Bibliography :《 Explain profound theories in simple language Pandas: utilize Python Data processing and analysis 》
Study pandas Before , We need to know something about Python The basic data structure of , also pandas The bottom of the library numpy Data structure of ( Array matrix and so on ), Then it is pandas Two basic data structures ,Series and DataFrame.
# Assign values by scientific counting
n = 1e4
n # 10000.0
m = 2e-2
m # 0.02
a = 10
b = 21
# Numerical calculation
a + b # 31
a - b # -11
a * b # 210
b / a # 2.1
a ** b # Express 10 Of 21 The next power
b % a # 1 ( Remainder )
# Floor removal - Division of operands , The result is to delete the quotient after the decimal point
# But if one of the operands is negative , The results will be preserved , From zero ( To negative infinity ) Give up
9//2 # 4
9.0//2.0 # 4.0
-11//3 # -4
-11.0//3 # -4.0It can be used to judge the type of variables
isinstance(123,int)
isinstance([123],list)section
# section
var = 'Hello World!'
# Take part of the content according to the index , Index from 0 Start , Left must be less than right
# Support for characters 、 list 、 Tuples
var[0] # 'H'
# Start from the right and index from -1 Start
var[-1] # '!'
var[-3:-1] # 'ld'
var[1:7] # 'ello W'( There is a space , Does not include the last )
var[6:] # 'World!' ( Omit before and after, and end with the beginning )
var[:] # 'Hello World!'( Equivalent to replication )
var[0:5:2] # 'Hlo'(2 Step length ,2 Multiple of )
var[1:7:3] # 'ello W‘ -> 'eo'
var[::-1] # !dlroW olleH Realize the function of reversing characters Escape character
print(" a line \n Another line ") # Line break
print(" One grid \t Another space ") # Tabulation
print(" I am a \b Chinese ") # Backspace , Will delete 「 yes 」
print('I \'m boy.') # quotes , Double quotation marks are the same as
print(" See the backslash ?\\") # The backslash Divide and connect
len('good') # 4 The length of the characters
'good'.replace('g', 'G') # 'Good' Replace character
' mountain - water - wind - rain '.split('-') # [' mountain ', ' water ', ' wind ', ' rain '] Separate... With the specified character , Default space
' Good mountains, good water, good scenery '.split(' good ') # ['', ' mountain ', ' water ', ' scenery ']
'-'.join([' mountain ',' water ',' wind ',' rain ']) # ' mountain - water - wind - rain '
' and '.join([' The poem ', ' distance ']) # ' Poetry and the distance '
# Split connection
# Separate by newline , Default (False) Line breaks are not retained
'Good\nbye\nbye'.splitlines(True) # ['Good\n', 'bye\n', 'bye']
# Go to space
'Good bye'.strip('e') # Remove the first and last specified characters , Default to space
' Good bye '.lstrip() # 'Good bye ' Take out the space on the left
' Good bye '.rstrip() # ' Good bye' Remove the space on the right Letter case
good'.upper() # 'GOOD' All to capital
'GOOD'.lower() # 'good' All to lowercase
'Good Bye'.swapcase() # 'gOOD bYE' Case interchangeability
'good'.capitalize() # 'Good' Capitalize the initial
'good'.islower() # True Is it all lowercase
'good'.isupper() # False Is it all in capitals
'good bYe'.title() # 'Good Bye' All words are capitalized , And other letters turn lowercase
'Good Bye'.istitle() # True Check whether the first letter of all words is capitalized , And the other letters are lowercase Index filling and other operations
' You and me '.endswith(' you ') # True Whether to end with the specified character
' You and me '.startswith(' you ') # False Whether to start with the specified character
' and you '.isspace() # False Whether it's all white space
'good'.center(10, '*') # '***good***' Center characters , The rest are filled with specified characters , How many people are there
'good'.ljust(10, '-') # 'good------' Align left , The default is space completion
'good'.rjust(10, '-') # '------good' Right alignment
'good'.count('o') # 2 Specify the number of characters in characters
'good'.count('o', 2, 3) # 1 The number of characters appearing in the index range
'3 month '.zfill(3) # '03 month ' Specify the length and width , Not enough for the front 0
max('good') # 'o' The largest letter in the largest alphabetical order
min('good') # 'd' The smallest letter
'Good Good Study'.find('y') # 14 Return refers to , The index of the first occurrence of the fixed character , If return is not included -1
'Good Good Study'.find('o', 3) # 6 Specify the index of the first occurrence of the start bit , If the package does not return -1
'Good Good Study'.find('o', 2, 7) # 2 The index of the first occurrence in the specified interval , If the package does not return -1
'Good Good Study'.find('up') # -1 Does not include return -1
rfind(str, beg=0,end=len(string)) # From the right find()
'Good Bye'.index('d') # 3 Specify the first index of the character
'Good Bye'.index('s') # Can't find meeting ValueError error , You can start with in To determine whether it contains
rindex(str, beg=0, end=len(string)) # From the right index()
String formatting
# format , Recommended here f-string: https://www.gairuo.com/p/python-format-string4
name='tom'
f'{name} Good people. ' # 'tom Good people. ' Recommend this method , name = 'tom'
'%s %s' % ('age', 18) # 'age 18'
'{}, {}'.format(18, 'age') # '18 age'
'{0}, {1}, {0}'.format('age', 18) # 'age, 18, age'
'{name}: {age}'.format(age=18, name='tom') # 'tom: 18'Judge
a,b,c=0,1,2
a and b # 0 a Returns a false value for false
b and a # 0 b It's true , return a Value
a or b # 1 The output is the result of true value
a and b or c # 2
a and (b or c) # 0 Use parentheses similar to those in mathematics to improve the operation priority
# not Precautions for
not a # True
not a == b # True
not (a == b) # True Ditto logic
#a == not b # ! This is the wrong syntax , Correct as follows :
a == (not b) # True
# and High priority 'a' It's true , return 'b', '' or 'b' return 'b'
'' or 'a' and 'b' # 'b'The assignment operation
x = a or b # Which is true assigns the value to x
x = a and b # Which is false will be assigned to x
x = not a # Assign the result to x, False
bool(None) # False
bool(0) # False
bool([]) # False
bool(()) # FalseGenerate list
# Generate list
y = '1345'
list(y) # ['1', '3', '4', '5'] Convert list to list
list(' On a windy day , I tried to hold your hand ')# [' Scratch ', ' wind ', ' that ', ' God ', ',', ' I ', ' try ', ' too ', ' hold ', ' the ', ' you ', ' hand ']
# Tuples
z = ('a', 'b', 'c')
list(z) # ['a', 'b', 'c'] Converts a tuple to a list
# Dictionaries
d = {'Name': 'Tom', 'Age': 7, 'Class': 'First'}
list(d) # ['Name', 'Age', 'Class'] Dictionaries key Convert to list
list(d.values()) # ['Tom', 7, 'First'] Dictionaries value Convert to list
# Dictionary key value pairs ( A tuple ) Convert to list
list(d.items()) # [('Name', 'Tom'), ('Age', 7), ('Class', 'First')]
# The list of operations
['a', 'b'] + ['c', 'd'] # ['a', 'b', 'c', 'd'] Splicing
['a', 'b'] * 2 # ['a', 'b', 'a', 'b''] Copy Common use
a = [1, 2, 3]
len(a) # 3 Element number
max(a) # 3 Maximum
min(a) # 1 minimum value
sum(a) # 6 Sum up
a.index(2) # 1 Specify the element location
a.count(1) # 1 Find the number of elements
for i in a: print(i) # Iterative elements
sorted(a) # Returns a sorted list , But do not change the original list
any(a) # True Whether at least one element is true
all(a) # True Whether all elements are true Add delete
a = [1, 2, 3]
a.append(4) # a: [1, 2, 3, 4] Add an element
a.pop() # Delete the last element every time
a.extend([9,8]) # a: [1, 2, 3, 9, 8] # Merge with other lists
a.insert(1, 'a') # a: [1, 'a', 2, 3] Specify the index bit to insert the element
a.remove('a') # Delete the first specified element
a.clear() # [] Empty Sort
# Sort Modify... Immediately
a.reverse() # Inversion order
a.sort() # Sort Modify... Immediately
a.sort(reverse=True) # trans
a.sort(key=abs) # Pass in function keywords as sorting rules List parsing
# Expand an iteratable object to form a list
[i for i in range(5)] # [0, 1, 2, 3, 4]
# The results can be processed
[' The first '+str(i) for i in range(5)] # [' The first 0', ' The first 1', ' The first 2', ' The first 3', ' The first 4']
# You can filter by criteria , Achieve even numbers
[i for i in range(5) if i%2==0]
# Open characters , Filter space , All in capitals
[i.upper() for i in 'Hello world' if i != ' ']
# ['H', 'E', 'L', 'L', 'O', 'W', 'O', 'R', 'L', 'D']
# Conditional branch
data= ['good','bad','bad','good','bad']
[1 if x == 'good' else 0 for x in data] # [1, 0, 0, 1, 0]Generate tuples
a = () # An empty tuple
a = (1, ) # There's only one element
a = (1, 2, 3) # Define a tuple
tuple() # Generate empty tuple
tuple('hello') # ('h', 'e', 'l', 'l', 'o')
type(a) # tuple Element detection
# You can define a tuple without parentheses
a = 1,23,4,56 # a: (1, 23, 4, 56)
a = 1, # a: (1, )Tuple unpacking
x = (1,2,3,4,5)
a, *b = x # a First , The rest of the composition list is all for b
# a -> 1
# b -> [2, 3, 4, 5]
# a, b -> (1, [2, 3, 4, 5])
a, *b, c = x # a First ,c Last , The rest of the composition list is all for b
# a -> 1
# b -> [2, 3, 4]
# c -> 5
# a, b, c -> (1, [2, 3, 4], 5)Generate Dictionary
d = {} # Define an empty dictionary
d = dict() # Define an empty dictionary
d = {'a': 1, 'b': 2, 'c': 3}
d = {'a': 1, 'a': 1, 'a': 1} # { 'a': 1} key Can't repeat , Take the last one
d = {'a': 1, 'b': {'x': 3}} # Nested Dictionary
d = {'a': [1,2,3], 'b': [4,5,6]} # Nested list
# The following results can be defined
# {'name': 'Tom', 'age': 18, 'height': 180}
d = dict(name='Tom', age=18, height=180)
d = dict([('name', 'Tom'), ('age', 18), ('height', 180)])
d = dict(zip(['name', 'age', 'height'], ['Tom', 18, 180]))visit
d['name'] # 'Tom' Gets the value of the key
d['age'] = 20 # take age The value of is updated to 20
d['Female'] = 'man' # Attribute added
d.get('height', 180) # 180
# Nested values
d = {'a': {'name': 'Tom', 'age':18}, 'b': [4,5,6]}
d['b'][1] # 5
d['a']['age'] # 18
# Note that this is not a slicing operation , Access key return value
d = {0: 10, 2: 20}
d[0] # 10Add delete access
d.pop('name') # 'Tom' Delete the specified key
d.popitem() # Randomly delete an item
del d['name'] # Delete key value pair
d.clear() # Empty dictionary
# Access by type , Can the iteration
d.keys() # List all key
d.values() # List all value
d.items() # List all value pairs tuples (k, v) Can the iteration for k,v in d.items():
# operation
d.setdefault('a', 3) # Insert a key , Give the word default , Not specified as None
d1.update(dict2) # Dictionary dict2 Key value pairs added to dictionary dict
d.get('math', 100) # For keys (key) If it exists, its corresponding value is returned , If the key is not in the dictionary , Returns the default value
d2 = d.copy() # Deep copy , d Change doesn't affect d2
# update Update the way
d = {}
d.update(a=1)
d.update(c=2, d=3)
d # {'a': 1, 'c': 2, 'd': 3}Common operations
d = {'a': 1, 'b': 2, 'c': 3}
max(d) # 'c' maximal k
min(d) # 'a' The smallest k
len(d) # 3 The length of the dictionary
str(d) # "{'a': 1, 'b': 2, 'c': 3}" String form
any(d) # True As long as one key is True
all(d) # True All keys are True
sorted(d) # ['a', 'b', 'c'] all key When the list is sorted Analytic formula
d = {'ABCDE'[i]: i*10 for i in range(1,5)}
# {'B': 10, 'C': 20, 'D': 30, 'E': 40}
# Key exchange
d = {'name': 'Tom', 'age': 18, 'height': 180}
{v:k for k,v in d.items()}
# {'Tom': 'name', 18: 'age', 180: 'height'}The branch of logic
# The branch of logic
route = {True: 'case1', False: 'case2'} # Define routes
route[7>6] # 'case1' Pass in a variable with a boolean result 、 expression 、 Function call
# Define the calculation method
cal = {'+': lambda x,y: x+y, '*':lambda x,y: x*y}
cal['*'](4,9) # 36 Use s = {'5 element ', '10 element ', '20 element '} # Define a collection
s = set() # Empty set
s = set([1,2,3,4,5]) # {1, 2, 3, 4, 5} Use list definitions
s = {1, True, 'a'}
s = {1, 1, 1} # {1} duplicate removal
type(s) # set Type detection Add delete
# Add delete
s = {'a', 'b', 'c'}
s.add(2) # {2, 'a', 'b', 'c'}
s.update([1,3,4]) # {1, 2, 3, 4, 'a', 'b', 'c'}
s = {'a', 'b', 'c'}
s.remove('a') # {'b', 'c'} Deleting a nonexistent will result in an error
s.discard('3') # Delete an element , If nothing, ignore it and report no error
s.clear() # set() Empty Mathematical set operation
s1 = {1,2,3}
s2 = {2,3,4}
s1 & s2 # {2, 3} intersection
s1.intersection(s2) # {2, 3} intersection
s1.intersection_update(s2) # {2, 3} intersection , Will be covered s1
s1 | s2 # {1, 2, 3, 4} Combine
s1.union(s2) # {1, 2, 3, 4} Combine
s1.difference(s2) # {1} Difference set
s1.difference_update(s2) # {1} Difference set , Will be covered s1
s1.symmetric_difference(s2) # {1, 4} Beyond the intersection
s1.isdisjoint(s2) # False Is there no intersection
s1.issubset(s2) # False s2 whether s1 Subset
s1.issuperset(s2) # False s1 whether s2 Superset , namely s1 Does it include s2 All elements of Array generation
import numpy as np
np.arange(3)
# array([0, 1, 2])
np.arange(3.0)
# array([ 0., 1., 2.])
np.arange(3,7)
# array([3, 4, 5, 6])
np.arange(3,7,2)
# array([3, 5])
np.arange(3,4,.2)
# array([3. , 3.2, 3.4, 3.6, 3.8])
# Within interval isochronous data Specify the quantity
np.linspace(2.0, 3.0, num=5)
# array([2. , 2.25, 2.5 , 2.75, 3. ])
# Right open section ( Does not contain an R-value )
np.linspace(2.0, 3.0, num=5, endpoint=False)
# array([2. , 2.2, 2.4, 2.6, 2.8])
# ( Array , Spacing between samples )
np.linspace(2.0, 3.0, num=5, retstep=True)#(array([2. , 2.25, 2.5 , 2.75, 3. ]), 0.25)Is full of 0 or 1 Array
# Create value for 0 Array of
np.zeros(6)#6 Floating point 0. # Row vector
np.zeros((2,3,4),dtype=int)# Specify the shape of 0 matrix
np.ones((2,3,4)) # One matrix
np.empty((3,4)) # empty (0) matrix
# Of the same structure 0 matrix
np.arange(8).reshape(1,-1).shape #(1, 8)
np.arange(8).shape #(8,)
np.zeros_like(np.arange(8).reshape(-1,1))# Column matrices (8,1)
np.ones_like(np.arange(8).reshape(4,2))
np.empty_like(np.arange(8).reshape(2,2,2))Random array
np.random.randn(6,4)# Generate 6*4 The random matrix of , Standard normal distribution floating point
np.random.random(size=(6,4))# Generate 6*4 The random matrix of ,0-1 Evenly distributed floating point
np.random.randint(1,7,size=(6,4))# Specify range specify shape , Integers Common operations
a=np.linspace(2.0, 3.0, num=5) #array([2. , 2.25, 2.5 , 2.75, 3. ])
a.max()
a.min()
a.sum()
a.std()
a.all()
a.any()
a.cumsum() # Cumulative sum
np.sin(a)
np.log(a)Pandas There are two basic data structures , One is similar to Excel Two dimensional data frame of the table DataFrame, The second is a column of data frame , It's just a vector , It's called Series.
Data frame DataFrame Generate
import pandas as pd
df = pd.DataFrame({' Country ': [' China ', ' The United States ', ' Japan '],
' region ': [' Asia ', ' In North America ', ' Asia '],
' Population ': [14.33, 3.29, 1.26],
'GDP': [14.22, 21.34, 5.18],})
df
df2 = pd.DataFrame({'A': 1.,
'B': pd.Timestamp('20130102'),
'C': pd.Series(1, index=list(range(4)), dtype='float32'),
'D': np.array([3] * 4, dtype='int32'),
'E': pd.Categorical(["test", "train", "test", "train"]),
'F': 'foo'})
df2.B.dtype ##dtype('<M8[ns]')
df2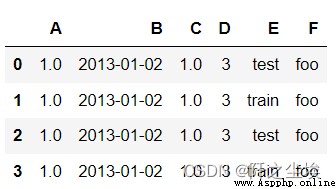
pd.DataFrame.from_dict({' Country ':[' China ',' The United States ',' Japan '],' Population ':[13.9,3.28,1.26]}) # Dictionary generation
pd.DataFrame.from_records([(' China ',' The United States ',' Japan '),(13.9,3.28,1.26)]).T # List array generation 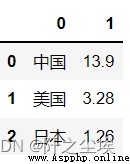
Series Common use
# The index is a、b.. , Five random floating-point arrays
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
s.index # Look at the index
s = pd.Series(np.random.randn(5)) # Index not specified
pd.Series(5., index=['a', 'b', 'c', 'd', 'e'])
s = pd.Series([1,2,3,4,5,6,7,8])
s[3] # Similar to list slicing
s[2:]
s.median() # Average , Including other mathematical functions
s[s > s.median()] # Filter content that is greater than the average
s[[1, 2, 1]] # Specify the contents of the index , The list in parentheses is the index
s.dtype # data type
s.array # Return the sequence of values
s.to_numpy() # To numpy Of ndarray
3 in s # Logical operations , Detect index
s.to_numpy()==s.values #[ True, True, True, True, True, True, True, True])s = pd.Series([1,2,3,4], name=' Numbers ')
s.add(1) # Add... To each element 1 abs()
s.add_prefix(3) # Add a before the index 3, expand digits 30,31,32,34
s.add_suffix(4) # ditto , Add after 04,14,24,34
s.sum() # The sum of the
s.count() # Number , length
s.agg('std') # polymerization , Return only the standard deviation , And s.std() identical
s.agg(['min', 'max']) # polymerization , Returns the maximum and minimum values
s2 = s.rename("number") # Modify name
s.align(s2) # join
s.any() # Whether it is false
s.all() # Is it all true
s.append(s2) # Add another Series
s.apply(lambda x:x+1) # Application method
s.empty # Is it empty
s3 = s.copy() # Deep copy Judgment type
pd.api.types.is_bool_dtype(s)
pd.api.types.is_categorical_dtype(s)
pd.api.types.is_datetime64_any_dtype(s)
pd.api.types.is_datetime64_ns_dtype(s)
pd.api.types.is_datetime64_dtype(s)
pd.api.types.is_float_dtype(s)
pd.api.types.is_int64_dtype(s)
pd.api.types.is_numeric_dtype(s)
pd.api.types.is_object_dtype(s)
pd.api.types.is_string_dtype(s)
pd.api.types.is_timedelta64_dtype(s)
pd.api.types.is_bool_dtype(s)pandas How to read data , section , Screening , Operations such as drawing will be introduced in detail in the following chapters