容, 索引從0開始, 左必須小於右
# 支持字符、列表、元組
var[0] # 'H'
# 從右開始索引從 -1 開始
var[-1] # '!'
var[-3:-1] # 'ld'
var[1:7] # 'ello W'(有個空格,不包含最後一位)
var[6:] # 'World!' (前後省略按開頭結尾)
var[:] # 'Hello World!'(相當於復制)
var[0:5:2] # 'Hlo'(2為步長,2的倍數取)
var[1:7:3] # 'ello W‘ -> 'eo'
var[::-1] # !dlroW olleH 實現反轉字符功能轉義字符
print("一行\n另一行") # 換行
print("一格\t另一格") # 制表
print("我是\b中國人") # 退格,會刪除「是」
print('I \'m boy.') # 引號,雙引號同
print("看到反斜槓了麼?\\") # 反斜槓分割和連接
len('good') # 4 字符的長度
'good'.replace('g', 'G') # 'Good' 替換字符
'山-水-風-雨'.split('-') # ['山', '水', '風', '雨'] 用指定字符分隔,默認空格
'好山好水好風光'.split('好') # ['', '山', '水', '風光']
'-'.join(['山','水','風','雨']) # '山-水-風-雨'
'和'.join(['詩', '遠方']) # '詩和遠方'
# 分割連接
# 按換行分隔,默認(False)不保留換行符
'Good\nbye\nbye'.splitlines(True) # ['Good\n', 'bye\n', 'bye']
# 去空格
'Good bye'.strip('e') # 去掉首尾指定字符, 默認去空格
' Good bye '.lstrip() # 'Good bye ' 去掉左邊空格
' Good bye '.rstrip() # ' Good bye'去掉右邊空格字母大小寫
good'.upper() # 'GOOD' 全轉大寫
'GOOD'.lower() # 'good' 全轉小寫
'Good Bye'.swapcase() # 'gOOD bYE' 大小寫互換
'good'.capitalize() # 'Good' 首字母轉大寫
'good'.islower() # True 是否全是小寫
'good'.isupper() # False 是否全是大寫
'good bYe'.title() # 'Good Bye' 所有的單詞首字母轉為大寫,且其他字母轉小寫
'Good Bye'.istitle() # True 檢測所有的單詞首字母是否為大寫,且其他字母為小寫索引填充等操作
'我和你'.endswith('你') # True 是否以指定字符結尾
'我和你'.startswith('你') # False 是否以指定字符開始
' and你'.isspace() # False 是否全是空白字符
'good'.center(10, '*') # '***good***' 字符居中, 其余用指定字符填充, 共多少位
'good'.ljust(10, '-') # 'good------' 左對齊,默認是空格補全
'good'.rjust(10, '-') # '------good' 右對齊
'good'.count('o') # 2 指定字符在字符中的數量
'good'.count('o', 2, 3) # 1 在索引范圍內字符出現的數量
'3月'.zfill(3) # '03月' 指定長寬,不夠前邊補 0
max('good') # 'o' 按最大字母順序最大的字母
min('good') # 'd' 最小的字母
'Good Good Study'.find('y') # 14 返回指,定字符第一次出現的索引, 如果不包含返回-1
'Good Good Study'.find('o', 3) # 6 指定開始位第一次出現的索引, 如果不包返回-1
'Good Good Study'.find('o', 2, 7) # 2 指定區間內第一次出現的索引, 如果不包返回-1
'Good Good Study'.find('up') # -1 不包含返回-1
rfind(str, beg=0,end=len(string)) # 從右開始的 find()
'Good Bye'.index('d') # 3 指定字符第一個索引
'Good Bye'.index('s') # 找不到會 ValueError 錯誤, 可以先 in 去判斷是否包含
rindex(str, beg=0, end=len(string)) # 從右開始的 index()
字符串格式化
# 格式化, 此處推薦 f-string: https://www.gairuo.com/p/python-format-string4
name='tom'
f'{name}是好人' # 'tom是好人' 推薦此方法, name = 'tom'
'%s %s' % ('age', 18) # 'age 18'
'{}, {}'.format(18, 'age') # '18 age'
'{0}, {1}, {0}'.format('age', 18) # 'age, 18, age'
'{name}: {age}'.format(age=18, name='tom') # 'tom: 18'判斷
a,b,c=0,1,2
a and b # 0 a 為假返回假的值
b and a # 0 b為真,返回a的值
a or b # 1 輸出為真值的結果
a and b or c # 2
a and (b or c) # 0 用類似數學中的括號提高運算優先級
# not 的注意事項
not a # True
not a == b # True
not (a == b) # True 同上邏輯
#a == not b # !這個是錯誤的語法, 正確如下:
a == (not b) # True
# and 優先級高 'a' 為真,返回 'b', '' or 'b' 返回 'b'
'' or 'a' and 'b' # 'b'賦值運算
x = a or b # 哪個為真就就將值賦值到 x
x = a and b # 哪個為假就將值賦到 x
x = not a # 將結果賦值給 x, False
bool(None) # False
bool(0) # False
bool([]) # False
bool(()) # False生成列表
# 生成列表
y = '1345'
list(y) # ['1', '3', '4', '5'] 將列表轉換成列表
list('刮風那天,我試過握著你手')# ['刮', '風', '那', '天', ',', '我', '試', '過', '握', '著', '你', '手']
# 元組
z = ('a', 'b', 'c')
list(z) # ['a', 'b', 'c'] 將元組轉換成列表
# 字典
d = {'Name': 'Tom', 'Age': 7, 'Class': 'First'}
list(d) # ['Name', 'Age', 'Class'] 字典 key 轉成列表
list(d.values()) # ['Tom', 7, 'First'] 字典 value 轉成列表
# 字典鍵值對(一個元組)轉成列表
list(d.items()) # [('Name', 'Tom'), ('Age', 7), ('Class', 'First')]
#列表操作
['a', 'b'] + ['c', 'd'] # ['a', 'b', 'c', 'd'] 拼接
['a', 'b'] * 2 # ['a', 'b', 'a', 'b''] 復制常見用法
a = [1, 2, 3]
len(a) # 3 元素個數
max(a) # 3 最大值
min(a) # 1 最小值
sum(a) # 6 求和
a.index(2) # 1 指定元素位置
a.count(1) # 1 求元素的個數
for i in a: print(i) # 迭代元素
sorted(a) # 返回一個排序的列表,但不改變原列表
any(a) # True 是否至少有一個元素為真
all(a) # True 是否所有元素為真增加刪除
a = [1, 2, 3]
a.append(4) # a: [1, 2, 3, 4] 增加一個元素
a.pop() # 每執行一次刪除最後一個元素
a.extend([9,8]) # a: [1, 2, 3, 9, 8] # 和其他列表合並
a.insert(1, 'a') # a: [1, 'a', 2, 3] 指定索引位插入元素
a.remove('a') # 刪除第一個指定元素
a.clear() # [] 清空排序
#排序 立即修改
a.reverse() # 反轉順序
a.sort() # 排序 立即修改
a.sort(reverse=True) # 反序
a.sort(key=abs) # 傳入函數關鍵字作為排序規則列表解析式
# 將一個可迭代的對象展開形成一個列表
[i for i in range(5)] # [0, 1, 2, 3, 4]
# 可以將結果進行處理
['第'+str(i) for i in range(5)] # ['第0', '第1', '第2', '第3', '第4']
# 可以進行條件篩選, 實現取偶數
[i for i in range(5) if i%2==0]
# 拆開字符, 過濾空格,全變成大寫
[i.upper() for i in 'Hello world' if i != ' ']
# ['H', 'E', 'L', 'L', 'O', 'W', 'O', 'R', 'L', 'D']
# 條件分支
data= ['good','bad','bad','good','bad']
[1 if x == 'good' else 0 for x in data] # [1, 0, 0, 1, 0]生成元組
a = () # 空元組
a = (1, ) # 只有一個元素
a = (1, 2, 3) # 定義一個元組
tuple() # 生成空元組
tuple('hello') # ('h', 'e', 'l', 'l', 'o')
type(a) # tuple 元素檢測
# 沒有括號也可以定義一個元組
a = 1,23,4,56 # a: (1, 23, 4, 56)
a = 1, # a: (1, )元組解包
x = (1,2,3,4,5)
a, *b = x # a 占第一個,剩余的組成列表全給 b
# a -> 1
# b -> [2, 3, 4, 5]
# a, b -> (1, [2, 3, 4, 5])
a, *b, c = x # a 占第一個,c 占最後一個, 剩余的組成列表全給 b
# a -> 1
# b -> [2, 3, 4]
# c -> 5
# a, b, c -> (1, [2, 3, 4], 5)生成字典
d = {} # 定義空字典
d = dict() # 定義空字典
d = {'a': 1, 'b': 2, 'c': 3}
d = {'a': 1, 'a': 1, 'a': 1} # { 'a': 1} key 不能重復, 取最後一個
d = {'a': 1, 'b': {'x': 3}} # 嵌套字典
d = {'a': [1,2,3], 'b': [4,5,6]} # 嵌套列表
# 以下均可定義如下結果
# {'name': 'Tom', 'age': 18, 'height': 180}
d = dict(name='Tom', age=18, height=180)
d = dict([('name', 'Tom'), ('age', 18), ('height', 180)])
d = dict(zip(['name', 'age', 'height'], ['Tom', 18, 180]))訪問
d['name'] # 'Tom' 獲取鍵的值
d['age'] = 20 # 將 age 的值更新為 20
d['Female'] = 'man' # 增加屬性
d.get('height', 180) # 180
# 嵌套取值
d = {'a': {'name': 'Tom', 'age':18}, 'b': [4,5,6]}
d['b'][1] # 5
d['a']['age'] # 18
# 注意這不是切片操作,訪問鍵返回值
d = {0: 10, 2: 20}
d[0] # 10增加刪除訪問等
d.pop('name') # 'Tom' 刪除指定 key
d.popitem() # 隨機刪除某一項
del d['name'] # 刪除鍵值對
d.clear() # 清空字典
# 按類型訪問,可迭代
d.keys() # 列出所有 key
d.values() # 列出所有 值
d.items() # 列出所有值對元組(k, v)可迭代 for k,v in d.items():
# 操作
d.setdefault('a', 3) # 插入一個鍵,給字默認值, 不指定為 None
d1.update(dict2) # 將字典 dict2 的鍵值對添加到字典 dict
d.get('math', 100) # 對於鍵(key)存在則返回其對應值,如果鍵不在字典中,則返回默認值
d2 = d.copy() # 深拷貝, d 變化不影響 d2
# update 更新方式
d = {}
d.update(a=1)
d.update(c=2, d=3)
d # {'a': 1, 'c': 2, 'd': 3}常見操作
d = {'a': 1, 'b': 2, 'c': 3}
max(d) # 'c' 最大的 k
min(d) # 'a' 最小的 k
len(d) # 3 字典的長度
str(d) # "{'a': 1, 'b': 2, 'c': 3}" 字符串形式
any(d) # True 只要一個鍵為 True
all(d) # True 所有鍵都為 True
sorted(d) # ['a', 'b', 'c'] 所有key當列表排序解析式
d = {'ABCDE'[i]: i*10 for i in range(1,5)}
# {'B': 10, 'C': 20, 'D': 30, 'E': 40}
# 鍵值互換
d = {'name': 'Tom', 'age': 18, 'height': 180}
{v:k for k,v in d.items()}
# {'Tom': 'name', 18: 'age', 180: 'height'}邏輯分支
#邏輯分支
route = {True: 'case1', False: 'case2'} # 定義路由
route[7>6] # 'case1' 傳入結果為布爾的變量、表達式、函數調用
# 定義計算方法
cal = {'+': lambda x,y: x+y, '*':lambda x,y: x*y}
cal['*'](4,9) # 36 使用s = {'5元', '10元', '20元'} # 定義集合
s = set() # 空集合
s = set([1,2,3,4,5]) # {1, 2, 3, 4, 5} 使用列表定義
s = {1, True, 'a'}
s = {1, 1, 1} # {1} 去重
type(s) # set 類型檢測增加刪除
#添加刪除
s = {'a', 'b', 'c'}
s.add(2) # {2, 'a', 'b', 'c'}
s.update([1,3,4]) # {1, 2, 3, 4, 'a', 'b', 'c'}
s = {'a', 'b', 'c'}
s.remove('a') # {'b', 'c'} 刪除不存在的會報錯
s.discard('3') # 刪除一個元素,無則忽略不報錯
s.clear() # set() 清空數學集合運算
s1 = {1,2,3}
s2 = {2,3,4}
s1 & s2 # {2, 3} 交集
s1.intersection(s2) # {2, 3} 交集
s1.intersection_update(s2) # {2, 3} 交集, 會覆蓋 s1
s1 | s2 # {1, 2, 3, 4} 並集
s1.union(s2) # {1, 2, 3, 4} 並集
s1.difference(s2) # {1} 差集
s1.difference_update(s2) # {1} 差集, 會覆蓋 s1
s1.symmetric_difference(s2) # {1, 4} 交集之外
s1.isdisjoint(s2) # False 是否沒有交集
s1.issubset(s2) # False s2 是否 s1 的子集
s1.issuperset(s2) # False s1 是否 s2 的超集, 即 s1 是否包含 s2 的所有元素數組生成
import numpy as np
np.arange(3)
# array([0, 1, 2])
np.arange(3.0)
# array([ 0., 1., 2.])
np.arange(3,7)
# array([3, 4, 5, 6])
np.arange(3,7,2)
# array([3, 5])
np.arange(3,4,.2)
# array([3. , 3.2, 3.4, 3.6, 3.8])
# 區間內等差數據 指定數量
np.linspace(2.0, 3.0, num=5)
# array([2. , 2.25, 2.5 , 2.75, 3. ])
# 右開區間(不包含右值)
np.linspace(2.0, 3.0, num=5, endpoint=False)
# array([2. , 2.2, 2.4, 2.6, 2.8])
# (數組, 樣本之間的間距)
np.linspace(2.0, 3.0, num=5, retstep=True)#(array([2. , 2.25, 2.5 , 2.75, 3. ]), 0.25)全是0或1數組
#創建值為0的數組
np.zeros(6)#6個浮點0. #行向量
np.zeros((2,3,4),dtype=int)#指定形狀的0矩陣
np.ones((2,3,4)) #一矩陣
np.empty((3,4)) #空(0)矩陣
#結構相同的0矩陣
np.arange(8).reshape(1,-1).shape #(1, 8)
np.arange(8).shape #(8,)
np.zeros_like(np.arange(8).reshape(-1,1))#列矩陣 (8,1)
np.ones_like(np.arange(8).reshape(4,2))
np.empty_like(np.arange(8).reshape(2,2,2))隨機數組
np.random.randn(6,4)#生成6*4的隨機矩陣,標准正態分布浮點
np.random.random(size=(6,4))#生成6*4的隨機矩陣,0-1均勻分布浮點
np.random.randint(1,7,size=(6,4))#指定范圍指定形狀,整數常見操作
a=np.linspace(2.0, 3.0, num=5) #array([2. , 2.25, 2.5 , 2.75, 3. ])
a.max()
a.min()
a.sum()
a.std()
a.all()
a.any()
a.cumsum() #累計求和
np.sin(a)
np.log(a)Pandas基礎的數據結構就兩種,一種就是類似Excel表的二維數據框DataFrame,第二種就是數據框的一列,就是一條向量,叫Series。
數據框DataFrame生成
import pandas as pd
df = pd.DataFrame({'國家': ['中國', '美國', '日本'],
'地區': ['亞洲', '北美', '亞洲'],
'人口': [14.33, 3.29, 1.26],
'GDP': [14.22, 21.34, 5.18],})
df
df2 = pd.DataFrame({'A': 1.,
'B': pd.Timestamp('20130102'),
'C': pd.Series(1, index=list(range(4)), dtype='float32'),
'D': np.array([3] * 4, dtype='int32'),
'E': pd.Categorical(["test", "train", "test", "train"]),
'F': 'foo'})
df2.B.dtype ##dtype('<M8[ns]')
df2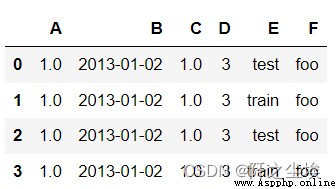
pd.DataFrame.from_dict({'國家':['中國','美國','日本'],'人口':[13.9,3.28,1.26]}) #字典生成
pd.DataFrame.from_records([('中國','美國','日本'),(13.9,3.28,1.26)]).T #列表數組生成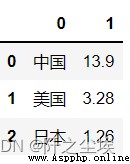
Series常見用法
# 由索引為 a、b.. , 五個隨機浮點數數組組成
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
s.index # 查看索引
s = pd.Series(np.random.randn(5)) # 未指定索引
pd.Series(5., index=['a', 'b', 'c', 'd', 'e'])
s = pd.Series([1,2,3,4,5,6,7,8])
s[3] # 類似列表切片
s[2:]
s.median() # 平均值,包括其他的數學函數
s[s > s.median()] # 篩選大於平均值的內容
s[[1, 2, 1]] # 指定索引的內容,括號的列表是索引
s.dtype # 數據類型
s.array # 返回值的數列
s.to_numpy() # 轉為 numpy 的 ndarray
3 in s # 邏輯運算,檢測索引
s.to_numpy()==s.values #[ True, True, True, True, True, True, True, True])s = pd.Series([1,2,3,4], name='數字')
s.add(1) # 每個元素加1 abs()
s.add_prefix(3) # 給索引前加個3,升位30,31,32,34
s.add_suffix(4) # 同上,在後增加04,14,24,34
s.sum() # 總和
s.count() # 數量,長度
s.agg('std') # 聚合,僅返回標准差, 與 s.std() 相同
s.agg(['min', 'max']) # 聚合,返回最大最小值
s2 = s.rename("number") # 修改名稱
s.align(s2) # 聯接
s.any() # 是否有為假的
s.all() # 是否全是真
s.append(s2) # 追加另外一個 Series
s.apply(lambda x:x+1) # 應用方法
s.empty # 是否為空
s3 = s.copy() # 深拷貝判斷類型
pd.api.types.is_bool_dtype(s)
pd.api.types.is_categorical_dtype(s)
pd.api.types.is_datetime64_any_dtype(s)
pd.api.types.is_datetime64_ns_dtype(s)
pd.api.types.is_datetime64_dtype(s)
pd.api.types.is_float_dtype(s)
pd.api.types.is_int64_dtype(s)
pd.api.types.is_numeric_dtype(s)
pd.api.types.is_object_dtype(s)
pd.api.types.is_string_dtype(s)
pd.api.types.is_timedelta64_dtype(s)
pd.api.types.is_bool_dtype(s)pandas數據怎麼讀取,切片,篩選,畫圖等操作後面每一章再詳細介紹